Общие табличные выражения (CTE) стр. 1
Чтобы выяснить назначение общих табличных выражений, давайте начнем с примера.
Найти максимальную сумму прихода/расхода среди всех 4-х таблиц базы данных «Вторсырье», а также тип операции, дату и пункт приема, когда и где она была зафиксирована.
Задачу можно решить, например, следующим способом.
Здесь мы сначала объединяем всю имеющуюся информацию, а затем выбираем только те строки, у которых сумма не меньше, чем каждая из сумм той же выборки из 4-х таблиц.
Фактически, мы дважды написали код объединений четырех таблиц. Как избежать этого? Можно создать представление, а затем адресовать запрос уже к нему:
Так вот, CTE играет роль представления, которое создается в рамках одного запроса и, не сохраняется как объект схемы. Предыдущий вариант решения можно переписать с помощью CTE следующим образом:
Как видите, все аналогично использованию представления за исключением обязательных скобок, ограничивающих запрос; формально, достаточно лишь заменить CREATE VIEW на WITH. Как и для представления, в скобках после имени CTE может быть указан список столбцов, если нам потребуется включить их не все из подлежащего запроса и/или переименовать. Например, (я добавил дополнительно определение минимальной суммы в предыдущий запрос),
Общие табличные выражения позволяют существенно уменьшить объем кода, если многократно приходится обращаться к одним и тем же производным таблицам.
Конструкция WITH в T-SQL или обобщенное табличное выражение (ОТВ)
Всем привет! Тема сегодняшнего материала будет посвящена обобщенным табличным выражениям языка T-SQL, мы с Вами узнаем, что это такое, а также рассмотрим примеры написания запросов с использованием этих самых обобщённых табличных выражений.

Для начала, конечно же, давайте поговорим о том, что вообще из себя представляют обобщенные табличные выражения, какие они бывают, рассмотрим синтаксис, для чего их можно использовать и в заключение разберем несколько примеров.
Что такое обобщенное табличное выражение?
Common Table Expression (CTE) или обобщенное табличное выражение (OTB) – это временные результирующие наборы (т.е. результаты выполнения SQL запроса), которые не сохраняются в базе данных в виде объектов, но к ним можно обращаться.
Главной особенностью обобщенных табличных выражений является то, что с помощью них можно писать рекурсивные запросы, но об этом чуть ниже, а сейчас давайте поговорим о том, в каких случаях нам могут пригодиться OTB, в общем, для чего они предназначены:
Обобщенное табличное выражение определяется с помощью конструкции WITH, и определить его можно как в обычных запросах, так и в функциях, хранимых процедурах, триггерах и представлениях.
Синтаксис:
После обобщенного табличного выражения, т.е. сразу за ним должен идти одиночный запрос SELECT, INSERT, UPDATE, MERGE или DELETE.
Какие бывают обобщенные табличные выражения?
Они бывают простые и рекурсивные.
Простые не включают ссылки на самого себя, а рекурсивные соответственно включают.
Рекурсивные ОТВ используются для возвращения иерархических данных, например, классика жанра это отображение сотрудников в структуре организации (чуть ниже мы это рассмотрим).
Примечание! Все примеры ниже будут рассмотрены в MS SQL Server 2008 R2.
В качестве тестовых данных давайте использовать таблицу TestTable, которая будет содержать идентификатор сотрудника, его должность и идентификатор его начальника.
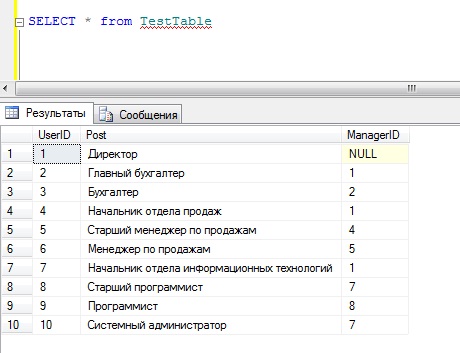
Как видите, у директора отсутствует ManagerID, так как у него нет начальника. А теперь переходим к примерам.
Пример простого обобщенного табличного выражения
Для примера давайте просто выведем все содержимое таблицы TestTable с использованием обобщенного табличного выражения
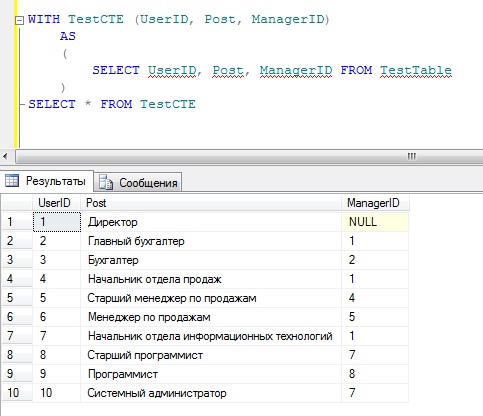
Где TestCTE это и есть псевдоним результирующего набора, к которому мы и обращаемся.
В данном случае мы могли и не перечислять имена столбцов, так как они у нас уникальны. Можно было просто написать вот так:
Пример рекурсивного обобщенного табличного выражения
Теперь допустим, что нам необходимо вывести иерархический список сотрудников, т.е. мы хотим видеть, на каком уровне работает тот или иной сотрудник. Для этого пишем рекурсивный запрос:
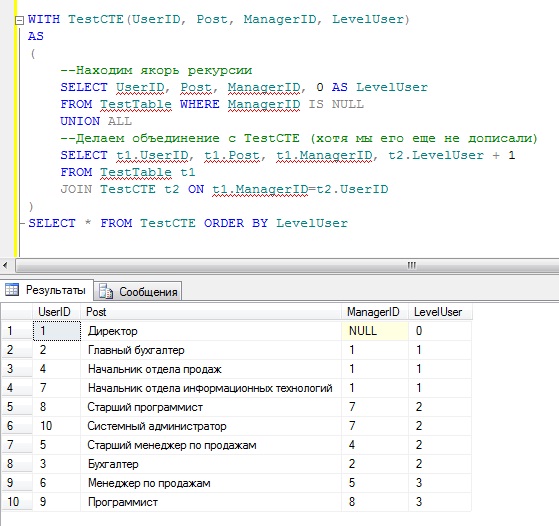
В итоге, если мы захотим, мы можем легко получить список сотрудников определенного уровня, например, нам нужны только начальники отделов, для этого мы просто в указанный выше запрос добавим условие WHERE LevelUser = 1
При написании рекурсивного ОТВ нужно быть внимательным, так как неправильное его составление может привести к бесконечному циклу. Поэтому для этих целей есть опция MAXRECURSION, которая может ограничивать количество уровней рекурсии. Давайте представим, что мы не уверены, что написали рекурсивное обобщенное выражение правильно и для отладки напишем инструкцию OPTION (MAXRECURSION 5), т.е. отобразим только 5 уровня рекурсии, и если уровней будет больше, SQL инструкция будет прервана.
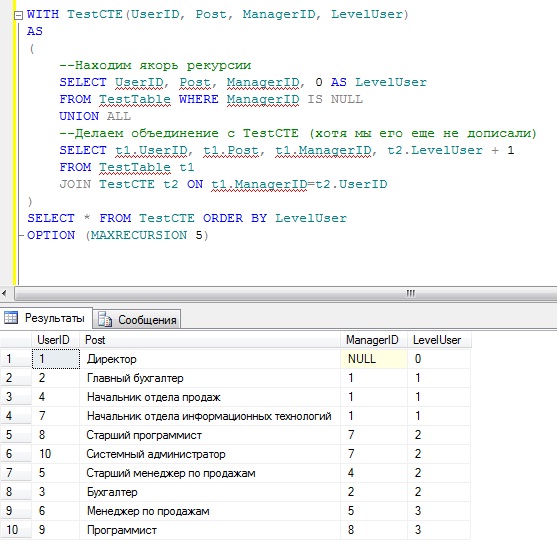
Запрос у нас отработал, что говорит о том, что мы написали его правильно и соответственно OPTION (MAXRECURSION 5) можно смело убрать.
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, в которых используется последовательная методика обучения специально для начинающих.
Common Table Expressions и деление таблиц на страницы
Common Table Expressions или по русский обобщенные табличные выражения – это технология, которая появилась в MS SQL Server 2005 и представляет собой одну из форм повторного использования результатов одного SQL запроса в другом.
В веб разработке довольно часто бывает нужно сделать выборку, разделить ее на страницы и отобразить строки таблицы, которые относятся к одной из страниц. Один из распространенных подходов заключается в том, что извлекается вся выборка, затем вычисляются номера строк, которые относятся к нужной нам странице и генерируется выходной html с нужными строками. Остальные данные не используются и извлекаются напрасно.
CTE позволяет увеличить эффективность такого извлечения данных. Суть в том, что обычно для определения какие строки требуются для отображения определенной страницы, нам нужны ключевое поле и поле, по которому выполняется сортировка, которое, впрочем, даже не всегда нужно извлекать. А для генерации страницы обычно нужно большее количество столбцов но небольшое количество строк. Выйгрыш происходит за счет того, что для определения строк определенной страницы мы используем маленький и быстрый некластерный индекс, а для извлечения строк одной страницы – кластерный индекс но с небольшим количеством строк.
Вот пример того, какой запрос использовался на моем форуме до оптимизации:
select * from forummessages where TopicID=310 order by messageid
при его выполнении было произведено 7815 логических чтений.
А вот пример запроса, использующего CTE
declare @pagenumber int, @pagesize int
set @pagesize=20
set @pagenumber=10
;with rowpaging
as
(select ROW_NUMBER() over(order by messageid) as rn,messageid from forummessages where TopicID=310)
select * from ForumMessages as m JOIN rowpaging as r ON m.MessageID=r.MessageID
where rn between @pagesize*(@pagenumber-1)+1 and @pagesize*@pagenumber
order by m.messageid
при его выполнении было произведено 68 логических чтений.
В итоге производительность извлечения данных для отображения одной страницы увеличилось почти в 115 раз и при этом не нужно в программном коде вычислять, какие строки относятся к нужной странице.
UPD:
Давайте рассмотрим, как работает запрос на LINQ с использованием методов Skip() и Take().
Вот пример кода на linq для извлечения тех же 10 строк:
DBM dbm = new DBM();
var items = (from m in dbm.Context.ForumMessages
where m.TopicID == 310
orderby m.MessageID
select m).Skip(200).Take(10);
string r = «»;
foreach (var x in items)
<
r += x.Body;
и вот то что выполняется на SQL Server (отловлено при помощи SQL Profile)
SELECT TOP (10)
[Filter1].[MessageID] AS [MessageID],
[Filter1].[TopicID] AS [TopicID],
[Filter1].[UserID] AS [UserID],
[Filter1].[Body] AS [Body],
[Filter1].[CreationDate] AS [CreationDate],
[Filter1].[Visible] AS [Visible],
[Filter1].[IPAddress] AS [IPAddress],
[Filter1].[Rating] AS [Rating],
[Filter1].[Deleted] AS [Deleted],
[Filter1].[WhoDelete] AS [WhoDelete]
FROM ( SELECT [Extent1].[MessageID] AS [MessageID], [Extent1].[TopicID] AS [TopicID], [Extent1].[UserID] AS [UserID], [Extent1].[Body] AS [Body], [Extent1].[CreationDate] AS [CreationDate], [Extent1].[Visible] AS [Visible], [Extent1].[IPAddress] AS [IPAddress], [Extent1].[Rating] AS [Rating], [Extent1].[Deleted] AS [Deleted], [Extent1].[WhoDelete] AS [WhoDelete], row_number() OVER (ORDER BY [Extent1].[MessageID] ASC) AS [row_number]
FROM [dbo].[ForumMessages] AS [Extent1]
WHERE 310 = [Extent1].[TopicID]
) AS [Filter1]
WHERE [Filter1].[row_number] > 200
ORDER BY [Filter1].[MessageID] ASC
В результате выполнения этого запроса мы получаем 4889 логических чтений, что почти в 72 раза больше чем в случае использования CTE и в полтора раза меньше чем извлечение всех строк выборки, неразделенной на страницы.
Применение оконных функций и CTE в MySQL 8.0 для реализации накопительного итога без хаков

Прим. перев.: в этой статье тимлид британской компании Ticketsolve делится решением своей весьма специфичной проблемы, демонстрируя при этом общие подходы к созданию так называемых accumulating (накопительных) функций с помощью современных возможностей MySQL 8.0. Его листинги наглядны и снабжены подробными объяснениями, что помогает вникнуть в суть проблематики даже тем, кто не погружался в неё столь глубоко.
Этот паттерн плохо работает с оптимизатором (приводя к недетерминированному поведению), поэтому от него решили отказаться. В результате возникла некая пустота, поскольку (относительно) комплексную логику теперь сложнее реализовать (по крайней мере, с той же простотой).
В статье пойдет речь о двух способах ее реализации: с использованием оконных функций (канонический подход) и с помощью рекурсивных СТЕ (общих табличных выражений).
Требования и предыстория
Хотя СТЕ достаточно интуитивно понятны, тем, кто не очень хорошо знаком с ними, я рекомендую обратиться к моей предыдущей публикации на эту тему.
То же самое справедливо и для оконных функций: я буду подробно комментировать запросы/концепции, но общее представление все же не помешает. Оконным функциям посвящено огромное количество книг и публикаций (именно поэтому я до сих пор не писал о них); при этом в большинстве примеров вычисления проводятся либо на финансовых результатах, либо на демографических показателях. Однако в данной статье я буду использовать реальный случай.
В мире ПО существует известная архитектурная дилемма: реализовывать логику на уровне приложения или на уровне базы данных? Хотя это вполне уместный вопрос, в нашем случае я исхожу из предположения, что логика должна остаться на уровне базы; причиной для этого могут быть, например, требования к скорости (как и было в нашем случае).
Задача
В этой задаче мы распределяем места в некоем зале (театральном).
Для целей бизнеса требуется каждому месту присваивать так называемую «группировку» (grouping) — дополнительный номер, представляющий его.
Вот алгоритм определения значения группировки:
В реальной жизни нам нужно, чтобы конфигурация слева давала значения, приведенные справа:
Подготовка
Пусть базовая таблица имеет следующее минималистское строение:
Основываясь на диаграмме выше, координаты каждого места имеют вид (y, x):
Следует загрузить достаточно большое количество записей, чтобы помешать оптимизатору «найти» неожиданные короткие пути. Конечно, мы используем рекурсивные СТЕ:
Старый подход
Старый добрый подход весьма прямолинеен и незамысловат:
Что ж, это было легко (но не забывайте о предупреждениях)!
Небольшое отступление: в данном случае я пользуюсь свойствами булевой арифметики. Следующие выражения эквивалентны:
Некоторые находят это интуитивно понятным, другие — нет; тут дело вкуса. Дальше я буду использовать более компактное выражение.
Давайте посмотрим на результат:
Увы, у него есть «незначительный» недостаток: он прекрасно работает за исключением тех случаев, когда не работает…
Все дело в том, что оптимизатор запросов вовсе не обязательно проводит вычисления слева направо, поэтому операции присваивания (:=) могут выполняться в неверном порядке, приводя к неправильному результату. С подобной проблемой люди часто сталкиваются после обновления MySQL.
В MySQL 8.0 этот функционал действительно признан устаревшим:
Что ж, давайте исправим ситуацию!
Современный подход №1: оконные функции
Появление оконных функций было весьма долгожданным событием в мире MySQL.
Вообще говоря, «скользящая» природа оконных функций отлично сочетается с накопительными функциями. Однако некоторые сложные накопительные функции требуют наличия результатов последнего выражения — функциональность, которую оконные функции не поддерживают, поскольку работают на столбцах.
Это не означает, что проблему нельзя решить: просто ее необходимо переосмыслить.
В нашем случае можно разделить задачу на две части. Группировку для каждого места можно считать как сумму двух значений:
Порядковый номер каждого места — это встроенная функция:
А вот с совокупным значением все гораздо интереснее… Чтобы его вычислить, мы выполняем два действия:
(Обратите внимание, что с настоящего момента я опускаю UPDATE ради простоты).
Давайте проанализируем запрос.
Высокоуровневая логика
Следующее CTE (отредактировано):
… вычисляет приращения для каждого места по сравнению с предыдущим (подробнее о LAG() — позже). Он работает на каждой записи и той, которая ей предшествует, и не является кумулятивным.
Теперь, чтобы подсчитать кумулятивные приращения, мы просто воспользуемся оконной функцией для вычисления суммы до каждого места и включая его:
Оконная функция LAG()
Функция LAG в своей простейшей форме ( LAG(x) ) возвращает предыдущее значение заданного столбца. Классическое неудобство с такими функциями — обработка первой(-ых) записи(-ей) в окне. Поскольку предыдущей записи нет, они возвращают NULL. В случае LAG можно указать нужное значение как третий параметр:
Указывая значения по умолчанию, мы гарантируем, что к самому первому месту в границах окна будет применяться та же логика, что и для места, следующего за другим (х-1) и без смены ряда (у).
Второй параметр в LAG() — это число позиций, на которые надо сдвигаться назад в рамках окна; 1 — это предыдущее значение (оно также установлено по умолчанию).
Технические аспекты
Именованные окна
В нашем запросе много раз используется одно и то же окно. Следующие два запроса формально эквивалентны:
Однако второй может повлечь неоптимальное поведение (с чем я сталкивался — по крайней мере, в прошлом): оптимизатор может посчитать окна независимыми и отдельно высчитывать каждое. По этой причине я советую всегда использовать именованные окна (по крайней мере, когда они повторяются).
Оператор PARTITION BY
Обычно оконные функции выполняются на партиции. В нашем случае это будет выглядеть следующим образом:
Поскольку окно соответствует полному набору записей (который фильтруется условием WHERE ), нам не нужно указывать ее (партицию).
Сортировка
В запросе ORDER BY задается на уровне окна:
При этом оконная сортировка идет отдельно от SELECT. Это очень важно! Поведение этого запроса:
… не определено. Давайте обратимся к руководству:
Строки результата запроса определяются из выражения FROM после выполнения операторов WHERE, GROUP BY и HAVING, а выполнение в рамках окна происходит до ORDER BY, LIMIT и SELECT DISTINCT.
Некоторые соображения
Если говорить в общих чертах, для решения задач подобного типа имеет смысл рассчитывать изменение состояния для каждой записи, а затем их суммировать — вместо того, чтобы представлять каждую запись как функцию предыдущей.
Это решение более сложное, чем функционал, который оно заменяет, но в то же время надежное. Увы, этот подход не всегда возможен или легко реализуем. Именно здесь в игру вступают рекурсивные СТЕ.
Современный подход №2: рекурсивные CTE
Этот подход требует небольших хитростей из-за ограниченных возможностей СТЕ в MySQL. С другой стороны, это универсальное, прямое решение, поэтому оно не требует какого-либо переосмысления глобального подхода.
Давайте начнем с упрощенной версии конечного запроса:
Бинго! Этот запрос (относительно) прост, но, что более важно, он выражает накопительную функцию группировки самым простым возможным образом:
Логика понятна даже для тех, кто не слишком знаком с СТЕ. Первый ряд — это первое место в зале, по порядку:
В рекурсивной части мы проводим итерацию:
Часть s.venue_id в выражении сортировки очень важна! Она позволяет нам использовать индекс.
JOIN формально является перекрестным, однако из-за оператора LIMIT возвращается только одна запись.
Рабочая версия
К сожалению, приведенный выше запрос не работает, поскольку ORDER BY в настоящее время не поддерживается в рекурсивных подзапросах. Кроме того, семантика LIMIT в том виде, в котором он используется здесь, отличается от типичной, которая применяется к внешнему запросу:
LIMIT теперь поддерживается [..] Воздействие на итоговый набор данных такое же, как при использовании LIMIT с внешним SELECT
Впрочем, это не такая уж серьезная проблема. Давайте взглянем на работающую версию:
Немного некомфортно использовать подзапрос, но данный подход работает и boilerplate здесь минимален, так как в любом случае требуется несколько выражений.
Размышления о производительности
Давайте изучим план выполнения запроса с помощью EXPLAIN ANALYZE:
План вполне соответствует ожиданиям. В данном случае основа оптимального плана кроется в индексных поисках:
… имеющих первостепенное значение. Скорость работы значительно упадет, если производить сканирование индексов (то есть линейно сканировать записи индекса вместо того, чтобы искать сразу нужные).
Таким образом, чтобы эта стратегия работала, необходимо, чтобы связанные индексы были на месте и максимально эффективно использовались оптимизатором.
Если в будущем ограничения будут сняты, то отпадет и необходимость использовать подзапрос, что значительно упростит задачу для оптимизатора.
Альтернатива для неоптимальных планов
В случае, если оптимальный план невозможно определить, используйте временную таблицу:
Даже если в этом запросе проходят индексные сканы, они обходятся «малой кровью», поскольку таблица selected_seats очень мала.
Заключение
Я очень доволен тем, что эффективный, но в то же время имеющий определенные недостатки рабочий процесс теперь можно заменить достаточно простым функционалом, появившимися в MySQL 8.0.
Тем временем, развитие новых фич для 8.0 продолжается, что делает и без того удачный релиз ещё лучше.
WITH обобщенное_табличное_выражение (Transact-SQL)
Задается временно именованный результирующий набор, называемый обобщенным табличным выражением (ОТВ). Он получается при выполнении простого запроса и определяется в области выполнения одиночной инструкции SELECT, INSERT, UPDATE, DELETE или MERGE. Это предложение может использоваться также в инструкции CREATE VIEW как часть определяющей ее инструкции SELECT. Обобщенное табличное выражение может включать ссылки на само себя. Такое выражение называется рекурсивным обобщенным табличным выражением.
 Синтаксические обозначения в Transact-SQL
Синтаксические обозначения в Transact-SQL
Синтаксис
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
column_name
Задается имя столбца в обобщенном табличном выражении. Повторяющиеся имена в определении одного обобщенного табличного выражения не допускаются. Количество заданных имен столбцов должно совпадать с количеством столбцов в результирующем наборе CTE_query_definition. Список имен столбцов необязателен только в том случае, если всем результирующим столбцам в определении запроса присвоены уникальные имена.
CTE_query_definition
Задается инструкция SELECT, результирующий набор которой заполняет обобщенное табличное выражение. Инструкция SELECT для CTE_query_definition должна соответствовать таким же требованиям, что и при создании представления, за исключением того, что обобщенное табличное выражение (ОТВ) не может определять другое ОТВ. Дополнительные сведения см. в подразделе «Замечания» и разделе CREATE VIEW (Transact-SQL).
Если определено несколько параметров CTE_query_definition, определения запроса должны быть соединены одним из следующих операторов над множествами: UNION ALL, UNION, EXCEPT или INTERSECT.
Remarks
Рекомендации по созданию и использованию обобщенных табличных выражений
Следующие рекомендации относятся к нерекурсивным обобщенным табличным выражениям. Рекомендации, применимые к рекурсивным обобщенным табличным выражениям, см. в расположенном ниже разделе Рекомендации по определению и использованию рекурсивных обобщенных табличных выражений.
Задание в одном обобщенном табличном выражении нескольких предложений WITH недопустимо. Например, если CTE_query_definition содержит вложенный запрос, этот вложенный запрос не может содержать вложенное предложение WITH, определяющее другое обобщенное табличное выражение.
Следующие предложения не могут использоваться в CTE_query_definition:
ORDER BY (за исключением случаев задания предложения TOP )
Предложение OPTION с указаниями запроса
Если обобщенное табличное выражение используется в инструкции, являющейся частью пакета, то за инструкцией, стоящей перед ней, должен следовать символ точки с запятой.
Запрос, ссылающийся на обобщенное табличное выражение, может использоваться для определения курсора.
В обобщенном табличном выражении могут быть ссылки на таблицы, находящиеся на удаленных серверах.
При выполнении обобщенного табличного выражения (ОТВ) между указаниями, ссылающимися на ОТВ, может быть конфликт с другими указаниями, обнаруживаемыми, когда ОТВ обращаются к их базовым таблицам, так же, как если бы указания ссылались на представления в запросах. Когда это происходит, запрос возвращает ошибку.
Рекомендации по созданию и использованию рекурсивных обобщенных табличных выражений
Следующие рекомендации применимы к определению рекурсивных обобщенных табличных выражений.
Определение рекурсивного обобщенного табличного выражения должно содержать по крайней мере два определения обобщенного табличного выражения запросов — закрепленный элемент и рекурсивный элемент. Может быть определено несколько закрепленных элементов и рекурсивных элементов, однако все определения запросов закрепленного элемента должны быть поставлены перед первым определением рекурсивного элемента. Все определения обобщенных табличных выражений запросов (ОТВ) являются закрепленными элементами, если только они не ссылаются на само ОТВ.
Закрепленные элементы должны объединяться одним из следующих операторов над множествами: UNION ALL, UNION, INTERSECT или EXCEPT. UNION ALL является единственным оператором над множествами, который может находиться между последним закрепленным элементом и первым рекурсивным элементом, а также может применяться при объединении нескольких рекурсивных элементов.
Количество столбцов членов указателя и рекурсивных элементов должно совпадать.
Тип данных столбца в рекурсивном элементе должен совпадать с типом данных соответствующего столбца в закрепленном элементе.
Предложение FROM рекурсивного элемента должно ссылаться на обобщенное табличное выражение expression_name только один раз.
Следующие элементы недопустимы в определении CTE_query_definition рекурсивного элемента:
PIVOT (Если уровень совместимости базы данных имеет значение 110 или больше. См. раздел Критические изменения в функциях компонента ядра СУБД в SQL Server 2016).
Указание, применимое к рекурсивной ссылке на обобщенное табличное выражение в определении CTE_query_definition.
Следующие рекомендации применимы к использованию рекурсивных обобщенных табличных выражений.
Представление, содержащее рекурсивное обобщенное табличное выражение, не может использоваться для обновления данных.
Курсоры могут определяться на запросах при помощи обобщенных табличных выражений. Обобщенное табличное выражение является аргументом select_statement, который определяет результирующий набор курсора. Для рекурсивных обобщенных табличных выражений допустимы только однонаправленные и статические курсоры (курсоры моментального снимка). Если в рекурсивном обобщенном табличном выражении указан курсор другого типа, тип курсора преобразуется в статический.
Возможности и ограничения общих табличных выражений в Azure Synapse Analytics и Система платформы аналитики (PDW)
Текущая реализация обобщенных табличных выражений в Azure Synapse Analytics и Система платформы аналитики (PDW) имеет следующие возможности и ограничения:
Обобщенное табличное выражение можно задать в инструкции CREATE TABLE AS SELECT (CTAS).
Обобщенное табличное выражение можно задать в инструкции CREATE REMOTE TABLE AS SELECT (CRTAS).
Обобщенное табличное выражение можно задать в инструкции CREATE EXTERNAL TABLE AS SELECT (CETAS).
Обобщенное табличное выражение может ссылаться на внешнюю таблицу.
Обобщенное табличное выражение может ссылаться на внешнюю таблицу.
В обобщенном табличном выражении можно задать несколько определений запросов обобщенных табличных выражений (ОТВ).
Обобщенное табличное выражение, которое включает ссылки на себя (рекурсивное обобщенное табличное выражение), не поддерживается.
Если обобщенное табличное выражение используется в инструкции, являющейся частью пакета, то за инструкцией, стоящей перед ней, должен следовать символ точки с запятой.
Примеры
A. Создание простого обобщенного табличного выражения
В следующем примере выводится общее количество заказов на продажу в год для каждого коммерческого представителя в Компания Adventure Works Cycles.
Б. Использование обобщенного табличного выражения для ограничения общего и среднего количества отчетов
В следующем примере выводится среднее количество заказов на продажу за все годы для коммерческих представителей.
В. Использование нескольких определений ОТВ (обобщенных табличных выражений) в одном запросе
В следующем примере показано, как определить несколько ОТВ в одном запросе. Обратите внимание, что для разделения определений запросов обобщенных табличных выражений используется запятая. Функция FORMAT, используемая для отображения денежных сумм в формате валюты, доступна в SQL Server 2012 и более поздних версиях.
Здесь приводится частичный результирующий набор.
Г. Использование рекурсивного обобщенного табличного выражения для отображения нескольких уровней рекурсии
Использование рекурсивного обобщенного табличного выражения для отображения двух уровней рекурсии
В следующем примере представлены руководители и отчитывающиеся перед ними служащие. Количество возвращаемых уровней ограничено двумя.
Использование рекурсивного обобщенного табличного выражения для отображения иерархического списка
В следующем примере добавляются имена руководителя и сотрудников, а также соответствующие им должности. Иерархия руководителей и служащих дополнительно выделяется с помощью соответствующих отступов на каждом уровне.
Использование подсказки MAXRECURSION для отмены инструкции
Подсказка MAXRECURSION может использоваться для предотвращения входа в бесконечный цикл из-за неверно сформированного рекурсивного CTE-выражения. В следующем примере преднамеренно формируется бесконечный цикл и используется указание MAXRECURSION для ограничения числа уровней рекурсии двумя.
После исправления ошибки в коде подсказка MAXRECURSION больше не нужна. В следующем примере приводится правильный код.
Д. Использование обобщенного табличного выражения для выборочного прохождения рекурсивной связи в инструкции SELECT
Е. Использование рекурсивного обобщенного табличного выражения в инструкции UPDATE
З. Использование нескольких привязок и рекурсивных элементов
В следующем примере несколько членов указателя и рекурсивных элементов используются для возврата всех предков указанного лица. Создается и заполняется значениями таблица для формирования генеалогии семьи, возвращаемой рекурсивным обобщенным табличным выражением.
I. Использование аналитических функций в рекурсивном обобщенном табличном выражении
Следующий пример демонстрирует проблему, которая может возникнуть при использовании аналитической или агрегатной функции в рекурсивной части обобщенного табличного выражения.
Следующие результаты являются ожидаемыми результатами выполнения запроса.
Следующие результаты являются фактическими результатами выполнения запроса.
N возвращает 1 для каждого прохода рекурсивной части ОТВ, так как в ROWNUMBER передается только подмножество данных для данного уровня рекурсии. Для каждой итерации рекурсивной части запроса в ROWNUMBER передается только одна строка.
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
К. Использование обобщенного табличного выражения в инструкции CTAS
В следующем примере создается новая таблица, содержащая общее количество заказов на продажу в год для каждого коммерческого представителя в Компания Adventure Works Cycles.
Л. Использование обобщенного табличного выражения в инструкции CETAS
В следующем примере создается новая внешняя таблица, содержащая общее количество заказов на продажу в год для каждого коммерческого представителя в Компания Adventure Works Cycles.
М. Использование нескольких разделенных запятыми обобщенных табличных выражений в инструкции
В следующем примере показано включение двух обобщенных табличных выражений в одну инструкцию. Обобщенные табличные выражения не поддерживают вложение (рекурсию).
