Добавление узлов смещения в нейронную сеть
В данной статье показано, как добавить значения смещения в многослойный перцептрон, реализованный на языке программирования высокого уровня, таком как Python.
Добро пожаловать в серию статей о нейронных сетях. Прежде чем вы перейдете к этой статье об узлах смещения, попробуйте наверстать упущенное в остальных статьях, которые можно увидеть выше, в меню с содержанием.
Узлы смещения, которые могут быть добавлены к входному или скрытому слою перцептрона, создают постоянное значение, которое выбирает разработчик.
Мы обсуждали значения смещения еще в 11-ой статье, и, если вам непонятно, что такое узлы смещения, или как они изменяют и потенциально улучшают функциональность нейронной сети, я советую вам прочитать (или перечитать) соответствующий фрагмент этой статьи.
В данной статье я сначала объясню два метода включения значений смещения в архитектуру нейросети, а затем мы проведем эксперимент, чтобы выяснить, могут ли значения смещения улучшить показатели точности, которые мы получили в предыдущей (в 16-ой) статье.
Включение смещения через электронную таблицу
Следующая диаграмма изображает нейросеть, у которой узел смещения находится во входном слое, а не в скрытом слое.
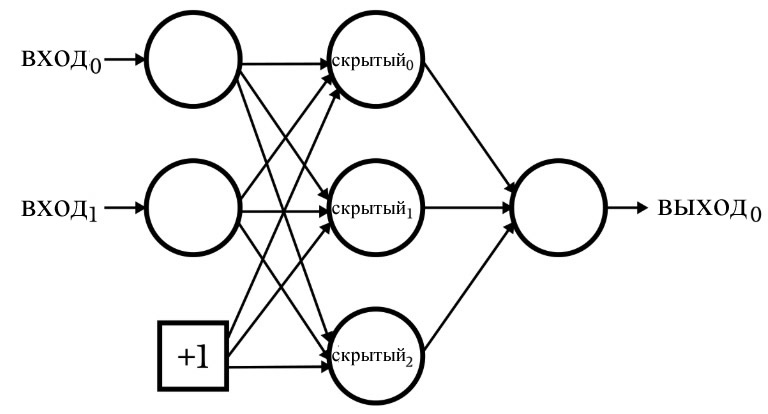 Рисунок 1 – Узел смещения во входном слое многослойного перцептрона
Рисунок 1 – Узел смещения во входном слое многослойного перцептрона
Если эта конфигурация – именно то, что вам нужно, то вы можете добавить значение смещения, используя электронную таблицу, содержащую ваши данные обучения или проверки.
Преимущество этого метода состоит в том, что не требуется никаких существенных изменений кода. Первым шагом является вставка столбца в таблицу и заполнение его значением смещения:
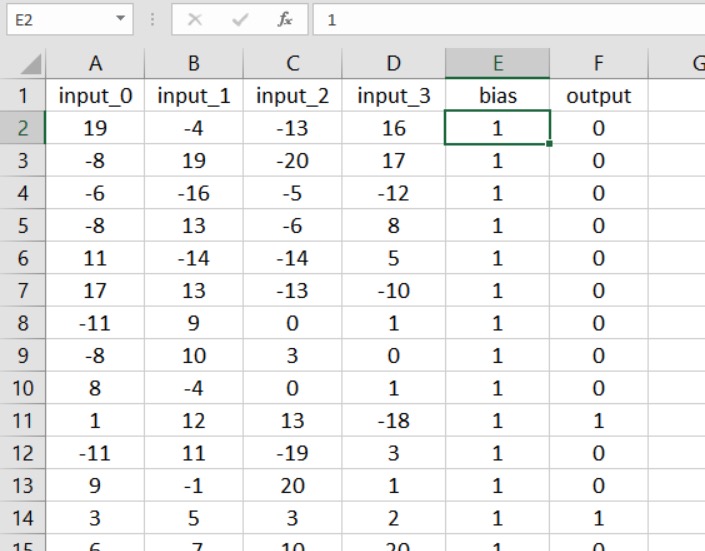 Рисунок 2 – Столбец смещения
Рисунок 2 – Столбец смещения
Теперь всё, что вам нужно сделать, – это увеличить размерность входного слоя на единицу:
Интеграция смещения в код
Если вам нужен узел смещения в скрытом слое или вам не нравится работать с электронными таблицами, вам понадобится другое решение.
Я сделаю это следующим образом:
Создание узла смещения во входном слое
Как вы помните, для сборки набора обучающих данных, разделения целевых выходных значений и извлечения количества обучающих выборок мы используем следующий код.
После этих операций количество столбцов в двумерном массиве training_data будет равно количеству входных столбцов в электронной таблице. Нам нужно увеличить количество столбцов на один, чтобы учесть узел смещения во входном слое, и пока мы это делаем, мы можем заполнить этот дополнительный столбец требуемым значением смещения.
Следующий код показывает, как это можно сделать.
Обратите внимание, что я выполнил эту процедуру как для данных обучения, так и для данных проверки. Важно помнить, что цель на самом деле состоит не в том, чтобы изменить данные обучения или проверки; скорее, мы модифицируем данные как средство реализации необходимой конфигурации сети.
Когда мы смотрим на блок-схему перцептрона, узлы смещения появляются в ней как элементы самой сети; таким образом, любые выборки, которые обрабатываются нейросетью, должны подвергаться этой модификации.
Создание узла смещения в скрытом слое
Первая модификация показана ниже:
Если, наоборот, мы решили включить узел смещения в скрытый слой, цикл for не будет вычислять значение постактивации для последнего узла в слое (то есть узла смещения).
Обратите внимание, что эти изменения должны быть применены и к проверочной части кода.
Значения смещения, отличающиеся от +1
По моему опыту, +1 – это стандартное значение смещения, и я не знаю, есть ли какое-либо веское обоснование для использования других чисел. Смещение изменяется весами, поэтому выбор +1 не накладывает жестких ограничений на то, как смещение взаимодействует с общим функционалом нейросети.
Тестирование влияния смещения
Если вы читали 16-ую статью, вы знаете, что моему перцептрону было трудно классифицировать выборки в эксперименте № 3, который был задачей «высокой сложности».
Давайте посмотрим, предлагает ли добавление одного или нескольких узлов смещения устойчивое и значительное улучшение.
Я предполагал, что различия в точности классификации будут довольно незначительными, поэтому в этом эксперименте я усреднил десять запусков вместо пяти. Наборы данных обучения и проверки были сгенерированы с использованием одной и той же связи высокой сложности между входом и выходом, а размерность скрытого слоя была равна 7.
| Средняя точность | Минимальная точность | Максимальная точность | |
|---|---|---|---|
| без смещения | 92,45% | 89,42% | 94,18% |
| смещение только во входном слое | 92,25% | 89,48% | 96,02% |
| смещение только в скрытом слое | 92,05% | 89,50% | 93,32% |
| смещение и во входном, и в скрытом слоях | 92,19% | 89,28% | 95,70% |
Заключение
Как видите, узлы смещения не привели к каким-либо значительным изменениям в эффективности классификации.
Это на самом деле меня не удивляет – я думаю, что узлы смещения иногда немного переоцениваются, и, учитывая природу входных данных, которые я использовал в этом эксперименте, я не вижу причин, почему узлы смещения могли бы помочь.
Тем не менее, смещение является важной техникой в некоторых приложениях; будет хорошей идеей, написать код, поддерживающий функциональность узлов смещения, чтобы они были там, когда вам понадобятся.
Какова роль смещения в нейронных сетях?
Я знаю о градиентном спуске и алгоритме обратного распространения. Чего я не понимаю, так это когда важно использовать предвзятость и как вы ее используете?
Например, при отображении AND функции, когда я использую 2 входа и 1 выход, она не дает правильных весов, однако, когда я использую 3 входа (1 из которых является смещением), она дает правильные веса.
Это может помочь взглянуть на простой пример. Рассмотрим эту сеть с 1 входом и 1 выходом, которая не имеет смещения:

Выход сети рассчитывается путем умножения входных данных (х) на вес (W 0 ) и передачи результата через некоторую функцию активации (например, сигмовидную функцию).
Вот функция, которую эта сеть вычисляет для различных значений w 0 :

Это именно то, что позволяет сделать уклон. Если мы добавим смещение в эту сеть, вот так:

. тогда выходной сигнал сети становится sig (w 0 * x + w 1 * 1.0). Вот как выглядит выход сети для различных значений w 1 :

Просто чтобы добавить мои два цента.
Более простой способ понять, что такое смещение: оно чем-то похоже на константу b линейной функции
Это позволяет вам перемещать линию вверх и вниз, чтобы лучше соответствовать прогнозу с данными. Без b линия всегда проходит через начало координат (0, 0), и вы можете получить худшее соответствие.
Эта тема действительно помогла мне разработать собственный проект. Вот еще несколько иллюстраций, показывающих результат простой двухслойной нейронной сети с прямой связью с блоками смещения и без нее в задаче регрессии с двумя переменными. Веса инициализируются случайным образом и используется стандартная активация ReLU. Как пришли к выводу ответы передо мной, без смещения ReLU-сеть не может отклоняться от нуля при (0,0).


Два разных вида параметров могут быть отрегулированы во время обучения ANN, весов и значений в функциях активации. Это нецелесообразно, и было бы проще, если бы был настроен только один из параметров. Чтобы справиться с этой проблемой, изобретен нейрон смещения. Смещающий нейрон лежит в одном слое, связан со всеми нейронами в следующем слое, но ни с одним на предыдущем слое, и он всегда излучает 1. Поскольку смещающий нейрон излучает 1, веса, связанные с нейроном смещения, добавляются непосредственно к объединенная сумма других весов (уравнение 2.1), как и значение t в функциях активации. 1
Кроме того, смещение позволяет использовать одну нейронную сеть для представления похожих случаев. Рассмотрим логическую функцию AND, представленную следующей нейронной сетью:
Один персептрон может использоваться для представления множества логических функций.
Уклон не является NN термин, это общий термин алгебры для рассмотрения.
Y = M*X + C (уравнение прямой)
Теперь, если C(Bias) = 0 тогда, линия всегда будет проходить через начало координат, т.е. (0,0) и зависит только от одного параметра, т.е. M Е. От наклона, поэтому у нас будет меньше вещей для игры.
В логистической регрессии ожидаемое значение цели преобразуется функцией связи, чтобы ограничить ее значение единичным интервалом. Таким образом, предсказания модели можно рассматривать как вероятности первичного исхода, как показано ниже: сигмоидальная функция в Википедии
Это последний активационный слой в карте NN, который включает и выключает нейрон. Здесь также играет роль смещение, и оно гибко смещает кривую, чтобы помочь нам отобразить модель.
Это означает, что вы используете линейную функцию и, следовательно, вход всех нулей всегда будет отображаться на выход всех нулей. Это может быть разумным решением для некоторых систем, но в целом оно слишком ограничительное.
Используя смещение, вы фактически добавляете другое измерение к своему входному пространству, которое всегда принимает значение, равное единице, поэтому вы избегаете входного вектора всех нулей. Вы не теряете общности из-за этого, потому что ваша обученная матрица веса не должна быть сюръективной, поэтому она все равно может отображать все возможные ранее значения.
2d ANN:
Для ANN, отображающего два измерения в одно измерение, например, при воспроизведении функций AND или OR (или XOR), вы можете думать о нейронной сети как о следующем:
Обратите внимание, что функция XOR в этой ситуации не может быть решена даже с предвзятым отношением.
Когда вы используете ANN, вы редко знаете о внутренностях систем, которые вы хотите изучить. Некоторые вещи не могут быть изучены без предвзятости. Например, взгляните на следующие данные: (0, 1), (1, 1), (2, 1), в основном функция, которая отображает любой x на 1.
Если у вас есть одноуровневая сеть (или линейное отображение), вы не сможете найти решение. Однако, если у вас есть предвзятость, это тривиально!
В идеальном случае смещение может также отобразить все точки на среднее значение целевых точек и позволить скрытым нейронам моделировать различия от этой точки.
Введение смещения нейронов позволяет смещать кривую передаточной функции по горизонтали (влево / вправо) вдоль входной оси, оставляя форму / кривизну без изменений. Это позволит сети создавать произвольные выходные данные, отличные от значений по умолчанию, и, следовательно, вы можете настроить / сместить отображение ввода-вывода в соответствии с вашими конкретными потребностями.
Просто добавить ко всему этому то, чего очень не хватает, а остальное, скорее всего, не знает.
Если вы работаете с изображениями, вы можете вообще не использовать смещение. Теоретически, таким образом ваша сеть будет более независимой от величины данных, например, будет ли изображение темным или ярким и ярким. И сеть научится выполнять свою работу, изучая относительность внутри ваших данных. Многие современные нейронные сети используют это.
В нескольких экспериментах в моей магистерской работе (например, на странице 59) я обнаружил, что смещение может быть важным для первого (ых) слоя (ов), но особенно в полностью связанных слоях в конце, похоже, оно не играет большой роли.
Это может сильно зависеть от сетевой архитектуры / набора данных.
Смещение решает, на какой угол вы хотите, чтобы ваш вес вращался.

Теперь нам нужно найти границу решения, граница идеи должна быть:

Видеть? W перпендикулярно нашей границе. Таким образом, мы говорим, что W решил направление границы.
Тем не менее, трудно найти правильный W в первый раз. В основном мы выбираем исходное значение W случайным образом. Таким образом, первая граница может быть такой: 
Теперь граница ближе к оси y.
Мы хотим повернуть границу, как?
Итак, мы используем функцию правила обучения: W ‘= W + P: 
W ‘= W + P эквивалентно W’ = W + bP, а b = 1.
Следовательно, изменяя значение b (смещение), вы можете выбрать угол между W ‘и W. Это «правило обучения ANN».
Вы также можете прочитать « Проект нейронной сети» Мартина Т. Хагана / Говарда Б. Демута / Марка Х. Била, глава 4 «Правило обучения перцептрона»
Если мы игнорируем смещение, многие входные данные могут быть представлены многими одинаковыми весами (то есть выученными весами). основном встречаются близко к началу координат (0,0). В этом случае модель будет ограничена меньшими количествами хороших весовых коэффициентов, вместо многих других хороших весов он мог бы лучше учиться с предвзятостью (где плохо изученные веса приводят к худшим догадкам или уменьшению способности угадывать нейронной сети)
Таким образом, оптимальным является то, что модель обучается как вблизи источника, так и в максимально возможном количестве мест внутри границы порога / решения. С предвзятостью мы можем предоставить степени свободы, близкие к источнику, но не ограничиваясь непосредственным регионом происхождения.
Ваша сеть пытается выучить коэффициенты a и b для адаптации к вашим данным. Итак, вы можете понять, почему добавление элемента b * 1 позволяет ему лучше соответствовать большему количеству данных: теперь вы можете изменить как наклон, так и перехват.
Если у вас есть более одного ввода, ваше уравнение будет выглядеть так:
Обратите внимание, что уравнение все еще описывает один нейрон, одну выходную сеть; если у вас больше нейронов, вы просто добавляете одно измерение в матрицу коэффициентов, чтобы мультиплексировать входы во все узлы и суммировать вклад каждого узла.
Что вы можете написать в векторизованном формате как
т.е., помещая коэффициенты в один массив и (входы + смещение) в другой, вы получаете желаемое решение в виде точечного произведения двух векторов (вам нужно переставить X, чтобы фигура была правильной, я написал XT как ‘X транспонированный’)
Таким образом, в конце вы также можете увидеть свое смещение как еще один вход для представления той части вывода, которая фактически не зависит от вашего ввода.
Роль смещения в нейронных сетях
Я знаю о градиентном спуске и теореме обратного распространения. Что я не понимаю: когда важно использовать предвзятость и как вы ее используете?
например, при отображении AND функция, когда я использую 2 входа и 1 выход, он не дает правильные веса, однако, когда я использую 3 входа (1 из которых является смещением), он дает правильные веса.
16 ответов
Я думаю, что предубеждения почти всегда полезны. В сущности,значение смещения позволяет смещать функцию активации влево или вправо, которые могут иметь решающее значение для успешного обучения.
Это может помочь взглянуть на простой пример. Рассмотрим эту 1-входную, 1-выходную сеть, которая не имеет смещения:
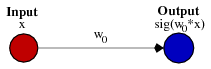
выход сети вычисляется путем умножения входного сигнала (x) на вес (w0) и прохождения результат через некоторую функцию активации (например, сигмовидную функцию.)
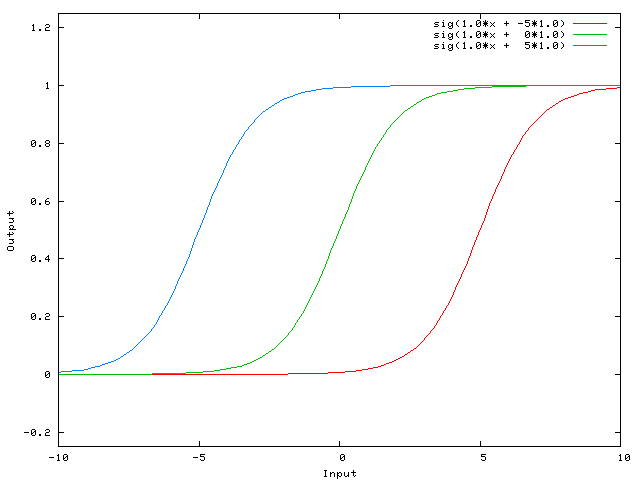
вот функция, которую вычисляет эта сеть, для различных значений w0:
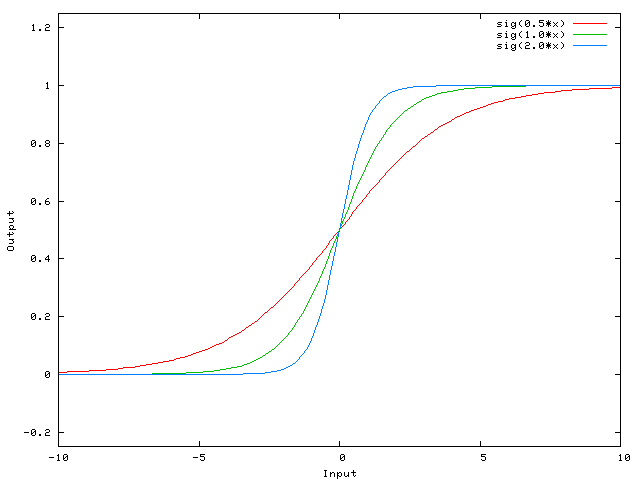
Это именно то, что позволяет вам делать смещение. Если мы добавим смещение к этой сети, например:
. тогда выход сети становится sig(w0 * x + w1*1.0). Вот как выглядит выход сети для различных значений w1:
просто добавить мои два цента.
более простой способ понять, что такое смещение: оно как-то похоже на константу b линейной функции
Это позволяет перемещать линию вверх и вниз, чтобы лучше соответствовать прогнозу с данными. Без b линия всегда проходит через начало координат (0, 0), и вы можете сделать более пригодный.
2 различных вида параметров могут отрегулируйте во время тренировки Энн, веса и значение в функция активации. Это непрактично и было бы легче, если бы только один из параметров должен быть отрегулированный. Чтобы справиться с этой проблемой изобретен нейрон смещения. Предвзятость нейрон лежит в одном слое, соединен всем нейронам в следующем слое, но нет в предыдущем слое и это всегда выдает 1. С момента смещения нейрона выдает 1 весы, связанные с нейрон смещения, добавлены сразу к совокупность других Весов (уравнение 2.1), Как и значение t в функциях активации.1
причина, по которой это непрактично, заключается в том, что вы одновременно регулируете вес и значение, поэтому любое изменение веса может нейтрализовать изменение значения, которое было полезно для предыдущего экземпляра данных. добавление нейрона смещения без изменения значения позволяет контролируйте поведение слоя.
кроме того, смещение позволяет использовать одну нейронную сеть для представления подобных случаев. Рассмотрим и булеву функцию, представленную следующей нейронной сетью:
одиночный персептрон можно использовать к представляют множество булевых функций.
перцептронов может представлять все примитивные булевы функции и, или, NAND (1 и), и NOR ( 1 или). Машинное Обучение-Том Митчелл)
Это означает, что вы используете линейную функцию и, таким образом, вход всех нулей всегда будет отображаться на выход всех нулей. Это может быть разумным решением для некоторых систем, но в целом это слишком ограничительный.
используя смещение, вы эффективно добавляете другое измерение к своему входному пространству, которое всегда принимает значение one, поэтому вы избегаете входного вектора всех нулей. Вы не теряете общности, потому что ваша обученная матрица веса не должна быть сюръективной, поэтому она все еще может сопоставляться со всеми ранее возможными значениями.
2d ANN:
для отображения ANN двух измерений в одно измерение, как при воспроизведении AND или OR (или XOR) функции, вы можете думать о нейронной сети, как делать следующее:
на 2d плоскости отметьте все позиции входных векторов. Так, для логических значений, вы захотите пометить (-1,-1), (1,1), (-1,1), (1,-1). Теперь ваша ANN рисует прямую линию на 2d-плоскости, отделяя положительные выходные данные от отрицательных выходных значений.
без смещения эта прямая линия должна пройти через ноль, тогда как с смещением вы можете поместить ее куда угодно. Итак, вы увидите, что без смещения вы сталкиваетесь с проблемой с функцией AND, так как вы не можете поставить оба (1,-1) и (-1,1) в отрицательную сторону. (Им не позволено быть on линии.) Проблема равна для функции OR. С уклоном, однако, легко провести черту.
обратите внимание, что функция XOR в этой ситуации не может быть решена даже с уклоном.
когда вы используете ANNs, вы редко знаете о внутренних системах, которые вы хотите узнать. Некоторые вещи нельзя узнать без предубеждения. Например, взгляните на следующие данные: (0, 1), (1, 1), (2, 1), в основном функция, которая отображает любой x в 1.
Если у вас есть однослойная сеть (или линейное отображение), вы не можете найти решение. Однако, если у вас есть предубеждение, это тривиально!
в идеальной обстановке смещение может также сопоставлять все точки со средним значением цели точки и пусть скрытые нейроны моделируют различия с этой точки.
смещение не NN термин, это общий термин алгебры для рассмотрения.
Сексизм и шовинизм искусственного интеллекта.
Почему так сложно его побороть?
Что такое «предвзятость искусственного интеллекта» (AI bias)? С чем связано возникновение этого явления и как с ним бороться? В материале, подготовленном специально для TAdviser, на эти вопросы отвечает журналист Леонид Черняк.

Причина столь высокого интереса к AI bias объясняется тем, что результаты внедрения технологий ИИ в ряде случаев задевают основные ценности современного общества. Они проявляются в нарушении таких важных принципов как расовое и гендерное равенства.
Возникают естественные вопросы – откуда взялась AI bias и что с этой предвзятостью делать? Справедливо допустить, что предвзятость ИИ не вызвана какими-то собственными свойствами моделей, а является прямым следствием двух других типов предвзятостей – хорошо известной когнитивной и менее известной алгоритмической. В процессе обучения сети они складываются в цепочку и в итоге возникает третье звено – AI bias.
Трехзвенная цепочка предвзятостей:
Начнем с когнитивных. Разработчики систем на принципах глубинного обучения, как и все остальные представители человеческой расы, являются носителями той или иной когнитивной пристрастности (cognitive bias). У каждого человека есть свой жизненный путь, накопленный опыт, поэтому он не в состоянии быть носителем абсолютной объективности. Индивидуальная пристрастность является неизбежной чертой любой личности. Психологи стали изучать когнитивную пристрастность как самостоятельное явление в семидесятых годах ХХ века, в отечественной психологической литературе ее принято называть когнитивным искажением.
Системы, построенные на принципах глубинного обучения в этом смысле не являются исключением, их разработчики не могут быть свободны от присущих им пристрастностей, поэтому с неизбежностью будут переносить часть своей личности в алгоритмы, порождая, в конечном итоге, AI bias. То есть AI bias не собственное свойство ИИ, о следствие переноса в системы качеств, присущих их авторам.
Существование алгоритмической пристрастности (Algorithmic bias) нельзя назвать открытием. Об угрозе возможного «заражения машины человеческими пристрастиями» много лет назад впервые задумался Джозеф Вейценбаум, более известный как автор первой способной вести диалог программы Элиза, написанной им в еще 1966 году. Название программы адресует нас к Элизе Дулиттл, героине «Пигмалиона» Бернарда Шоу. С ней Вейценбаум одним из первых предпринял попытку пройти тест Тьюринга, но он изначально задумывал Элизу как средство для демонстрации возможности имитационного диалога на самом поверхностном уровне. Это был академический розыгрыш высочайшего уровня. Совершенно неожиданно для себя он обнаружил, что к его «разговору с компьютером», в основе которого лежала примитивная пародия, основанная на принципах клиент-центрированной психотерапии Карла Роджерса, многие, в том числе и специалисты, отнеслись всерьез с далеко идущими выводами.
В современности мы называем такого рода технологии чат-ботами. Тем, кто верит в их интеллектуальность, стоит напомнить, что эти программы не умнее Элизы. Вейценбаум наряду с Хьюбертом Дрейфусом и Джоном Серлем вошел в историю ИИ как один из основных критиков утверждений о возможности создания искусственного мозга и тем более искусственного сознания, сравнимого с человеческим по своим возможностям. В переведенной на русский язык в 1982 году книге «Возможности вычислительных машин и человеческий разум» Вейценбаум предупреждал об ошибочности отождествления естественного и искусственного разума, основываясь на сравнительном анализе фундаментальных представлений психологии и на наличии принципиальных различий между человеческим мышлением и информационными процессами в компьютере. А возвращаясь к AI bias заметим, что более тридцати лет назад Вейценбаум писал о том, что предвзятость программы может быть следствием ошибочно использованных данных и особенностей кода этой самой программы. Если код не тривиален, скажем, не формула записанная на Fortran, то такой код так или иначе отражает представления программиста о внешнем мире, поэтому не следует слепо доверять машинным результатам.
А в далеко не тривиальных по своей сложности приложениях глубинного обучения алгоритмическая пристрастность тем более возможна. Она возникает в тех случаях, когда система отражает внутренние ценности ее авторов, на этапах кодирования, сбора и селекции данных, используемых для тренировки алгоритмов.
Алгоритмическая пристрастность возникает не только вследствие имеющихся культурных, социальных и институциональных представлений, но и из-за возможных технических ограничений. Существование алгоритмической предвзятости находится в противоречии с интуитивным представлением, а в некоторых случаях с мистической убежденностью в объективности результатов, полученных в результате обработки данных на компьютере.
Бороться с AI bias «в лоб» практически невозможно, в той же статье в MIT Review называются основные причины этого:
Какие же выводы можно сделать из факта существования феномена AI bias?
