Understanding CallBacks using Python Part 1

To start with, Callbacks are functions that are sent to another function as an argument. Lets straight away dive into code to understand the concept :
You can find the code in Github
We will start with simple_example.py from the above github. I will copy snippets from same below to explain the concept.
We have a function that iterates over 0–4 and add the square or each number in a variable “res”. It is slow because we have introduced a sleep of 1 sec in each iteration. Note the argument we take in “cb” which we will understand later is a callback that can be passed. For now we can call this function as
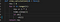
slow_calculation(), without any argument and you should see the output as 30.
We can just introduce a print statement in above function, or we can use callback “cb” in above function.

Now we can call slow_calculation(print_a_statement). Note that we are passing print_a_statement to slow_calculation, and not calling it. Thus we do not use parenthesis on print_a_statement. Another thing to note is that we passes *args and **kwargs in the function. This is to ensure that None or any number of arguments can be passed.
Now as cb is not None, it gets called which in return print_a_statement and the output is

Let’s now wish to print iteration number along with the above print statement. For this we need to modify the callback function as :

Now our base function can be called : slow_calculation(print_with_param).
and the callback itself takes a parameter that is iteration number in base function, which calls cb(i). Hence now we will get the output :

These are kind of tweaking that we can do from outside the base function. You will notice that we haven’t changed the base function slow_calculation for any of the customization we are doing. Lets move ahead with more requirement.
The code for below explanation is from more_callback.py file included in Github

Here show_progress_as_function takes in a argument for exclamation and the inner function has an argument iteration. The returned function has exclamation and iteration printed.
We can call our base function as :
Note this can be done in 2 steps:

Changing 2 argument function to 1 argument function is so common in python as we did above, that we have python library for this.

Above function accepts 2 arguments, but with the help of partial functionality in functool module we can change it to 1 argument function as below
from functool import partial
Thus now we can call base function as :

So we can see that having callback is a very sleek way of modifying the behavior and extracting independence from modifying base function for requirements.
Edit : There are few advanced steps in callback, such as having a class as a callback instead of function. I discuss that in part 2 of this blog here.
Please go through Part 2 for more on callbacks
Credit : This blog cannot end without thanking Jeremy Howard for the wonderful explanation on callback. He is the creator of Fastai library for deep learning.
Python 3.5; async/await
Тихо и незаметно (с), вышел Python версии 3.5! И, безусловно, одно из самых интересных нововведений релиза является новый синтаксис определения сопрограмм с помощью ключевых слов async/await, далее в статье об этом.
Поверхностный просмотр «PEP 0492 — Coroutines with async and await syntax» по началу оставил у меня вопрос «Зачем это надо». Сопрограммы удовлетворительно реализуются на расширенных генераторах и на первый взгляд может показаться, что все свелось к замене yield from на await, а декоратора, создающего сопрограмму на async. Сюда можно добавить и возникающее ощущение, что все это сделано исключительно для использования с модулем asyncio.
Но это, конечно же, не так, тема глубже и интереснее.
coroutine
Главное, наверное, это то, что теперь сопрограмма в Python — это специальный объект native coroutine, а не каким-то специальным образом оформленный генератор или еще что-то. Этот объект имеет методы и функции стандартной библиотеки для работы с ним. То есть теперь, это объект, определяемый как часть языка.
await
К сожалению, не нашел в документации и PEP краткое определение для чего введено это новое ключевое слово. Рискну сформулировать его сам: Ключевое слово await указывает, что при выполнении следующего за ним выражения возможно переключение с текущей сопрограммы на другую или на основной поток выполнения.
Соответственно выражение после await тоже не простое, это должен быть awaitable объект.
awaitable object
async
Примеры на использование асинхронных итераторов и контекст менеджеров в документации и PEP достаточно, usecase в общем-то понятен и все логично. Непонятно только одно — зачем использовать версии магических методов с другими именами, ведь они все равно объявляются с использованием `async def`. Видимо, это что-то, связанное с особенностями реализации, другого объяснения не вижу.
Как это готовить?
Изучение какой-то новой фичи языка или библиотеки быстро упирается в вопрос, как и где это использовать. И более глубокое изучение, на мой взгляд, стоит продолжать уже на практическом примере. Для меня, если тема связана с сопрограммами, асинхронностью и тому подобными вещами, такой практический пример — это написание хеллоуворда, использующего event-driven подход. Формулировка задачи такая: «Вызов функции sleep должен остановить исполнение сопрограммы на определенное время».
Сопрограммы и event-driven прекрасно сочетаются, в другой моей статье более подробно, почему я так считаю. И пример такого рода хорошо нам продемонстрирует почти все возможности и нюансы использования сопрограмм.
Развитие этой идеи: «async/await coroutine and event-driven», можно посмотреть по этой ссылке. Оно еще сырое, но кроме продемонстрированного переключения по событию «timeout», реализовано переключение сопрограмм по событиям «I/O ready» и «system sygnal». В качестве демо, есть пример асинхронного echo server.
Понимание callback-функций (колбеков)
Функции — это объекты
Чтобы понимать callback-функции, нужно понимать обычные функции. Это может показаться банальностью, но функции в Javascript’е — немного странные штуки.
Преимущество концепции «функция-как-объект» заключается в том, что код можно передавать в другую функцию точно так же, как обычную переменную или объект (потому что в буквальном понимании код — всего лишь объект).
Передача функции как callback-функции
Передавать функцию в качестве аргумента просто.
Может показаться глупостью создавать такой перемудрённый код, когда можно вернуть значение нормальным способом, но существуют ситуации, в которых это непрактично и callback-функции необходимы.
Не загромождайте выход
Традиционно функции в ходе выполнения принимают на вход аргументы и возвращают значение, используя выражение return (в идеальном случае единственное выражение return в конце функции: одна точка входа и одна точка выхода). Это имеет смысл. Функции — это, в сущности, маршруты между вводом и выводом.
Javascript даёт возможность делать всё немного по-другому. Вместо того чтобы дожидаться, пока функция закончит выполняться и вернёт значение, мы можем использовать callback-функции, чтобы получить его асинхронно. Это полезно для случаев, когда требуется много времени для завершения, например, при AJAX-запросах, ведь мы не можем приостановить браузер. Мы можем продолжить заниматься другими делами в ожидании вызова колбека. Фактически, очень часто от нас требуется (или, точнее, нам настоятельно рекомендуется) делать всё асинхронно в Javascript’е.
Вот более детальный пример, в котором используется AJAX для загрузки XML-файла и используется функция call() для вызова callback-функции в контексте запрошенного объекта (это значит, что когда мы укажем ключевое слово this внутри callback-функции, оно будет ссылаться на запрошенный объект):
В этом примере мы создаём объект httpRequest и загружаем файл XML. Типичная парадигма возвращения значения в конце функции тут больше не работает. Наш запрос обрабатывается асинхронно, а это означает, что мы начинаем запрос и говорим ему вызвать нашу функцию, как только он закончится.
Мы используем здесь две анонимных функции. Важно помнить, что нам бы не составило труда использовать и именованные функции, но во имя лаконичности мы сделали их вложенными. Первая анонимная функция выполняется всякий раз при изменении статуса в нашем объекте httpRequest. Мы игнорируем это до тех пор, пока состояние не будет равно 4 (т.е. запрос выполнен) и статус будет равен 200 (т.е. запрос выполнен успешно). В реальном мире вам бы захотелось проверить, не провален ли запрос, но мы предполагаем, что файл существует и может быть загружен браузером. Эта анонимная функция связана с httpRequest.onreadystatechange, так что она выполняется не сразу, а вызывается каждый раз при изменении состояния в нашем запросе.
Callback (программирование)
Callback (англ. call — вызов, англ. back — обратный) или фу́нкция обра́тного вы́зова в программировании — передача исполняемого кода в качестве одного из параметров другого кода. Обратный вызов позволяет в функции исполнять код, который задаётся в аргументах при её вызове. Этот код может быть определён в других контекстах программного кода и быть недоступным для прямого вызова из этой функции. Некоторые алгоритмические задачи в качестве своих входных данных имеют не только числа или объекты, но и действия (алгоритмы), которые естественным образом задаются как обратные вызовы.
Содержание
Применение
Концепция обратного вызова имеет много приложений. Например, некоторые алгоритмы (функции) в качестве подзадачи имеют задачу вычисления хеш-значения от строки. Какую именно функцию использовать для вычисления хеш-значений удобно задавать в аргументах при запуске алгоритма (функции).
Другой пример алгоритма, которому естественно передавать в аргументе функцию, — алгоритм обхода какого-либо хранилища объектов с применением некоторого действия к каждому объекту. Обратный вызов может выступать в роли этого действия (алгоритма).
Техника программирования обратного вызова в языках программирования, подобных языку Си, проста. При вызове основной функции ей просто передаётся указатель на функцию обратного вызова. Классическим примером является функция qsort из библиотеки stdlib. Эта функция позволяет отсортировать массив блоков байт одинаковой длины. В качестве аргументов она получает адрес первого элемента массива, количество блоков в массиве, размер блока байт, и указатель на функцию сравнения двух блоков байт. Эта функция сравнения и есть функция обратного вызова в данном примере:
Об обратном вызове можно думать как о действии, передаваемом некоторой основной процедуре в качестве аргумента. И это действие может рассматриваться как:
Показанный выше пример как раз соответствует первому случаю. Случай, когда обратный вызов используется как «телефонная связь», отражает код, где задаётся функция обработки определённого сигнала:
В некоторых языках программирования, таких как Common Lisp, Scheme, Clojure, Javascript, Perl, Python, Ruby и других, есть возможность конструировать анонимные (не именованные) функции и функции-замыкания прямо в выражении вызова основной функции, и эта возможность широко используется.
В технологии AJAX при выполнении асинхронного запроса к серверу необходимо указывать функцию обратного вызова, которая будет вызвана, как только придёт ответ на запрос. Часто эту функцию определяют «прямо на месте», не давая ей никакого определённого имени:
Функция обратного вызова используется также в шаблоне проектирования «Наблюдатель» (Observer). Так, например, используя библиотеку Prototype, можно создать «наблюдателя», который следит за нажатиями на элемент с идентификатором «my_button» и при получении события пишет сообщение внутрь элемента «message_box» :
Функция обратного вызова является альтернативой полиморфизму функций, а именно, позволяет создавать функции более общего назначения вместо того, чтобы создавать серию функций, одинаковых по структуре, но отличающихся лишь в отдельных местах исполняемыми подзадачами. Функции, принимающие в качестве аргументов другие функции или возвращающие функции в качестве результата, называют функциями высшего порядка. Техника обратного вызова играет важную роль для достижения повторного использования кода.
Зачем использовать функции обратного вызова
Для лучшего понимания причин использования обратного вызова рассмотрим простую задачу выполнения следующих операций над списком чисел: напечатать все числа, возвести все числа в квадрат, увеличить все числа на 1, обнулить все элементы. Ясно, что алгоритмы выполнения этих четырёх операций схожи — это цикл обхода всех элементов списка с некоторым действием в теле цикла, применяемый к каждому элементу. Это несложный код, и в принципе можно написать его 4 раза. Но давайте рассмотрим более сложный случай, когда список у нас хранится не в памяти, а на диске, и со списком могут работать несколько процессов одновременно и необходимо решать проблемы синхронизации доступа к элементам (несколько процессов могут выполнять разные задачи — удаления некоторых элементов из списка, добавления новых, изменение существующих элементов в списке). В этом случае задача обхода всех элементов списка будет довольно сложным кодом, который не хотелось бы копировать несколько раз. Правильнее создать функцию общего назначения для обхода элементов списка и дать возможность программистам абстрагироваться от того, как именно устроен алгоритм обхода и писать лишь функцию обратного вызова для обработки отдельного элемента списка.
Структурирование ПО
Структурирование программного обеспечения через функции обратного вызова — очень удобный и широко используемый подход, так как при этом поведение программы с неизменным (в том числе закрытым) кодом можно изменять в очень широких пределах. Это реализуется двумя путями — или «альтернативной реализацией» какой-либо функции, или «добавлением в цепочку вызовов» ещё одной функции.
Как правило, разработчик реализует через обратные вызовы не всю функциональность программы, а лишь ту, которую предполагается расширять или изменять плагинами. Для подключения плагинов предоставляется специальная процедура, которая и заменяет «стандартные» обратные функции от разработчика на альтернативные из плагина.
Самым известным примером такого подхода является операционная система Microsoft Windows, где функции обратного вызова именуются «handler» («обработчик»), и существует возможность вставить дополнительную процедуру между любыми двумя стандартными. Этот подход называется «перехват событий» и используется, например: антивирусами для проверки файлов, к которым производится обращение; вирусами для считывания вводимых с клавиатуры символов; сетевыми фильтрами для сбора статистики и блокирования пакетов.
В современных Unix и Linux системах существует возможность динамической загрузки и выгрузки модулей ядра, работа которых также основана на функциях обратного вызова. При этом существует модуль (расширение ядра) FUSE, который, в свою очередь, предоставляет возможность обычным пользовательским программам обслуживать (перехватывать) запросы к виртуальным файловым системам.
В программном обеспечении иногда встречается декомпозиция программ, полностью основанная на функциях обратного вызова, что несколько ухудшает читаемость кода, но даёт максимальные возможности для плагинов. Пример такого продукта — DokuWiki.
Достоинства и недостатки
18.5.4. Transports and protocols (callback based API)В¶
18.5.4.1. Transports¶
Transports are classes provided by asyncio in order to abstract various kinds of communication channels. You generally won’t instantiate a transport yourself; instead, you will call an AbstractEventLoop method which will create the transport and try to initiate the underlying communication channel, calling you back when it succeeds.
Once the communication channel is established, a transport is always paired with a protocol instance. The protocol can then call the transport’s methods for various purposes.
asyncio currently implements transports for TCP, UDP, SSL, and subprocess pipes. The methods available on a transport depend on the transport’s kind.
Changed in version 3.6: The socket option TCP_NODELAY is now set by default.
18.5.4.1.1. BaseTransport¶
Base class for transports.
Close the transport. If the transport has a buffer for outgoing data, buffered data will be flushed asynchronously. No more data will be received. After all buffered data is flushed, the protocol’s connection_lost() method will be called with None as its argument.
Return True if the transport is closing or is closed.
New in version 3.5.1.
Return optional transport information. name is a string representing the piece of transport-specific information to get, default is the value to return if the information doesn’t exist.
This method allows transport implementations to easily expose channel-specific information.
‘peername’ : the remote address to which the socket is connected, result of socket.socket.getpeername() ( None on error)
‘sockname’ : the socket’s own address, result of socket.socket.getsockname()
‘compression’ : the compression algorithm being used as a string, or None if the connection isn’t compressed; result of ssl.SSLSocket.compression()
‘cipher’ : a three-value tuple containing the name of the cipher being used, the version of the SSL protocol that defines its use, and the number of secret bits being used; result of ssl.SSLSocket.cipher()
‘peercert’ : peer certificate; result of ssl.SSLSocket.getpeercert()
Set a new protocol. Switching protocol should only be done when both protocols are documented to support the switch.
New in version 3.5.3.
Return the current protocol.
New in version 3.5.3.
Changed in version 3.5.1: ‘ssl_object’ info was added to SSL sockets.
18.5.4.1.2. ReadTransport¶
Interface for read-only transports.
Pause the receiving end of the transport. No data will be passed to the protocol’s data_received() method until resume_reading() is called.
Changed in version 3.6.7: The method is idempotent, i.e. it can be called when the transport is already paused or closed.
Resume the receiving end. The protocol’s data_received() method will be called once again if some data is available for reading.
Changed in version 3.6.7: The method is idempotent, i.e. it can be called when the transport is already reading.
18.5.4.1.3. WriteTransport¶
Interface for write-only transports.
Close the transport immediately, without waiting for pending operations to complete. Buffered data will be lost. No more data will be received. The protocol’s connection_lost() method will eventually be called with None as its argument.
Return the current size of the output buffer used by the transport.
Get the high— and low-water limits for write flow control. Return a tuple (low, high) where low and high are positive number of bytes.
New in version 3.4.2.
Set the high— and low-water limits for write flow control.
These two values (measured in number of bytes) control when the protocol’s pause_writing() and resume_writing() methods are called. If specified, the low-water limit must be less than or equal to the high-water limit. Neither high nor low can be negative.
pause_writing() is called when the buffer size becomes greater than or equal to the high value. If writing has been paused, resume_writing() is called when the buffer size becomes less than or equal to the low value.
The defaults are implementation-specific. If only the high-water limit is given, the low-water limit defaults to an implementation-specific value less than or equal to the high-water limit. Setting high to zero forces low to zero as well, and causes pause_writing() to be called whenever the buffer becomes non-empty. Setting low to zero causes resume_writing() to be called only once the buffer is empty. Use of zero for either limit is generally sub-optimal as it reduces opportunities for doing I/O and computation concurrently.
Write some data bytes to the transport.
This method does not block; it buffers the data and arranges for it to be sent out asynchronously.
Write a list (or any iterable) of data bytes to the transport. This is functionally equivalent to calling write() on each element yielded by the iterable, but may be implemented more efficiently.
Close the write end of the transport after flushing buffered data. Data may still be received.
This method can raise NotImplementedError if the transport (e.g. SSL) doesn’t support half-closes.
18.5.4.1.4. DatagramTransport¶
This method does not block; it buffers the data and arranges for it to be sent out asynchronously.
Close the transport immediately, without waiting for pending operations to complete. Buffered data will be lost. No more data will be received. The protocol’s connection_lost() method will eventually be called with None as its argument.
18.5.4.1.5. BaseSubprocessTransport¶
Return the subprocess process id as an integer.
Return the transport for the communication pipe corresponding to the integer file descriptor fd:
0 : readable streaming transport of the standard input (stdin), or None if the subprocess was not created with stdin=PIPE
1 : writable streaming transport of the standard output (stdout), or None if the subprocess was not created with stdout=PIPE
2 : writable streaming transport of the standard error (stderr), or None if the subprocess was not created with stderr=PIPE
Return the subprocess returncode as an integer or None if it hasn’t returned, similarly to the subprocess.Popen.returncode attribute.
On POSIX systems, this method sends SIGTERM to the subprocess. On Windows, the Windows API function TerminateProcess() is called to stop the subprocess.
Ask the subprocess to stop by calling the terminate() method if the subprocess hasn’t returned yet, and close transports of all pipes (stdin, stdout and stderr).
18.5.4.2. Protocols¶
asyncio provides base classes that you can subclass to implement your network protocols. Those classes are used in conjunction with transports (see below): the protocol parses incoming data and asks for the writing of outgoing data, while the transport is responsible for the actual I/O and buffering.
When subclassing a protocol class, it is recommended you override certain methods. Those methods are callbacks: they will be called by the transport on certain events (for example when some data is received); you shouldn’t call them yourself, unless you are implementing a transport.
All callbacks have default implementations, which are empty. Therefore, you only need to implement the callbacks for the events in which you are interested.
18.5.4.2.1. Protocol classes¶
The base class for implementing streaming protocols (for use with e.g. TCP and SSL transports).
class asyncio. DatagramProtocol В¶
The base class for implementing datagram protocols (for use with e.g. UDP transports).
class asyncio. SubprocessProtocol В¶
The base class for implementing protocols communicating with child processes (through a set of unidirectional pipes).
18.5.4.2.2. Connection callbacks¶
BaseProtocol. connection_made ( transport ) В¶
Called when a connection is made.
The transport argument is the transport representing the connection. You are responsible for storing it somewhere (e.g. as an attribute) if you need to.
BaseProtocol. connection_lost ( exc ) В¶
Called when the connection is lost or closed.
connection_made() and connection_lost() are called exactly once per successful connection. All other callbacks will be called between those two methods, which allows for easier resource management in your protocol implementation.
The following callbacks may be called only on SubprocessProtocol instances:
SubprocessProtocol. pipe_data_received ( fd, data ) В¶
Called when the child process writes data into its stdout or stderr pipe. fd is the integer file descriptor of the pipe. data is a non-empty bytes object containing the data.
SubprocessProtocol. pipe_connection_lost ( fd, exc ) В¶
Called when one of the pipes communicating with the child process is closed. fd is the integer file descriptor that was closed.
Called when the child process has exited.
18.5.4.2.3. Streaming protocols¶
The following callbacks are called on Protocol instances:
Protocol. data_received ( data ) В¶
Called when some data is received. data is a non-empty bytes object containing the incoming data.
Whether the data is buffered, chunked or reassembled depends on the transport. In general, you shouldn’t rely on specific semantics and instead make your parsing generic and flexible enough. However, data is always received in the correct order.
Some transports such as SSL don’t support half-closed connections, in which case returning true from this method will not prevent closing the connection.
data_received() can be called an arbitrary number of times during a connection. However, eof_received() is called at most once and, if called, data_received() won’t be called after it.
18.5.4.2.4. Datagram protocols¶
The following callbacks are called on DatagramProtocol instances.
DatagramProtocol. datagram_received ( data, addr ) В¶
Called when a datagram is received. data is a bytes object containing the incoming data. addr is the address of the peer sending the data; the exact format depends on the transport.
DatagramProtocol. error_received ( exc ) В¶
This method is called in rare conditions, when the transport (e.g. UDP) detects that a datagram couldn’t be delivered to its recipient. In many conditions though, undeliverable datagrams will be silently dropped.
18.5.4.2.5. Flow control callbacks¶
Called when the transport’s buffer goes over the high-water mark.
Called when the transport’s buffer drains below the low-water mark.
pause_writing() and resume_writing() calls are paired – pause_writing() is called once when the buffer goes strictly over the high-water mark (even if subsequent writes increases the buffer size even more), and eventually resume_writing() is called once when the buffer size reaches the low-water mark.
If the buffer size equals the high-water mark, pause_writing() is not called – it must go strictly over. Conversely, resume_writing() is called when the buffer size is equal or lower than the low-water mark. These end conditions are important to ensure that things go as expected when either mark is zero.
18.5.4.2.6. Coroutines and protocols¶
18.5.4.3. Protocol examples¶
18.5.4.3.1. TCP echo client protocol¶
TCP echo client using the AbstractEventLoop.create_connection() method, send data and wait until the connection is closed:
The event loop is running twice. The run_until_complete() method is preferred in this short example to raise an exception if the server is not listening, instead of having to write a short coroutine to handle the exception and stop the running loop. At run_until_complete() exit, the loop is no longer running, so there is no need to stop the loop in case of an error.
18.5.4.3.2. TCP echo server protocol¶
TCP echo server using the AbstractEventLoop.create_server() method, send back received data and close the connection:
Transport.close() can be called immediately after WriteTransport.write() even if data are not sent yet on the socket: both methods are asynchronous. yield from is not needed because these transport methods are not coroutines.
18.5.4.3.3. UDP echo client protocol¶
UDP echo client using the AbstractEventLoop.create_datagram_endpoint() method, send data and close the transport when we received the answer:
18.5.4.3.4. UDP echo server protocol¶
UDP echo server using the AbstractEventLoop.create_datagram_endpoint() method, send back received data:
18.5.4.3.5. Register an open socket to wait for data using a protocol¶
Wait until a socket receives data using the AbstractEventLoop.create_connection() method with a protocol, and then close the event loop
The watch a file descriptor for read events example uses the low-level AbstractEventLoop.add_reader() method to register the file descriptor of a socket.
The register an open socket to wait for data using streams example uses high-level streams created by the open_connection() function in a coroutine.
