DMP часть 1. Микросегментирование аудитории с помощью ключевых слов
Авторы статьи: Данила Перепечин DanilaPerepechin, Дмитрий Чеклов dcheklov.
Здравствуйте.
Data management platform (DMP) — это наша любимая тема во всей истории про онлайн рекламу. RTB is all about the data.
В продолжение цикла рассказов о технологическом стеке Targetix (SSP, DSP), сегодня я опишу один из инструментов, входящих
в DMP — Keyword Builder.

Микросегментирование
Keyword Builder помогает рекламодателям создавать очень узкие аудиторные сегменты (их еще называют микросегментами). Для построения таких аудиторий мы решили использовать следующий механизм: рекламодатель задает список ключевых слов, а на выходе получает аудиторию, состояющую из тех пользователей, которые посещали страницы с указанными ключевыми словами или искали эти слова в поиске. С одной стороны это очень простой инструмент, с другой — он дает маркетологам довольно большие возможности для экспериментов.
Основное преимущество этого инструмента — полный контроль над созданием аудитории. Рекламодатель четко понимает, какие пользователи в итоге увидят рекламу. Например, можно создать аудиторию на основе такого списка ключевых слов: ford focus, opel astra, toyota corola.
Как это выглядит со стороны рекламодателя:

В первую очередь, для решения этой задачи мы от всех возможных поставщиков данных (Raw Data Suppliers) получаем clickstream (история посещения страниц пользователем). Данные приходят к нам в таком виде:
Цели и требования
Основное требование, которое мы предъявляли к инструменту — скорость создания аудитории. Этот процесс не должен занимать больше 5 минут даже для самых высокочастотных слов. Также важно, чтобы рекламодатель в интерфейсе при указании ключевого слова мог оценить размер аудитории. Оценка размера должна происходить в реальном времени при вводе слов (не более 100 мс, как видно на видео выше).
Первая архитектура, которая учит, «как не надо делать»
Вначале использовали MongoDB и всё шло довольно неплохо.
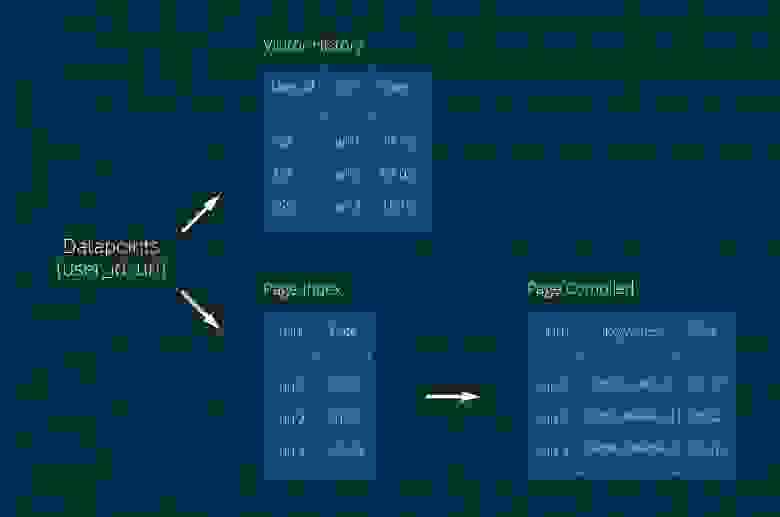
В коллекцию Visitor History записывали данные о пользователе, в Page Index — о страницах. URL страницы сам по себе ценности не представляет — страницу надо скачать и извлечь ключевые слова. Тут возникла первая проблема. Дело в том, что коллекции Page Compiled сначала не было, а ключевые слова записывались в Page Index, но одновременная запись ключевых слов и данных от поставщиков создавала слишком высокую нагрузку на эту коллекцию. Поле Keywords обычно большое, по нему необходим индекс, а в MongoDB той поры (версия 2.6) существовал lock на коллекцию целиком при операции записи. В общем, пришлось вынести ключевые слова в отдельную коллекцию Page Compiled. Пришлось — ну и что же, проблема решена — мы рады. Сейчас уже трудно вспомнить количество и характеристики серверов… что-то порядка 50 shard’ов.

Для создания аудитории по ключевым словам мы делали запрос в коллекцию Page Compiled, получали список URL’ов, на которых встречались эти слова, с этим списком шли в коллекцию Visitor History и искали пользователей, которые посещали эти страницы. Работало всё хорошо (сарказм) и мы могли создать 5, а то и 10(. ) аудиторных сегментов в сутки… если, конечно, ничего не упадёт. Нагрузка в то время была около 800 млн. datapoint’ов в сутки, TTL индекс — 2 недели: 800*14… данных было много. Работа спорилась и за 3 месяца нагрузка возросла вдвое. Но брать ещё N серверов для поддержания жизни этой странной конструкции было не комильфо.
Самый большой и очевидный минус этой архитектуры — вышеописанный запрос, связанный с получением списка URL. Результатом этого запроса могли быть тысячи, миллионы записей. А главное, по этому списку нужно было сделать запрос в другую коллекцию.
К чему мы пришли
Вообще, с самого начала было понятно, что что-то пошло не так, но теперь это стало очевидно. Мы пришли к выводу, что необходима таблица, которая будет обновляться в режиме реального времени и содержать записи следующего вида:
Проанализировав возможные решения, мы выбрали не на одну базу данных, а их комбинацию с небольшим дублированием данных. Сделали мы это потому, что издержки на дублирование данных были не сопоставимы с тем, какие возможности нам давала эта архитектура.

Первое решение — это платформа полнотекстового поиска Solr. Позволяет создавать распределенный индекс документов. Solr — популярное решение, имеющее большое количество документации и поддерживаемое в сервисе Cloudera. Однако работать с ним как с полноценной БД не получилось, мы решили добавить в архитектуру распределённую колоночную БД HBase.
В начале решили, что в Solr в качестве документа будет выступать user, в котором будет индексируемое поле keywords со всеми ключевыми словами. Но так как мы планировали удалять старые данные из таблицы, то решили в качестве документа использовать связку user+date, что стало полем User_id: то есть каждый документ должен хранить все ключевые слова пользователя за день. Такой подход позволяет удалять старые записи по TTL-индексу, а также строить аудитории с разной степенью «свежести». Поле Real_Id — настоящий id пользователя. Это поле используется для агрегации в запросах с указанной длительностью интереса.
Кстати, чтобы не хранить лишние данные в Solr, поле keywords сделали только индексируемым, что позволило нам существенно сократить объем хранимой информации. При этом сами ключевые слова, как вы уже поняли, можно достать из HBase.
Таким образом мы смогли сократить издержки, связанные с тяжёлыми запросами. Но это не все элементы, которые оказались нам необходимы и стали нашим фундаментом. В первую очередь мы нуждались в обработке больших объёмов данных на лету и тут как нельзя кстати пригодился Apache Spark с его streaming-функционалом. А в качестве очереди данных мы выбрали Apache Kafka, которая как нельзя лучше подошла для этой роли.
Теперь рабочая схема выглядит следующим образом:
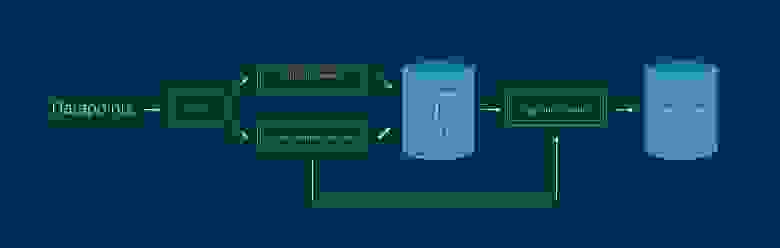
1. Из Kafka данные выбирают два процесса. Функционал очереди позволяет читать её нескольким независимым процессам, каждый из которых имеет свой курсор.
Особенностью PageIndexer является выбор ключевых слов со страницы, для разных типов страниц — разные наборы слов.
Работает на 1-2 серверах 32GB RAM Xeon E5-2620, скачивает 15-30К страниц в минуту. При этом выбирая из очереди 200-400К записей.
А основным достоинством VisitorActionReceiver, то что помимо добавления записей в Solr/HBase, данные так же пересылаются в Segment Builder и новые пользователи добавляются в аудитории в реальном времени.
100 ГБ. Solr занимает
250 млн записей TTL индекс 7 дней. (Все цифры без учёта репликации).
Коротко напомним основные элементы инфраструктуры:
Kafka — умная и устойчивая очередь, HBase — быстрая колоночная БД, Solr — давно зарекомендовавший себя поисковый движок, Spark — распределённые вычисления, включая streaming, а главное, всё это находится на HDFS, прекрасно масштабируется, мониторится и очень устойчиво. Работает в окружении Cloudera.

Заключение
Может показаться, что мы усложнили рабочую схему большим разнообразием инструментов. На самом деле мы пошли по пути наибольшего упрощения. Да, одну монгу мы поменяли на список сервисов, но все они работают в той нише, для которой и создавались.
Теперь Keyword Builder действительно отвечает всем требованиям рекламодателей и здравому смыслу. Аудитории в 2.5 млн людей создаются за 1-7 минут. Оценка размера аудитории происходит в реальном времени. Задействовано всего 8 серверов (i7-4770, 32GB RAM). Добавление серверов влечёт за собой линейный рост производительности.
А получившийся инструмент вы всегда можете попробовать в ретаргетинговой платформе Hybrid.
Выражаю горячую благодарность пользователю dcheklov, за помощь в создании статьи и наставлении на путь истинный =).
Тема DMP начата и остаётся открытой, ждите нас в следующих выпусках.
Сегмент на основе данных DMP
Вы можете создавать в Аудиториях сегменты на основе данных провайдеров (DMP — Data Management Platforms). Они хранят данные пользователей и сегментируют их по категориям, возрасту, интересам, используемым сервисам и т. д.
Описание : Aidata является уникальным игроком на российском рынке данных. Компания предоставляет клиентам технологический продукт, позволяющий работать с различными типами данных, дополняя и обогащая их собственными знаниями как из онлайн, так и офлайн источников. Основной отличительной чертой данных Aidata является полная прозрачность и возможность проследить их происхождение вплоть до конечного источника.
Описание : Weborama, основанная в Париже в 1998 году, является одним из признанных лидеров европейского рынка аудиторных данных. Инвестируя на протяжении многих лет в технологии и алгоритмы сбора, сегментации и активации данных о поведении пользователей онлайн и офлайн, Weborama располагает полным стеком технологических решений и необходимой экспертизой в области использования аудиторных данных в маркетинге. В России компания представлена с 2012 года и на данный момент сотрудничает с ведущими рекламодателями, крупнейшими коммуникационными группами и площадками.
Описание : Компания Navigine, основанная в 2011 году, предоставляет платформу для создания точных геолокационных сервисов, которые применяются для сбора аналитики, геопозиционного маркетинга и навигации внутри помещений. Уникальные запатентованные алгоритмы позволяют максимально точно определять местоположение пользователей мобильных устройств и собирать информацию об их поведении в офлайн мире, помогая измерять O2O-конверсии. Сервисы на базе платформы Navigine развернуты более чем в 500 локациях 20 стран мира.
Описание : AmberData — высокотехнологичная платформа управления данными для агрегации обезличенной информации о пользователях интернета и их сегментации. С помощью платформы AmberData рекламодатели и рекламные агентства смогут выстраивать максимально эффективные коммуникации с целевой аудиторией. Более 400 сегментов + построение сегментов по запросу. Ежедневное обновление данных по 600 млн + cookie.
Описание : CleverDATA — разработчик независимой технологической платформы 1DMC (Data Monetization Cloud, Биржа данных), объединяющей поставщиков и потребителей данных для обмена анонимными знаниями о своей аудитории. Используйте единую точку интеграции и подключайте более 20 «приватных» поставщиков данных. Используйте уникальные внешние данные для look-alike моделирования и увеличивайте доступную для кампаний аудиторию до 85М в сутки. Выбирайте аудиторию для показа персонализированных рекламных объявлений на основе точных знаний о профилях пользователей и увеличивайте отклик от рекламных кампаний.
Описание : Shopster собирает уникальные идентификаторы — MAC-адреса — телефонов, планшетов и других устройств, у которых включен модуль WiFi (не важно, подключен пользователь к сети или нет). Роутеры Shopster установлены в различных ТРЦ, магазинах, ресторанах, кафе, где проникновение включенного WiFi составляет около 30-40% от общего потока посетителей.
Описание : Soloway предлагает рекламодателям решения в области programmatic-маркетинга, построенные на базе собственных технологий. Независимая real-time DMP-платформа анализирует, обрабатывает и сегментирует более 430 миллионов кук в месяц. В таксономии сегментов Soloway представлены Аудиторные сегменты (доступная в медиапространстве Soloway аудитория, объединенная общим интересом, которая целенаправленно и регулярно посещает сайты и страницы определенной тематики) и Performance-модели (группы пользователей, объединенные общим намерением и высокой вероятностью совершить определенное целевое действие).
Описание : Aidata является уникальным игроком на российском рынке данных. Компания предоставляет клиентам технологический продукт, позволяющий работать с различными типами данных, дополняя и обогащая их собственными знаниями как из онлайн, так и офлайн источников. Основной отличительной чертой данных Aidata является полная прозрачность и возможность проследить их происхождение вплоть до конечного источника.
Описание : Weborama, основанная в Париже в 1998 году, является одним из признанных лидеров европейского рынка аудиторных данных. Инвестируя на протяжении многих лет в технологии и алгоритмы сбора, сегментации и активации данных о поведении пользователей онлайн и офлайн, Weborama располагает полным стеком технологических решений и необходимой экспертизой в области использования аудиторных данных в маркетинге. В России компания представлена с 2012 года и на данный момент сотрудничает с ведущими рекламодателями, крупнейшими коммуникационными группами и площадками.
Описание : Компания Navigine, основанная в 2011 году, предоставляет платформу для создания точных геолокационных сервисов, которые применяются для сбора аналитики, геопозиционного маркетинга и навигации внутри помещений. Уникальные запатентованные алгоритмы позволяют максимально точно определять местоположение пользователей мобильных устройств и собирать информацию об их поведении в офлайн мире, помогая измерять O2O-конверсии. Сервисы на базе платформы Navigine развернуты более чем в 500 локациях 20 стран мира.
Описание : AmberData — высокотехнологичная платформа управления данными для агрегации обезличенной информации о пользователях интернета и их сегментации. С помощью платформы AmberData рекламодатели и рекламные агентства смогут выстраивать максимально эффективные коммуникации с целевой аудиторией. Более 400 сегментов + построение сегментов по запросу. Ежедневное обновление данных по 600 млн + cookie.
Описание : CleverDATA — разработчик независимой технологической платформы 1DMC (Data Monetization Cloud, Биржа данных), объединяющей поставщиков и потребителей данных для обмена анонимными знаниями о своей аудитории. Используйте единую точку интеграции и подключайте более 20 «приватных» поставщиков данных. Используйте уникальные внешние данные для look-alike моделирования и увеличивайте доступную для кампаний аудиторию до 85М в сутки. Выбирайте аудиторию для показа персонализированных рекламных объявлений на основе точных знаний о профилях пользователей и увеличивайте отклик от рекламных кампаний.
Описание : Shopster собирает уникальные идентификаторы — MAC-адреса — телефонов, планшетов и других устройств, у которых включен модуль WiFi (не важно, подключен пользователь к сети или нет). Роутеры Shopster установлены в различных ТРЦ, магазинах, ресторанах, кафе, где проникновение включенного WiFi составляет около 30-40% от общего потока посетителей.
Описание : Soloway предлагает рекламодателям решения в области programmatic-маркетинга, построенные на базе собственных технологий. Независимая real-time DMP-платформа анализирует, обрабатывает и сегментирует более 430 миллионов кук в месяц. В таксономии сегментов Soloway представлены Аудиторные сегменты (доступная в медиапространстве Soloway аудитория, объединенная общим интересом, которая целенаправленно и регулярно посещает сайты и страницы определенной тематики) и Performance-модели (группы пользователей, объединенные общим намерением и высокой вероятностью совершить определенное целевое действие).
Чтобы найти нужный сегмент в списке, введите его название в строке поиска. Вы также можете отфильтровать сегменты по стоимости (CPM) в выбранной валюте и охвату. Отметьте галочкой сегменты, которые хотите добавить. Обратите внимание, что при выборе группы сегментов будут добавлены все вложенные в нее сегменты.
Вы можете использовать сегменты на основе данных DMP при настройке рекламы в ADFOX. В Яндекс.Директе можно использовать только бесплатные сегменты, к которым DMP предоставили вам доступ.
Data Management Platform — важнейший инструмент современного digital-маркетинга
Очередная статья из цикла «RTB Insight: информация для профессиональных интернет-маркетологов», которую специально для Cossa.ru подготовили создатели первой независимой российской Trading Desk и DMP Auditorius Геннадий Нагорнов и Валерий Кашин. Третий материал расскажет читателям о DMP (Data Management Platform) — краеугольном камне RTB.
Что такое DMP
Data Management Platform (DMP) — многофункциональная система, которая позволяет рекламодателям, агентствам, издателям и остальным сторонам хранить и систематизировать имеющиеся у них данные первого и второго порядка (first-party, second-party data) и дополнять их данными третьего порядка (third-party data).
Типы данных
Как продвинуть банк в регионах?
Основная проблема — перегретый аукцион. Но если грамотно выбрать соцсеть, формат и настройки таргетинга, всё получится.
DMP позволяет оптимизировать медиазакупки и планирование рекламных кампаний за счет поведенческих таргетингов или расширения аудитории через look-alike-моделирование (поиск пользователей, похожих на тех, которые уже стали клиентами). Рекламодатели и агентства обычно используют DMP для того, чтобы более эффективно покупать, в то время как для издателей DMP — это, в первую очередь, сегментация своей аудитории и более эффективная продажа своих данных.
Отличие DMP от Data Exchange
Data Exchange — это сбор и нормализация данных, а также привязка к профайлу пользователя. Если DMP в основном оперируют сегментами, то Data Exchange — это профили пользователей. Data Exchange хранят более «сырые» данные, нежели DMP, и в большем объеме. Data Exchange используются в основном DSP и SSP для дополнения и улучшения качества сегментов.
СТАТЬИ ПО ТЕМЕ
Экосистема российского RTB-рынка в 2013 году — материал рассказывает об устройстве рынка RTB: основных составляющих, механизмах, процессах и их участниках.
Словарь: Real-Time Bidding, DSP, SSP, Trading Desk, Ad Network, Ad Exchange, Data Suppliers, DMP, ретаргетинг.
Trading Desk — революция в управлении медийной рекламой — текст отвечает на вопросы, что такое модель Trading Desk, каковы ее преимущества и роль в экосистеме RTB, аспекты ее влияния на рынок медийной рекламы, роль на рынке.
Словарь: Trading Desk, источники данных, таргетинг, динамический креатив, ROI, RTB, агентские и независимые Trading Desk, Auditorius, DSP Hubrus.
Data — переворот в таргетировании медийной рекламы — cтатья рассказывает о том, как важны в современной рекламе данные (Data), а в частности — данные о пользователях (RTB Data), как эти данные классифицируются, собираются и используются. В статье также затрагиваются темы монетизации и защиты данных, влияния данных на рынок медийной рекламы.
Словарь: Big Data, дисплейная реклама, контекстная реклама, типы данных (first-party data, second-party data, third-party data), DMP (Data Management Platform), Data Exchanges, аудит данных, Data Mining.
Откуда DMP получают данные
Существует несколько моделей взаимодействия в зависимости от типа игрока:
Таким образом, все участники рынка формируют необходимое поле данных, которые бренды и рекламные агентства используют для своих нужд. Естественно, что данные первого и второго порядка закрыты от остальных участников рынка. Другое дело, что бренды могут делиться этой информацией с теми, кто не является их конкурентами, с целью обмена на другие новые данные или дополнительной монетизации активов. Но основные данные, которыми пользуются все — это данные третьего порядка, которые находятся в открытой продаже в рамках DMP и Data Exchanges.
Систематизация данных
Как происходит систематизация данных и их синхронизация с DMP, а также, какие возможности для рекламы она предоставляет?
Допустим, вы маркетолог ретейл-компании, и у вас есть база ваших лояльных клиентов, кому вы выдали персональные карточки постоянных клиентов. На текущий момент вы никак не можете с ними взаимодействовать в интернете (исключение: email-рассылка, ну или если вы собрали всех в вашей группе в соцсетях). Основная информация, которой вы обладаете, это база email-адресов, а также данные о покупках в CRM. Ваша задача — выйти за пределы рассылки и соцсетей для взаимодействия с вашими лояльными клиентами в интернете.
Здесь на помощь приходит DMP. Вы «вшиваете» пиксель в каждое письмо (как в ссылку, так и в картинку, в которой содержится номер карты), и при открытии письма в браузере или при переходе по ссылке вы синхронизируете cookie пользователя в базе DMP c ID базы и номером карты.
Но письма читают далеко не все. Что же делать, чтобы синхронизировать больше людей? Здесь на помощь приходят сервисы или акции, в которые необходимо вводить номер карты для активации аккаунта или регистрации. Сервисами пользуются большинство постоянных пользователях, а в акциях обычно участвуют большое количество человек. В общем, здесь вопрос механики: как организовать возможность сбора номеров карточек через интернет.
Если рассматривать базу постоянных клиентов в сотни тысяч, то успехом будет являться показатель в 30% синхронизированных пользователей. Если бизнес меньше, то процент конверсии необходимо увеличивать. Чем меньше аудитория, тем сложнее ее поймать в интернете.
После того, как вы синхронизировали достаточное количество пользователей — представителей вашей аудитории, вы можете проводить персонализированные рекламные кампании через протокол RTB на всех просторах интернета. Зная о том, какие потребительские предпочтения у вашей аудитории, вы можете делать обращения, которые будут вызывать повышенный отклик на рекламу.
Например, вы знаете, что пользователь все время покупает детское питание. И теперь вы можете показывать ему баннеры с акциями на детское питание, а также все товары, что относятся к разделу «товары для детей». Детское питание, кстати, категоризируется по возрастным группам — зная группу, вы можете делать подборки товаров максимально релевантными.
Или вы знаете, что пользователь не так давно купил у вас новый iPhone 5c синего цвета. И теперь вы можете показывать ему баннеры с аксессуарами именно для iPhone 5c. Вы можете даже подставлять цвет айфона, который купил пользователь, чтобы он больше был впечатлен примерами аксессуаров. Cкажем, можно подбирать бампер по цветовому сочетанию сiPhone.
Возможность определять пол позволяет показывать владельцам карт постоянного клиента релевантные товары в баннерах: мужчинам — брюки, девушкам — юбки. Также вы можете регулировать показы, используя два параметра: например, покупателю детского питания, который попадает в сегмент автолюбителей, вы можете показывать рекламу автоаксессуаров.
Преимущества DMP
Контроль данных, упрощенная система работы и безопасность
Data Management Platform предполагает полный контроль над вашими данными, как собственными (first-party data), так и косвенными (second-party data). Можно легко отказаться от плохого поставщика данных, который удерживает всю необходимую вам информацию. С помощью DMP работа над собранными данными становится проще: можно использовать их как угодно и для каких угодно целей. При этом ваши данные защищены как юридически, так и технически (при помощи зашифрованных соединений).
Грамотная сегментация всех данных, глубокое понимание ЦА
DMP позволяет собрать наиболее полные данные различных кампаний в одном месте. Подобное решение помогает понять, как разнообразные методы управления рекламными активностями влияют на конечный результат. Но главное достоинство — это переосмысление своей аудитории, углубление понимания того, на кого нацелена реклама. Кроме first-party data и second-party data существует и данные третьей стороны. Их привлечение через Data Exchange и покупка у самой платформы позволяют сегментировать целевую аудиторию, посмотреть на нее под иным углом, что, однозначно, увеличивает общие показатели рекламных кампаний.
Анализ аудитории
Благодаря возможностям DMP можно провести audience analytics (анализ аудитории) на основе данных внешних поставщиков. Это существенно увеличит результативность показов, так как благодаря собранным данным возможно более точное таргетирование конечного пользователя, более глубокая персонализация сообщений.
Как использовать DMP
Рекламодателям
Агентствам
Паблишерам
Типы спецификаций DMP на Западе
На рынке существует несколько типов DMP-систем, каждая из которых подходит под определенные цели и задачи. Так как это развивающийся рынок и поведение игроков на нем динамично, то мы выделим следующие типы, которые могу перетекать один в другой в зависимости от выбранной бизнес-модели той или иной DMP. Итак, существуют следующие виды платформ для управления данными:
ОБЗОР КРУПНЕЙШИХ ИГРОКОВ ОТЕЧЕСТВЕННОГО РЫНКА DMP
Место DMP на современном маркетинговом рынке
Нужно признать, маркетинг в последнее время (да и в исторической плоскости) — это применение в рамках заданной стратегии данных, полученных разными путями. Многие сейчас говорят о «big data». Однако «большие данные» были всегда, а применять в таком глобальном масштабе и с такими возможностями мы их можем только сейчас. В основном благодаря DMP — платформам по управлению данными. Существующие на рынке системы обрастают новым функционалом и всячески стараются найти свой собственный путь в освоении больших объемов данных от брендов, рекламных агентств, онлайн-магазинов, интернет-провайдеров и пр. Использование DMP как определяющего инструмента в рамках ближайших 5–10 лет станет ключевым преимуществом. И если вы по каким-либо своим причинам забросили это направление, то, возможно, через пару лет вы безнадежно отстанете от равной конкурентной борьбы.
