Память Андроид: очистить кэш и данные приложений

Содержание статьи:
Накопитель заполнен на 75%. Перенести данные на SD-карту

О чём говорит это предупреждение? В данном случае система предупреждает, что на внутренней памяти устройства осталось меньше 25% свободного пространства. По большому счёту, это не критическая ошибка, доступная память ещё в наличии, но нужно иметь ввиду два момента:
В статье Память на Android. Все разделы памяти Андроид устройств мы подробно останавливались на разборе всех типов памяти Android OS. Там же приводилась следующая строчка:
Если с удалением медиафайлов и документов всё более или менее понятно, то вопрос оптимизации памяти, занимаемой приложениями, рассмотрим подробнее.
Из чего состоят приложения на Андроид
В первую очередь, стоит указать, что каждое Андроид приложение условно можно разделить на три части по типу используемых файлов:
Удаление приложения на Андроид

Содержимое папки с программой в каталоге /data/app/ хранится там на протяжении всего времени работы от момента установки до момента деинсталляции приложения.
Очистить данные приложения Андроид
В частном случае это может быть немного иной путь, что, в частности, соответствует общему каталогу, отличаясь только отображением иерархии каталогов:
Этой папкой возможные места хранения данных приложения на Андроид не ограничиваются. Часто программа при установке создаёт свой каталог в корне карты памяти: либо внутренней, либо внешней. Именно в этих папках программа сохраняет информацию, которую:
Кроме вышеперечисленных путей есть ещё один каталог, о котором нужно упомянуть отдельно. Речь пойдёт о папке obb, которая расположена по пути:

Игровая индустрия развивается достаточно быстро. Вместе с этим растут и требования к аппаратной части, в том числе и к дисковому пространству. Всё это актуально и для Android OS. Серьёзные игры с красивой прорисовкой графики и серьёзным геймплеем требуют хранения большего объёма системной информации. Всё это привело к тому, что у многих игр появился ярко выраженный кэш. Но, как и в разных способах установки программ, есть несколько путей и в том, как поместить кэш игры в папку /Android/obb/:
Теперь кому-то может показаться странным, почему информацию о папке с кэшем мы поместили в главу о данных Android, а не о самом кэше. И вот в чём дело. По сути, кэш игры так называют потому, что он скачивается ею при установке. Эти данные являются кэшем только для самого приложения и с точки зрения пользователя. Для операционной системы Андроид файлы кэша игры являются данными приложения и при очистке кэша не затираются (ниже повторим об этом). А когда же затираются?
Также при установке игр с кэшем необходимо учитывать ещё один нюанс: при удалении такой игры следует вручную проверить, удалился ли кэш автоматически. Если этого не произошло, то папку с кэшем можно удалить вручную любым файловым менеджером.
Очистить кэш приложения Андроид
Для начала определим, что такое кэш приложения :
Но у кэша существует естественный недостаток: он хранит как действительно нужные, регулярно вызываемые файлы, так и те, которые были показаны лишь раз и больше пользователю не понадобятся. Чтобы избавиться от ненужной информации, занимающей место, существует опция, которая позволяет очистить кэш приложения.
Давайте рассмотрим пример, который объясняет смысл понятий программа, данные приложения и кэш приложения простыми словами.
В какой-то момент времени мы переезжаем в другой офис (прошивка или смена устройства), он больше и просторнее, но в нём пока нет ничего. В первую очередь, приходит офис-менеджер (установка программы). Однако, она пока не может работать, у неё нет данных, поэтому мы устанавливаем ей компьютер (подгрузка данных приложения). Работа закипела. Но пока стол пуст (кэш очищен), скорость работы офис-менеджера ниже прежней: каждый раз, чтобы скрепить документы или посчитать большие суммы, ей приходится отвлекаться на поиски нужных инструментов. Поэтому, постепенно на столе у Татьяны вновь появляется степлер и кулькулятор (заполнение кэша). А вот блокнот, оказывается, нужен не так часто, поэтому он может лежать в выдвижном шкафу, а на освободившееся на столе место мы поместим календарь, обращение к которому происходит чаще. Благодаря этому Татьяна теперь справляется со своими задачами ещё быстрее.
Кэш приложения также может размещать по разным папкам. Чаще всего это одноимённый каталог cache, который расположен, например, в папке приложения из /Android/data/

То есть, если на нашем смартфоне заканчивается доступная память на накопителе, именно очистка кэша позволит нам освободить некоторый объём памяти для записи новых данных. Перед очисткой кэша убедитесь, что данная процедура безболезненна для конкретной программы и не приведёт к удалению важной информации.
Data Mining в футболе: давайте оцифруем матч и всех посчитаем!

Тренер следит за вами. Тренер помнит. Тренер не забывает и не прощает.
Если вы видели фильм «Человек, который изменил всё», то уже почти всё знаете. Игроков нужно оценивать по массе показателей, причём интуиция работает далеко не всегда. С помощью аналитики можно в разы увеличить эффективность тренировок, найти новых игроков, которые помогут команде и просто повысить уровень игры. Аналитика рулит.
Футбол в реальности сначала чем-то напоминает RPG без правил, где нужно разбираться. После введения аналитики — это такая же RPG, к сотням показателей которой есть инструкция. Тренер получает возможность «вырастить» настоящего манчкина-читера.
На поле в течение 90 минут находится 22 футболиста и мяч. Тренер может уследить только за частью игроков — плюс его восприятие очень сильно подвержено эмоциям. Проводились исследования, сколько эпизодов запоминается: даже самые опытные тренеры вспоминали только около 35% ситуаций, причём всегда около мяча. Всё остальное — «мёртвая зона». Нельзя охватить все поле и понять, где кто стоял — и правильно или неправильно делал. Для этого нужен постматчевый анализ.
Поначалу Стив Макларен – известный у нас как главный тренер сборной Англии в 2006 году (тогда сборная России победила англичан в Лужниках) — начал использовать видеоповторы как способ анализа игры. Компания Prozone поначалу занималась именно систематизацией видеоданных, отбирая и подписывая наиболее характерные моменты. Так шло с 1999 года по примерно 2005, когда появилось распознавание видео.
Интервью
За 12 лет компания завоевала английский рынок и пришла во многие страны, в том числе — в Россию. У отечественного представителя Prozone мы взяли специальное интервью для Хабра в преддверии сугубо технической лекции о специальном софте, которая пройдёт 14 марта в Digital October (вот событие на Хабре).
— Кто уже использует эту систему?
Очень многие. После недавнего слияния компании Prozone с компанией AMISCO, клиентская база увеличилась вдвое. Это почти все клубы Англии, в том числе, Арсенал, Манчестер Юнайтед, Ман Сити, Ливерпуль, а также такие мировые гранды, как Реал Мадрид, Интер Милан, Бавария Мюнхен, Лион. В России первыми стали ЦСКА и Динамо, далее Спартак и Крылья Советов. Плюс Динамо Киев, известный своим научно-исследовательским центром, с лета 2011 года.
— Как это работает?
Есть разные виды анализа. Самый простой — берётся одна камера, которая снимает матч с одной точки (например, с крыши стадиона). Видеоданные с неё прогоняются через аналитические сервисы, после чего вы получаете точные данные для анализа. Если нужно построить «анимационный симулятор» матча и получить фитнесс-данные футболистов, используется уже специальное оборудование, состоящее из комплекса камер: это гарантирует повышенную точность распознавания игроков на поле и их перемещений.
— Почему важен постматчевый анализ?
Тренер и его штаб хотят всё знать для повышения эффективности игры. Стандартные методы не давали высокой точности. Очень важно предоставлять именно точные данные — иначе они становятся не нужными. Важно не только снимать массив данных, но и точно переводить его на язык главного тренера. В начале 2000-х эту задачу решал больше видеомонтаж, теперь это Data Mining с помощью аналитика команды.
— Что я получаю после матча?
Начинаем с электронного отчёта, который может быть распечатан на бумаге моментально после игры. Это порядка 1500 событий на поле, описывающих технико-тактические действия игроков.
Есть интерактивная платформа для просмотра матчей — она анализирует технико-тактическая действия команды. Тут оценивается существенно больше: до 2300 событий за игру, и анализ можно получить через 12 часов после окончания матча.
Выглядит это так: у штаба стоит спецсофт, который заливает на локальную машину примерно 2-мегабайтный подготовленный анализ матча с сервера. Дальше в интерфейсе можно выбирать детализацию по нужным действиям и сравнивать различные численные показатели. Захотели посмотреть Иванова за весь матч — посмотрели только его в динамике и числах. Хочется узнать в каком квадрате поля команда отбирала больше мячей? Не вопрос.
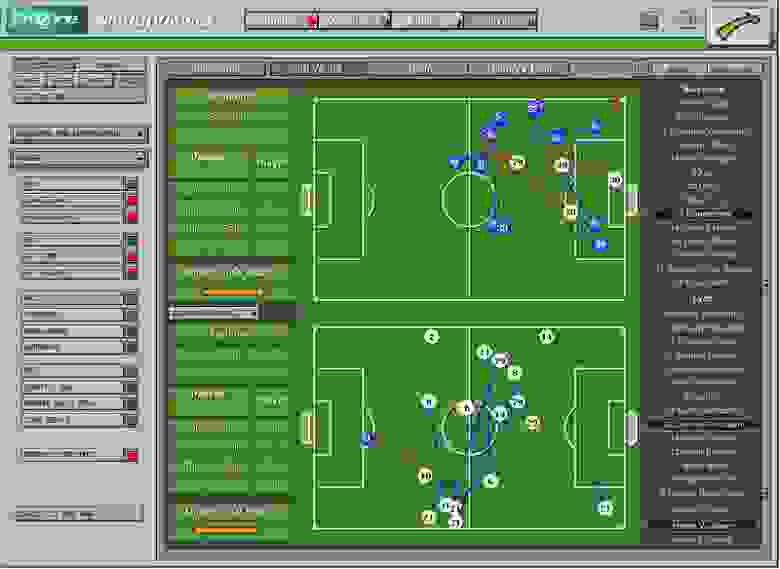
Есть статистика по своим игрокам и футболистам оппонента, обзор матча (для сравнения своих и чужих защитников или двух своих нападающих, например), автоматические отметки точек для видеомонтажа и анализ (интерактивные карты футбольного поля: видны направления тактико-технических действий, где они совершались и какими футболистами). Можно сравнить команды по точности передач и другим показателям. Например, можно отсортировать передачи по критериям удачности, направления, длины паса, дошла ли до цели, типа (головой, навес) и множеству других вариантов. Доступно более 40-50 фильтров на секцию, и всё это будет показано на лекции.
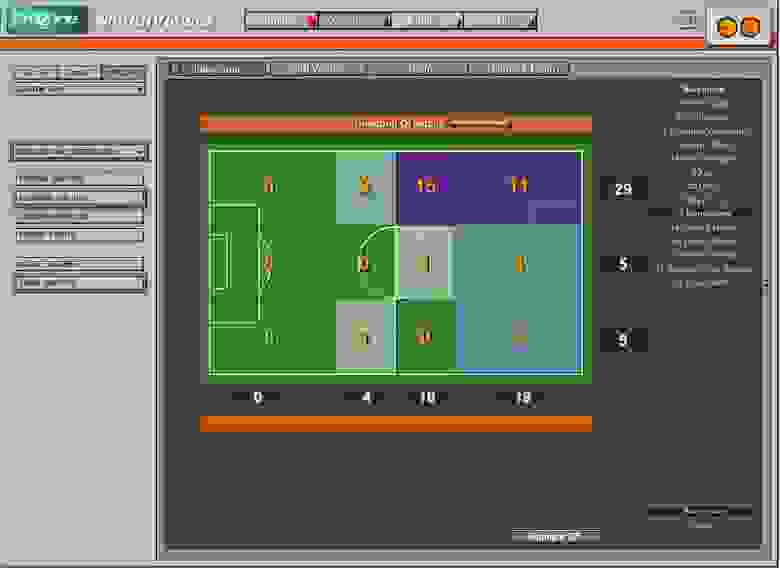
— Что, собственно, с Data Mining?
Гордость компании — это система глубокого анализа матча, которая требует специальных камер для распознавания. Самое простое — в любой момент можно посмотреть «анимационную» картинку с детальными численными данными и расположение самих объектов в динамике, что для послематчевого теоретического занятия — бесценная вещь.
Посложнее — например, секция фитнеса, она показывает какую беговую работу сделал футболист. Особенность в том, что таких «упражнений» шесть видов, и многим тренерам важна работа на высокой скорости (более 5,5 метров в секунду), что отсортировать руками и свести почти нереально. Ещё можно посмотреть, когда и кто уставал: эти данные уходят фитнесс-тренеру, что просто бесценно для оценки физического состояния и плана тренировок.
Самое главное — тренер может моделировать тренировочный процесс и выявить неочевидные «бутылочные горлышки» действий команды, чтобы усовершенствовать разные критичные моменты.
— Можно ли узнать, стоит ли игрок своих денег?
Да, для скаутинга есть отдельный продукт. В сезон обрабатывается около 10 тысяч игр. Клуб, купивший лицензию, может посмотреть данные по любому футболисту за всё время: это статистика и аналитика. Можно сравнить уровень этого футболиста и уровень среднего игрока на российском чемпионате. Например, если полузащитник делает в среднем 4 навеса в штрафную, можно сразу оценить, подходит ли новый игрок под этот критерий.
Ещё один онлайн-продукт «Тренд» позволяет оценивать тренд развития на основе всех матчей вашей команды и оценивает динамику развития игроков. Prozone даёт сырые объективные данные, но не делает экспертные прогнозы стоимости игроков. Прогнозы — задача менеджера.
— Что за железо требуется для распознавания?
Для технико-тактического анализа без «фитнесса и анимации», нужна обычная камера — достаточно получить картинку, которая следит за мячом. Футболисты распознаются специальным софтом. Важно получить техническую картинку, без повтора и рекламы, разумеется (на обычной записи по ряду причин примерно 2% действий теряются).

Пример картинки камеры
Можно распознавать старые матчи на основе видеозаписей: например, футбольный клуб «Эвертон» выпустил в продажу коробку, где был полностью разобран культовый матч против «Баварии»: там видео и детальный тактико-технический анализ.
Интересно, что Prozone — сертифицированная система, которая даёт 100% точные данные. В мире футбола такая гарантия означает примерно нечто столь же невозможное как «софт 100% без багов» в IT. Для достижения такой точности нужно специальное оборудование на стадионе. В основном — это ip-камеры, которые следят за движением. Ставится 8 камер по периметру, на крыше по специальной схеме. Подключается сервер для сбора данных и канал для доставки в продашн-центр.

Группировка камер в статическом комплексе
Есть лайт-версия (с погрешностью 5-7 процентов) — 4 переносные камеры на штативах. Удобно там, где надо быстро развернуться и есть операторы, например, на выезде. Крылья Советов возят на каждую выездную игру такие штуки.
Статические комплекты из 8 камер размещены на Лужниках и Арене Химки в Москве и на стадионе Лобановского в Киеве.
— Насколько просто научиться работать с сервисом?
Обычно от 1 до 5 дней, через пару недель система воспринимается «как родная». В идеале в каждом клубе есть аналитик, который умеет превращать вопросы тренера в запросы к системе и отслеживать то, что потенциально нужно тренеру, и это направление уже развивается в РФ. В Европе такое уже давно используется: ведь тренер не может сутками сидеть за монитором. У нас обычно аналитик является и видеооператором команды.
— Есть специальные образовательные программы?
Да. Есть как отдельные тренинги, так и глобальные образовательные программы для аналитиков и тренеров команд.
— В чём сложности внедрения?
Во-первых, немного консервативное отношение. Сейчас, конечно, на рынке нет ни одного тренера, который бы сказал, что система не нравится. Все признают, что данные полезны и нужны, но, тем не менее, есть некоторое сопротивление, в частности, связанное с тем, что на отечественном рынке отрасль аналитики не развита в сравнении с Европой.
— Можно ли будет обойтись без подобных инструментов через 10-15 лет?
Вряд ли. В Англии, например, уже сейчас почти все так или иначе используют анализ. Это важно для успешности клуба.
— Какие следующие шаги в развитии вы видите?
Попробуем 3D-моделирование за счёт захвата данных с нескольких камер. Уже начали тесты анализа хоккейных матчей NHL.
— Что из вашей модели нельзя повторить?
Очень сложно повторить высокую точность данных: у нас есть ряд ключевых патентов и очень большая практика. Большие вложения потребуются, чтобы догнать по оборудованию и софту: мы на поколение впереди всех других аналитических компаний. Мало кто сможет поддерживать постоянный контакт с тренерским составом — мы в курсе их потребностей и задач, получаем очень качественную обратную связь.
— Где можно узнать больше технических деталей?
На лекции в Digital October 14 марта.
Теперь о самой лекции
Лекцию проведёт Блейк Вустер, доверительный советник FIFA, UEFA, Chelsea FC и Real Madrid, бизнес-лидер Prozone. Он будет рассказывать о технической стороне и конкретном эффекте от использования системы. На лекцию приглашены в качестве экспертов Игорь Мещанчук, спортивный директор Российской футбольной премьер лиги, Илья Рустамов, директор по маркетингу Чемпионат.com и Александр Иванский, руководитель проекта InStat Football (по сути — отечественного конкурента Prozone). Ожидается также практикующий тренер, имеющий возможность пояснить ситуацию со своей стороны.
Да, на лекцию можно прийти, она бесплатная. Вот событие на Хабре, а вот регистрация. В комментариях к этому топику ещё можно оставлять каверзные вопросы Блейку и экспертам.
Data Mining в онлайн играх
 Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Мы захотели узнать, почему уходят игроки и можно ли предсказать их уход. Предмет исследования – ММОРПГ Аион, однако наши результаты оказались применимы к широкому кругу игр и онлайн сервисов.
Чуть ли не британскими учеными установлено, что у пользователя очень короткая память. Сегодня он ушел из игры, а завтра уже не вспомнит, что он вообще ее устанавливал. Если игрок ушел, то действовать надо немедленно. Но как нам определить, действительно ли ушел человек, или просто сегодня вечером пьет пиво с друзьями и в игре не появится? Идеальным случаем было бы предсказание потенциального ухода еще до того, как пользователь нас покинул. И даже до того, как в его сознании зародилась мысль, что Аион не похож на торт. Наверное, такая задача тоже решаема, однако мы ставили более реалистичную цель – оперативно предсказывать уход в день последнего логина в игру. Уходом назовем неактивность человека в течение недели – и мы как раз не хотим ждать эти 7 дней, а желаем знать как можно скорее, что игрок больше не вернется. Мы желаем знать будущее!
Техническая сторона
Для анализа у нас было море информации – у Аиона лучшая система логирования, что я видел среди корейских игр, мы буквально знаем об игроке каждое его движение, каждый чих и каждый след, который он оставил на сервере. Период для анализа – первые девять уровней в игре, около 10 стартовых часов геймплея – за этот период отваливалась примерно половина всех новичков.
На проект выделили часть ресурсов нашей системы аналитики – два блейд сервера Dual Xeon E5630 32Gb RAM, 10 Tb холодного хранилища для исходных и промежуточных данных, 3 Tb горячего хранилища в RAID10 SAS массиве для рабочих данных. Оба сервера под MS SQL 2008R2 – один под БД и один под Analysis Services. Программная часть решения – стандартный пакет Business Intelligence от Microsoft, входящий в SQL Server.
Фаза 1 – я все знаю!
Поскольку я много лет был геймдизайнером и провел под сотню плейтестов, то был уверен, что и сейчас экспертное мнение даст 90% ответов почему уходят игроки. Не научился пользоваться телепортацией, надоело бегать ногами – ушел. Умер от первого же монстра в игре – ушел. Не выполнил вторую миссию, застрял и не знает что делать – ушел. Аион, при всем его качестве и технологичности, не самая дружелюбная к новичку игра. Это черта всех корейских игр, рассчитанных на хардкорную и гиперсоциальную среду корейских игроков, а не одиноких скучающих российских казуальных пользователей.
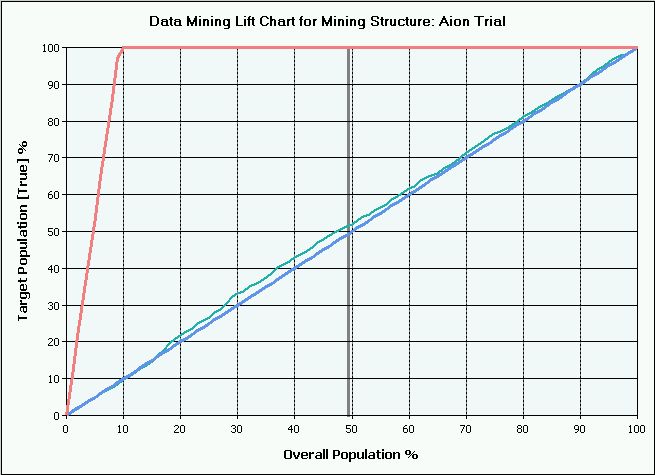
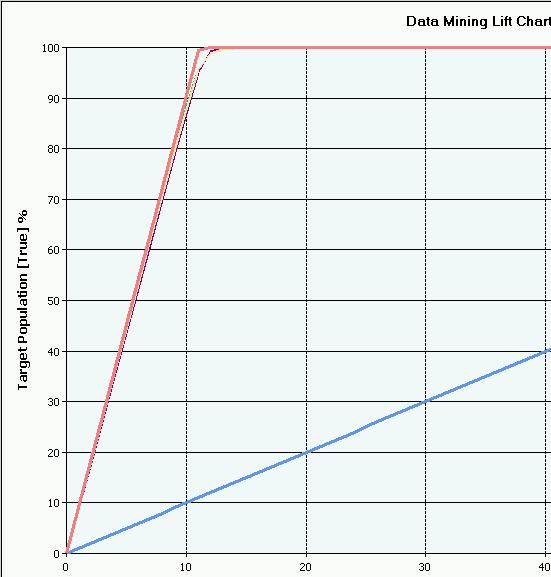
Как читать lift chart: нижняя наклонная прямая линия — это результат генератора случайных чисел, предсказывающего нашу булеву переменную научным методом бросания монетки. Верхняя линия, быстро доходящая до 100% — это оракул, идеальный предсказатель будущего. Между ними находится неровная, трепещущая ниточка – это наша модель. Чем ближе график к идеальной линии – тем выше предсказательная точность модели. График приведен для 7-го уровня, но картина похожая от первого до девятого.
Fatality! Наша первая модель предсказывает уходящих игроков чуть-чуть лучше метода орла и решки. Отправляем в модели оставшиеся гипотезы, чистим данные, процессим:

Уже лучше, но все равно точность чуть выше 50%. А если посмотреть детальнее recall (ошибки второго рода), то картина грустная:

Эта же таблица русским языком – из каждых 100 предсказанных моделью уходов 49 будут ложные (игрок никуда уходить не собирался), точность модели составит 1008/(1008+982)=51%. При этом еще часть реальных уходов модель вообще пропустит – примерно 28% из истинно ушедших [391/(391+1008)=28%]. Внимание, это не каноническое определение recall, но такая формула нагляднее.
Итог фазы 1: все изначальные идеи провалились, предсказание не работает. Шеф, все пропало!
Фаза 2 – мы ничего не знаем
Полный разгром и бегство с поля боя, и вечный вопрос «Что делать?». На помощь приходит наивный алгоритм Байеса – максимально человеко-читаемый и понятный из всех data mining классификаторов. Анализ Байесом показал, что выбранные гипотезы довольно слабо характеризуют ушедших и остающихся игроков, то есть я ошибся с выбором изначальных предпосылок. Но, поиграв с глубиной и чувствительностью другого алгоритма, дерева принятия решений, стало понятно – есть правильные гипотезы, дерево ветвится по ним, но факторов решительно недостаточно – рост дерева прерывается на 2-3 ветке.
Не забираясь в дебри математики, которые и сам не понимаю, упрощенно — алгоритм дерева решений делит исходные данные на сегменты с максимально низкой итоговой энтропией, то есть на максимально непохожие наборы данных. Если дерево перестало ветвиться – значит, нужны новые гипотезы и новые метрики в исходных данных, чтобы дерево глубже разделяло входной поток данных и лучше предсказывало будущее.
Я собрал брейншторм с командой проекта, где мы фонтанировали идеями – кто же наши новички, как они играют, чем они отличаются друг от друга. Вспоминали истории как наши подруги и жены знакомились с Аионом, и что из этого вышло. Итогом брейншторма стал дополненный список индивидуальных гипотез (пользовался ли игрок телепортацией, расширил ли себе инвентарь, привязал ли точку воскрешения и т.д.) и новая идея – хорошо бы посмотреть насколько вообще отличается активность уходящих от остающихся в игре.
Загрузили, обучили, верифицировали, проанализировали. Не буду грузить вас морем lift chart’ов по каждому уровню и каждой модели, приведу сразу обработанные и проанализированные данные:
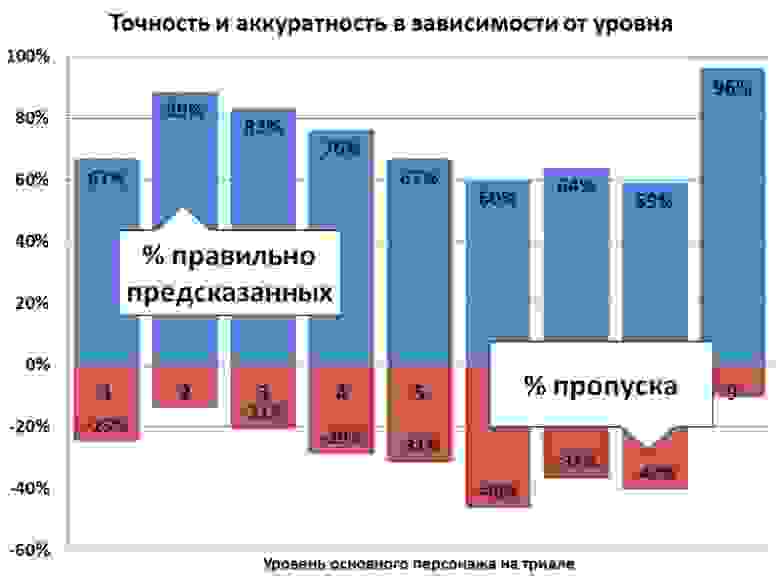
Пик точности на 9 уровне был связан с внутренней особенностью игры на момент исследования.
В целом картина улучшилась в области 2-4 уровней, но 6-8 ниже плинтуса, с такой точностью данные нам просто бесполезны.
Дерево принятия решений бодро показывает – факторы активности являются самыми важными для предсказания ухода. По сути, три величины – время на уровне, убитые монстры и сделанные задания – определяют львиную долю уходов. Остальные факторы добавляют не более 5% точности. Также дерево по-прежнему остается голым, крона обрывается на третьей ветке – то есть модель жаждет больше релевантных метрик. Что еще непонятно – точность трех алгоритмов сильно меняется от уровня к уровню.
Итог фазы 2: успех идеи об измерении средней активности, а не индивидуальных факторов. Но точность предсказания все еще неудовлетворительна. Путь по граблям вывел к правильной последовательности анализа результатов – сначала факторы и корреляции (Байес), потом их влияние на итог (дерево решений).
Фаза 3 – мы знаем куда копать
Воодушевленный прогрессом, я наметил три вектора развития проекта – больше метрик общей активности, больше специфических метрик индивидуальной эффективности, и более глубокое изучение инструментов Microsoft BI.
Пришлось повозиться с новыми индивидуальными метриками, связанными с глубиной геймплея и эффективностью игры, например процентом автоатаки. Мы сегментировали персонажей по классам (воины направо, целители налево) и для каждого класса рассчитали 25, 50 и 75-й перцентили распределения по %% автоатаки, и разбили всех на 4 категории. Теперь данные нормализованы, и игровые классы можно сравнивать между собой – на вход data mining моделей уходит номер категории.
Индивидуальные метрики закрепились на глубине седьмого-девятого узла дерева, т.е. они прибавили пару процентов к точности предсказания, но не улучшили ситуацию кардинально. Следующим шагом было штудирование книги Data Mining with Microsoft SQL Server 2008 на предмет тонкостей работы с Analysis Services. Сама по себе книга помогла только с настройкой чувствительности дерева (от силы плюс один-два процента прироста точности), но натолкнула на мысль о правильной дискретизации.
В примере выше с автоатакой мы сделали ручную дискретизацию данных – разбиение на категории по каким-то признакам. SQL сервер автоматически делает дискретизацию несколькими способами. Экспериментальным путем я быстро понял, что алгоритм разбиения и число сегментов очень сильно влияют на предсказательную силу модели. Ручное изменение числа сегментов сильно влияет на форму и точность дерева. На ручную подгонку я потратил неделю, скрупулезно для каждой структуры каждого уровня (а это 9 уровней по 30+ метрик) экспериментируя с числом сегментов. Для каких-то метрик оптимальным было 7 сегментов (например, время на текущем уровне), для каких-то 12 (суммарное время в игре), для каких-то больше 20 (число убитых монстров).
Ручная настройка дала сильный прирост предсказанных значений – точность при этом не сильно повысилась, но модели стали делать заметно меньше пропусков, а результаты дерева сравнялись с нейронной сетью:
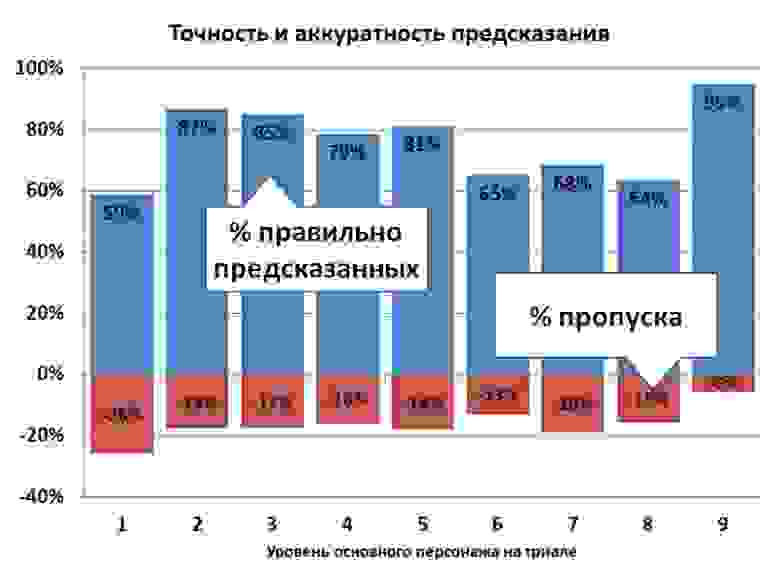
Итог фазы 3: мы вышли на приемлемые показатели точности и аккуратности и узнали много интересного про нашу игру и наших игроков.
Фаза 4 – только победа
Я, честно говоря, думал, что потолок достигнут – дерево ветвится глубиной до 9-12 узлов, аккуратность сильно улучшена. Новые гипотезы точность никак не повышают, новые факторы никакой информации не дают. В принципе, общая точность в 78% и recall 16% — это удовлетворительно для начала работы с игроками. Я бы, наверное, не стал при таких цифрах давать бесплатную подписку для удержания в игре, но сообщать игроку релевантную информацию уже можно без особых ошибок.
Помощь пришла неожиданно – поскольку data mining проект длился уже третий месяц, у нас несколько устарели логи – игра же изменилась за это время. Подгрузив немного свежих данных, а заодно в очередной раз доработав ETL процедуры, мы заметили изменения в моделях. На новых данных они вели себя иначе – при, в общем-то, прежней точности и аккуратности, разбиения дерева были другими. На этом этапе все три алгоритма обучались очень быстро – минуту на каждый уровень из 9, и накормить их дополнительным набором данных просто.
Сказано – сделано, выгружаем вообще все накопленные за 3 месяца данные и одним махом направляем модели обучаться (процесс стал занимать не минуту, а целых пять на каждый уровень – не критично). Очередной раунд ручной подгонки, и вот итог:
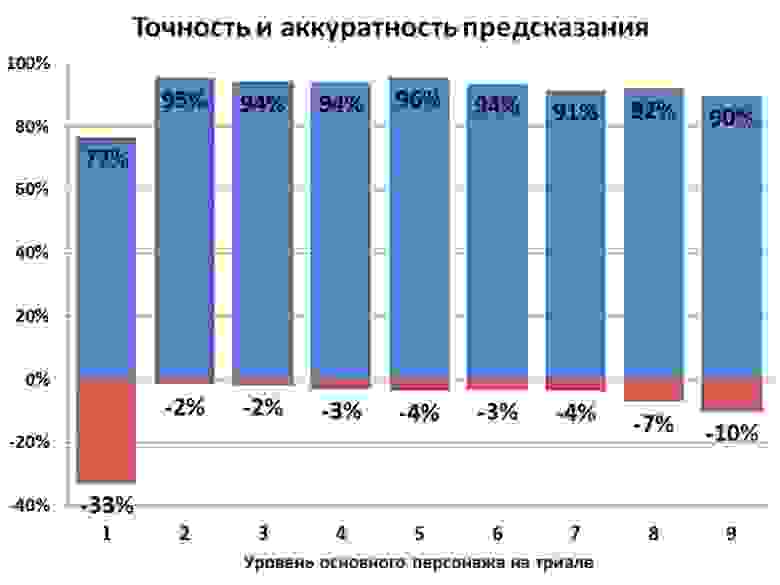
Увеличив объем обучающих данных, мы сделали процесс обработки дольше, но зато какой отличный результат!
С первым уровнем, к сожалению, немного можно сделать – около половины уходов, как сказал бы Авинаш Кошик, “I came, I puked, I left”. У нас есть данные о буквально паре действий игрока – и дальше он закрывает клиент игры и никогда не возвращается обратно.
Напоминаю, что все исследования выше – это обучение на накопленных исторических данных. Теперь я хочу проверки боем! Проверяем на живых данных – берем свежих, сегодняшних пользователей, прогоняем через модель и сохраняем результат предсказания. Через неделю сравниваем предсказания модели с объективной реальностью – кто из недельной давности новичков действительно ушел, а кто в игре остался:
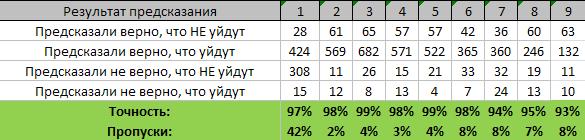
Самое интересное
Первая цель проекта – предсказание ухода новичка из игры – безусловно достигнута. С такой точностью уже можно принимать решения по возврату игрока, общаться с ним, мотивировать его, давать плюшки. И это предсказание почти в день ухода: сегодня вечером человек вышел из игры – завтра в 5 утра данные обработались и вероятность ухода уже известна с высокой достоверностью.
Победа!
За два месяца, с нуля – никто из нас никогда даже близко с data mining не сталкивался, — с помощью двух книг и желания попробовать что-то новое, на основе созданной нами мощной, но пассивной системы аналитики в Иннове, мы сделали инструмент, активно смотрящий в будущее. В отличие от обычной отчетности и аналитики трендов на исторических данных, мы в 6 утра уже знаем почти наверняка о наших вчерашних новичках в Аионе – увидим ли мы их сегодня в игре или нет. И можем действовать, пока еще не поздно.
Анализ проведен для онлайн-игры, но как вы могли заметить, основной вклад в точность предсказания был от обобщенных метрик активности – и я уверен, что подход будет работать для любого вашего продукта или сервиса, с которым активно работают пользователи, если конечно у вас есть желание выйти на качественно новый уровень.
PS. Если тема хабравчанам интересна, то можно продолжить – про предсказание уходов старичков, сегментацию и кластеризацию, миграцию между кластерами и другие data mining проекты, которые мы сделали в уходящем году.
PS2. Вторая книга, рекомендую абсолютно всем — Программируем коллективный разум
