Структуры данных в pandas / pd 2
Ядром pandas являются две структуры данных, в которых происходят все операции:
Series — это структура, используемая для работы с последовательностью одномерных данных, а Dataframe — более сложная и подходит для нескольких измерений.
Пусть они и не являются универсальными для решения всех проблем, предоставляют отличный инструмент для большинства приложений. При этом их легко использовать, а множество более сложных структур можно упросить до одной из этих двух.
Однако особенности этих структур основаны на одной черте — интеграции в их структуру объектов index и labels (метки). С их помощью структурами становится очень легко манипулировать.
Series (серии)
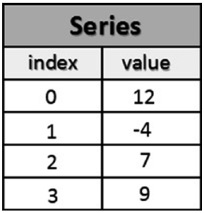
Создание объекта Series
Для создания объекта Series с предыдущего изображения необходимо вызвать конструктор Series() и передать в качестве аргумента массив, содержащий значения, которые необходимо включить.
Как можно увидеть по выводу, слева отображаются значения индексов, а справа — сами значения (данные).
В таком случае необходимо будет при вызове конструктора включить параметр index и присвоить ему массив строк с метками.
Выбор элементов по индексу или метке
Выбирать отдельные элементы можно по принципу обычных массивов numpy, используя для этого индекс.
Или же можно выбрать метку, соответствующую положению индекса.
Таким же образом можно выбрать несколько элементов массива numpy с помощью следующей команды:
В этом случае можно использовать соответствующие метки, но указать их список в массиве.
Присваивание значений элементам
Понимая как выбирать отдельные элементы, важно знать и то, как присваивать им новые значения. Можно делать это по индексу или по метке.
Создание Series из массивов NumPy
Фильтрация значений
Например, если нужно узнать, какие элементы в Series больше 8, то можно написать следующее:
Операции и математические функции
Для операторов можно написать простое арифметическое уравнение.
Количество значений
В Series часто встречаются повторения значений. Поэтому важно иметь информацию, которая бы указывала на то, есть ли дубликаты или конкретное значение в объекте.
Значения NaN
Функции isnull() и notnull() очень полезны для определения индексов без значения.
Series из словарей
Операции с сериями
Одно из главных достоинств этого типа структур данных в том, что он может выравнивать данные, определяя соответствующие метки.
Новый объект получает только те элементы, где метки совпали. Все остальные тоже присутствуют, но со значением NaN.
DataFrame (датафрейм)
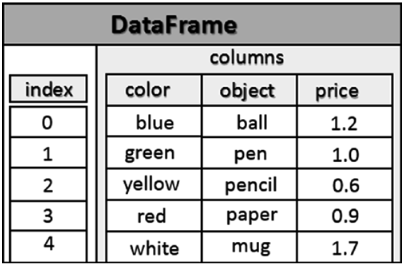
Создание Dataframe
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
| object | price | |
|---|---|---|
| 0 | ball | 1.2 |
| 1 | pen | 1.0 |
| 2 | pencil | 0.6 |
| 3 | paper | 0.9 |
| 4 | mug | 1.7 |
Выбор элементов
То же можно проделать и для получения списка индексов.
Указав в квадратных скобках название колонки, можно получить значений в ней.
Для строк внутри Dataframe используется атрибут loc со значением индекса нужной строки.
Для выбора нескольких строк можно указать массив с их последовательностью.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Если необходимо извлечь часть Dataframe с конкретными строками, для этого можно использовать номера индексов. Она выведет данные из соответствующей строки и названия колонок.
| color | object | price | |
|---|---|---|---|
| 2 | yellow | pencil | 0.6 |
| 4 | white | mug | 1.7 |
Возвращаемое значение — объект Dataframe с одной строкой. Если нужно больше одной строки, необходимо просто указать диапазон.
| color | object | price | |
|---|---|---|---|
| 0 | blue | ball | 1.2 |
Наконец, если необходимо получить одно значение из объекта, сперва нужно указать название колонки, а потом — индекс или метку строки.
Присваивание и замена значений
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 0.6 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Одна из главных особенностей структур данных pandas — их гибкость. Можно вмешаться на любом уровне для изменения внутренней структуры данных. Например, добавление новой колонки — крайне распространенная операция.
Ее можно выполнить, присвоив значение экземпляру Dataframe и определив новое имя колонки.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 12 |
| 1 | green | pen | 1.0 | 12 |
| 2 | yellow | pencil | 0.6 | 12 |
| 3 | red | paper | 0.9 | 12 |
| 4 | white | mug | 1.7 | 12 |
Здесь видно, что появилась новая колонка new со значениями 12 для каждого элемента.
Для обновления значений можно использовать массив.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 3.0 |
| 1 | green | pen | 1.0 | 1.3 |
| 2 | yellow | pencil | 0.6 | 2.2 |
| 3 | red | paper | 0.9 | 0.8 |
| 4 | white | mug | 1.7 | 1.1 |
Тот же подход используется для обновления целой колонки. Например, можно применить функцию np.arrange() для обновления значений колонки с помощью заранее заданной последовательности.
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | blue | ball | 1.2 | 0 |
| 1 | green | pen | 1.0 | 1 |
| 2 | yellow | pencil | 0.6 | 2 |
| 3 | red | paper | 0.9 | 3 |
| 4 | white | mug | 1.7 | 4 |
Наконец, для изменения одного значения нужно лишь выбрать элемент и присвоить ему новое значение.
Вхождение значений
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | False | False | False | False |
| 1 | False | True | True | True |
| 2 | False | False | False | False |
| 3 | False | False | False | False |
| 4 | False | False | False | False |
| item | color | object | price | new |
|---|---|---|---|---|
| id | ||||
| 0 | NaN | NaN | NaN | NaN |
| 1 | NaN | pen | 1.0 | 1.0 |
| 2 | NaN | NaN | NaN | NaN |
| 3 | NaN | NaN | NaN | NaN |
| 4 | NaN | NaN | NaN | NaN |
Удаление колонки
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | 1.2 |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | 3.3 |
| 3 | red | paper | 0.9 |
| 4 | white | mug | 1.7 |
Фильтрация
Даже для Dataframe можно применять фильтры, используя определенные условия. Например, вам нужно получить все значения меньше определенного числа (допустим, 1,2).
| item | color | object | price |
|---|---|---|---|
| id | |||
| 0 | blue | ball | NaN |
| 1 | green | pen | 1.0 |
| 2 | yellow | pencil | NaN |
| 3 | red | paper | 0.9 |
| 4 | white | mug | NaN |
Dataframe из вложенного словаря
В Python часто используется вложенный dict :
При интерпретации вложенный структуры возможно такое, что не все поля будут совпадать. pandas компенсирует это несоответствие, добавляя NaN на место недостающих значений.
| blue | red | white | |
|---|---|---|---|
| 2011 | 17 | NaN | 13 |
| 2012 | 27 | 22.0 | 22 |
| 2013 | 18 | 33.0 | 16 |
Транспонирование Dataframe
| 2011 | 2012 | 2013 | |
|---|---|---|---|
| blue | 17.0 | 27.0 | 18.0 |
| red | NaN | 22.0 | 33.0 |
| white | 13.0 | 22.0 | 16.0 |
Объекты Index
В отличие от других элементов в структурах данных pandas ( Series и Dataframe ) объекты index — неизменяемые. Это обеспечивает безопасность, когда нужно передавать данные между разными структурами.
У каждого объекта Index есть методы и свойства, которые нужны, чтобы узнавать значения.
Методы Index
Есть методы для получения информации об индексах из структуры данных. Например, idmin() и idmax() — структуры, возвращающие индексы с самым маленьким и большим значениями.
Индекс с повторяющимися метками
Пока что были только те случаи, когда у индексов одной структуры лишь одна, уникальная метка. Для большинства функций это обязательное условие, но не для структур данных pandas.
Определим, например, Series с повторяющимися метками.
Операции между структурами данных
Гибкие арифметические методы
Уже рассмотренные операции можно выполнять с помощью гибких арифметических методов:
| ball | mug | paper | pen | pencil | |
|---|---|---|---|---|---|
| blue | 6.0 | NaN | NaN | 6.0 | NaN |
| green | NaN | NaN | NaN | NaN | NaN |
| red | NaN | NaN | NaN | NaN | NaN |
| white | 20.0 | NaN | NaN | 20.0 | NaN |
| yellow | 19.0 | NaN | NaN | 19.0 | NaN |
Операции между Dataframe и Series
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 1 | 2 | 3 |
| blue | 4 | 5 | 6 | 7 |
| yellow | 8 | 9 | 10 | 11 |
| white | 12 | 13 | 14 | 15 |
| ball | pen | pencil | paper | |
|---|---|---|---|---|
| red | 0 | 0 | 0 | 0 |
| blue | 4 | 4 | 4 | 4 |
| yellow | 8 | 8 | 8 | 8 |
| white | 12 | 12 | 12 | 12 |
Pandas
Pandas — это библиотека Python для обработки и анализа структурированных данных, её название происходит от «panel data» («панельные данные»). Панельными данными называют информацию, полученную в результате исследований и структурированную в виде таблиц. Для работы с такими массивами данных и создан Pandas.
Работа с открытым кодом
Pandas — это opensource-библиотека, то есть ее исходный код в открытом доступе размещен на GitHub. Пользователи могут добавлять туда свой код: вносить пояснения, дополнять методы работы и обновлять разделы. Для работы потребуется компилятор (программа, которая переводит текст с языка программирования в машинный код) C/C++ и среда разработки Python. Подробный процесс установки компилятора С для разных операционных систем можно найти в документации Pandas.
В каких профессиях понадобится библиотека?
Навык работы с этой библиотекой пригодится дата-сайентистам или аналитикам данных. С помощью Pandas эти специалисты могут группировать и визуализировать данные, создавать сводные таблицы и делать выборку по определенным признакам.
Как установить Pandas
Шаг 1. На официальном сайте Pandas указан самый простой способ начать работу с библиотекой. Для этого потребуется установить Anaconda — дистрибутив (форма распространения программного обеспечения, набор библиотек или программного кода для установки программы) для Python с набором библиотек. Безопасно скачать его можно на официальном сайте.
Вот несколько советов по установке Anaconda для новичков:
Шаг 2. В командной строке Anaconda запустите JupyterLab — это интерактивная среда для работы с кодом, данными и блокнотами, которая входит в пакет дистрибутива.
Шаг 3. Создайте в JupyterLab новый блокнот Python3.
Шаг 4. В первой ячейке пропишите: import pandas as pd, после этого в следующих ячейках можно писать код.
DataFrame и Series
Чтобы анализировать данные с помощью Pandas, нужно понять, как устроены структуры этих данных внутри библиотеки. В первую очередь разберем, что такое DataFrame и Series.
Pandas Series (серия) — это одномерный массив. Визуально он похож на пронумерованный список: слева в колонке находятся индексы элементов, а справа — сами элементы.

Индексом может быть числовой показатель (0, 1, 2…), буквенные значения (a, b, c…) или другие данные, выбранные программистом. Если особое значение не задано, то числовые индексы проставляются автоматически. Например, от 0 до 5 как в примере выше.
Такая нумерация называется RangeIndex, в ней всегда содержатся числа от 0 до определенного числа N, которое обозначает количество элементов в серии. Собственные значения индексов задаются в квадратных скобках через index, как в примере ниже:

Индексы помогают обращаться к элементам серии и менять их значения. Например, чтобы в нашей серии [5, 6, 7, 8, 9, 10] заменить значения некоторых элементов на 0, мы прописываем индексы нужных элементов и указываем, что они равны нулю:

Можно сделать выборку по нескольким индексам, чтобы ненужные элементы в серии не отображались:
Pandas DataFrame — это двумерный массив, похожий на таблицу/лист Excel (кстати, данные из Excel можно читать с помощью команды pandas.read_excel(‘file.xls’)). В нем можно проводить такие же манипуляции с данными: объединять в группы, сортировать по определенному признаку, производить вычисления. Как любая таблица, датафрейм состоит из столбцов и строк, причем столбцами будут уже известные объекты — Series.
Чтобы проверить, действительно ли серии — это части датафрейма, можно извлечь любую колонку из таблицы. Возьмем набор данных о нескольких странах СНГ, их площади и населении и выберем колонку country:
… ‘country’: [‘Kazakhstan’, ‘Russia’, ‘Belarus’, ‘Ukraine’],
… ‘population’: [17.04, 143.5, 9.5, 45.5],
… ‘square’: [2724902, 17125191, 207600, 603628]
country population square
0 Kazakhstan 17.04 2724902
1 Russia 143.50 17125191
2 Belarus 9.50 207600
3 Ukraine 45.50 603628
В итоге получится простая серия, в которой сохранятся те же индексы по строкам, что и в исходном датафрейме.
Name: country, dtype: object
Аналитика данных с нуля
Получите востребованные навыки и освойте профессию аналитика данных за 6 месяцев. Дополнительная скидка 5% по промокоду BLOG.
Кроме этого, у датафрейма есть индексы по столбцам, которые задаются вручную. Для простоты написания кода обозначим страны индексами из двух символов: Kazakhstan — KZ, Russia — RU и так далее:
… ‘country’: [‘Kazakhstan’, ‘Russia’, ‘Belarus’, ‘Ukraine’],
… ‘population’: [17.04, 143.5, 9.5, 45.5],
… ‘square’: [2724902, 17125191, 207600, 603628]
country population square
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
>>> df.index = [‘KZ’, ‘RU’, ‘BY’, ‘UA’]
>>> df.index.name = ‘Country Code’
country population square
KZ Kazakhstan 17.04 2724902
RU Russia 143.50 17125191
BY Belarus 9.50 207600
UA Ukraine 45.50 603628
>>> df.loc[[‘KZ’, ‘RU’], ‘population’]
Name: population, dtype: float64
Также в DataFrame производят математические вычисления. Например, рассчитаем плотность населения каждой страны в нашем датафрейме. Данные в колонке population (численность населения) делим на square (площадь) и получаем новые данные в колонке density, которые показывают плотность населения:
>>> df[‘density’] = df[‘population’] / df[‘square’] * 1000000
country population square density
KZ Kazakhstan 17.04 2724902 6.253436
RU Russia 143.50 17125191 8.379469
BY Belarus 9.50 207600 45.761079
UA Ukraine 45.50 603628 75.377550
Data Science с нуля
Закрепите навыки Data Science и получите перспективную профессию за 13 месяцев. Дополнительная скидка 5% по промокоду BLOG.
Чтение и запись данных
Доступ по индексу в DataFrame
>>> df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
Name: viper, dtype: int64
2 1000 2000 3000 4000
Name: 0, dtype: int64
Группировка и агрегирование данных
Обратите внимание на as_index=False, эта часть кода отвечает за то, чтобы сохранить числовые индексы в результатах группировки и вычисления.
Сводные таблицы в Pandas
Для примера возьмем условный набор данных с простыми категориями one / two, small / large и числовыми значениями. В столбце A две категории foo / bar складываются в слово foobar — текст, который используется в программировании для условного обозначения. В этом случае он указывает, что мы делим данные на две группы по неопределенному признаку.
0 foo one small 1 2
1 foo one large 2 4
2 foo one large 2 5
3 foo two small 3 5
4 foo two small 3 6
5 bar one large 4 6
6 bar one small 5 8
7 bar two small 6 9
8 bar two large 7 9
>>> table = pd.pivot_table(df, values=’D’, index=[‘A’, ‘B’],
Мы разбиваем данные на две категории: bar и foo, в каждой из них будут подгруппы со значениями one и two, которые в свою очередь делятся на small и large. В сводной таблице мы вычисляем, сколько объектов будет в каждой группе. Для этого используем методы values, index, columns и aggfunc:
Аналитика данных с нуля
Получите востребованные навыки и освойте профессию аналитика данных за 6 месяцев. Дополнительная скидка 5% по промокоду BLOG.
Визуализация данных в Pandas
Дата-аналитики составляют наглядные графики с помощью Pandas и библиотеки Matplotlib. В этой связке Pandas отвечает за вычислительную часть работы, а вспомогательная библиотека «создает» картинку.
Посмотрим на данные о продажах в одной из компаний:
В таблице видно, что одни пользователи совершили уже более 7 000 покупок, а некоторые — сделали первую. Чтобы увидеть подробную картину, составляем график sns.distplot. На горизонтальной оси будет отображаться число покупок на одного покупателя, а на вертикальной — количество покупателей, которые совершили именно столько покупок в этой компании. Так по графику можно определить, что самой многочисленной оказалась группа клиентов, которая совершила всего несколько покупок, а группа постоянных клиентов немногочисленная.
distplot — это график, который визуализирует гистограммы, то есть распределяет данные по столбцам. Каждому столбцу соответствует доля количества объектов в данной группе. Также distplot показывает плотность распределения — плавный линейный график, в котором самая высокая точка указывает на наибольшее количество объектов.
Кроме этого, в Pandas есть другие виды графиков:
Например, можно отследить взаимосвязь между тем, сколько минут посетитель проводит в торговом центре и сколько магазинов успевает посетить за это время: кто-то за 30 минут успеет зайти в 5 бутиков, а кто-то обойдет 16. При этом каждый посетитель на графике будет отображаться отдельной точкой.
Data Science с нуля
Закрепите навыки Data Science и получите перспективную профессию за 13 месяцев. Дополнительная скидка 5% по промокоду BLOG.
Изучаем pandas. Урок 2. Структуры данных Series и DataFrame
Во втором уроке мы познакомимся со структурами данных pandas – это Series и DataFrame. Основное внимание будет уделено вопросам создания и получения доступа к элементам данных структур, а также общим понятиям, которые позволят более интуитивно работать с ними в будущем.
Введение
Структура данных Series
Пора переходить к практике!
Импортируем нужные нам библиотеки.
Создать структуру Series можно на базе различных типов данных:
Конструктор класса Series выглядит следующим образом:
data – массив, словарь или скалярное значение, на базе которого будет построен Series;
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
В большинстве случаев, при создании Series, используют только первые два параметра. Рассмотрим различные варианты как это можно сделать.
Создание Series из списка Python
Самый простой способ создать Series – это передать в качестве единственного параметра в конструктор класса список Python.
Обратите внимание на левый столбец, в нем содержатся метки, которые мы передали в качестве index параметра при создании структуры. Правый столбец – это по-прежнему элементы нашей структуры.
Создание Series из ndarray массива из numpy
Создадим простой массив из пяти чисел, аналогичный списку из предыдущего раздела. Библиотеки pandas и numpy должны быть предварительно импортированы.
Теперь создадим Series с буквенными метками.
Создание Series из словаря (dict)
Еще один способ создать структуру Series – это использовать словарь для одновременного задания меток и значений.
Создание Series с использованием константы
Рассмотрим еще один способ создания структуры. На этот раз значения в ячейках структуры будут одинаковыми.
В созданной структуре Series имеется три элемента с одинаковым содержанием.
Работа с элементами Series
Можно использовать метку, тогда работа с Series будет похожа на работу со словарем (dict) в Python.
Доступно получение slice’ов.
В поле для индекса можно поместить условное выражение.
Со структурами Series можно работать как с векторами: складывать, умножать вектор на число и т.п.
Структура данных DataFrame
Если Series представляет собой одномерную структуру, которую для себя можно представить как таблицу с одной строкой, то DataFrame – это уже двумерная структура – полноценная таблица с множеством строк и столбцов.
Конструктор класса DataFrame выглядит так:
index – список меток для записей (имена строк таблицы);
columns – список меток для полей (имена столбцов таблицы);
copy – создает копию массива данных, если параметр равен True в ином случае ничего не делает.
Структуру DataFrame можно создать на базе:
Создание DataFrame из словаря
В данном случае будет использоваться одномерный словарь, элементами которого будут списки, структуры Series и т.д.
Создание DataFrame из списка словарей
Создание DataFrame из двумерного массива
Работа с элементами DataFrame
Основные подходы представлены в таблице ниже.
| Операция | Синтаксис | Возвращаемый результат |
| Выбор столбца | df[col] | Series |
| Выбор строки по метке | df.loc[label] | Series |
| Выбор строки по индексу | df.iloc[loc] | Series |
| Слайс по строкам | df[0:4] | DataFrame |
| Выбор строк, отвечающих условию | df[bool_vec] | DataFrame |
Теперь посмотрим, как использовать данные операций на практике.
Операция: выбор столбца.
Операция: выбор строки по метке.
Операция: выбор строки по индексу.
Операция: slice по строкам.
Операция: выбор строк, отвечающих условию.
P.S.

Изучаем pandas. Урок 2. Структуры данных Series и DataFrame : 6 комментариев
Опечатка: случае[т]
В большинстве случает, при создании Series
P.S. Спасибо за статью!
> Конструктор класса Series выглядит следующим образом:
> … fastpath=False
Про этот параметр ничего не сказали.
И слово “slice”, которое вы как только не склоняете здесь и далее в книге, переводится как “срез”. Это вполне себе русское и подходящее по смыслу слово.
Как мне кажется, ‘slice’ стало уже сленговым словом, и его вполне можно употреблять. Но слово ‘срез’ звучит тоже не плохо))) В данном случае выбор был сделан в пользу первого.
