Национальная библиотека им. Н. Э. Баумана
Bauman National Library
Персональные инструменты
Шардирование баз данных
Шардирование (горизонтальное партиционирование) — это принцип проектирования базы данных, при котором логически независимые строки таблицы базы данных хранятся раздельно, заранее сгруппированные в секции, которые, в свою очередь, размещаются на разных, физически и логически независимых серверах базы данных, при этом один физический узел кластера может содержать несколько серверов баз данных. Наиболее типовым методом горизонтального партицирования является применение хеш функции от идентификационных данных клиента, которая позволяет однозначно привязать заданного клиента и все его данные к отдельному и заранее известному экземпляру баз данных («шарду»), тем самым обеспечив практически неограниченную от количества клиентов горизонтальную масштабируемость.
Этот подход принципиально отличается от вертикального масштабирования, которое при росте нагрузки и объёма данных предусматривает наращивание вычислительных возможностей и объёма носителей информации одного сервера баз данных, имеющее объективные физические пределы — максимальное количество поддерживаемых CPU на один сервер, максимальный поддерживаемый объем памяти, пропускная способность шины и т. д.
Шардирование обеспечивает несколько преимуществ, главное из которых — снижение издержек на обеспечение согласованного чтения (которое для ряда низкоуровневых операций требует монополизации ресурсов сервера баз данных, внося ограничения на количество одновременно обрабатываемых пользовательских запросов, вне зависимости от вычислительной мощности используемого оборудования). В случае шардинга логически независимые серверы баз данных не требуют взаимной монопольной блокировки для обеспечения согласованного чтения, тем самым снимая ограничения на количество одновременно обрабатываемых пользовательских запросов в кластере в целом.
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
Критерий шардинга — какой-то параметр, который позволит определять, на каком именно сервере лежат те или иные данные.
Содержание
Подход с применением шардирования баз данных
Шардинг и репликация
Репликация
Репликация — это синхронное или асинхронное копирование данных между несколькими серверами. Ведущие сервера называют мастерами (master), а ведомые сервера — слэйвами (slave). Мастера используются для изменения данных, а слэйвы — для считывания. В классической схеме репликации обычно один мастер и несколько слэйвов, так как в большей части веб-проектов операций чтения на несколько порядков больше, чем операций записи. Однако в более сложной схеме репликации может быть и несколько мастеров.
Шардинг
Шардинг — это прием, который позволяет распределять данные между разными физическими серверами. Процесс шардинга предполагает разнесения данных между отдельными шардами на основе некого ключа шардинга. Связанные одинаковым значением ключа шардинга сущности группируются в набор данных по заданному ключу, а этот набор хранится в пределах одного физического шарда. Это существенно облегчает обработку данных.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
SQL Azure Federations
Если приложение использует базы данных MS SQL, возникает несколько вопросов. Конечно первое что приходит в голову — организовать кластер из виртуальных машин SQL Server. Решение достаточно простое и хорошо всем знакомое. А что делать, если приложение использует базу данных как сервис (SaaS)? Что если мы не хотим заниматься настройкой кластера SQL Server? Конечно же, если мы говорим о Windows Azure, то в качестве SQL базы данных будет использоваться SQL Azure. Эта база данных поддерживает технологию горизонтального масштабирования (шардинг) называемую SQL Azure Federations. Принцип ее работы очень простой: логически независимые друг от друга строки одной таблицы хранятся в разных базах данных.
Ограничения SQL Azure
Что это дает: во-первых, изоляцию данных друг от друга. Данные одного аккаунта никак не связаны с данными другого. Соответственно, применением технологии шардинга мы можем реализовать не только горизонтальное масштабирование базы данных, но и multi-tenant сценарий.
Увеличивается скорость выборки данных из базы, поскольку сам размер хранящихся в конкретном шарде данных на порядок меньше, чем суммарный объем базы. Однако, в любой технологии есть свои недостатки. Шардинг не исключение. Если вспомнить, архитектуру SQL Azure, то как известно сервис не поддерживает выборку данных из нескольких баз данных одновременно. То есть одна база данных — одно соединение. И шарды — не исключение. То есть, если допустим простейший запрос на возврат количества клиентов в базе данных необходимо выполнить на каждом шарде отдельно.
Пример запроса для конкретного шарда:
Логику же суммирования значений, возвращаемых этим запросом необходимо размещать в приложении. То есть в результате использования федераций часть кода «уйдет» в приложение, поскольку на уровне базы данных некоторые возможности обычного SQL Server ограничены.
Конечно SQL Azure Federations не является панацеей и можно реализовать свой принцип горизонтального масштабирования баз данных. Допустим multi-tenant подход — тоже своего рода горизонтальное масштабирование базы данных. Поскольку данные одного пользователя отделены не только «логически» от данных другого пользователя, но и «физически». Если необходимо добавить нового пользователя — мы конфигурируем для него отдельную базу данных. Вопрос в том, что в логике приложения должен быть механизм «роутинга». То есть приложение должно знать с какой базой данных оно в данный момент работает.
Сама задумка компании Microsoft хорошая. Было бы неплохо получить инструмент позволяющий легко масштабировать базу данных. Однако как правило, перед принятием окончательного решения перейти к использованию SQL Azure Federations, необходимо тщательно провести анализ существующей базы данных, либо продумать до мельчайших деталей архитектуру базы данных, которую будет использовать приложение, а также саму логику приложения по работе с этой базой.
Серверы баз данных, поддерживающие шардирование:
MongoDB поддерживает шардирование с версии 1.6.
Grails поддерживает шардирование путем Grails Sharding Plugin.
Redis база данных с поддержкой шардирования на стороне клиента.
Microsoft поддерживает шардирование в SQL Azure через «федерации».
Практически любой сервер баз данных может быть использован по схеме шардинга, при реализации соответствующего уровня абстракции на стороне клиента. К примеру eBay применяет серверы Oracle в режиме шардинга[1], Facebook[2] и Twitter[3] применяют шардирование поверх MySQL и т. д.
Шардинг и репликация



Масштабирование баз данных — самая сложная задача во время роста проекта. 90% всех усилий обычно приходится как раз на работу, связанную с ростом объема данных и операций с ними. Классическая схема работы приложения с базой данных выглядит так: 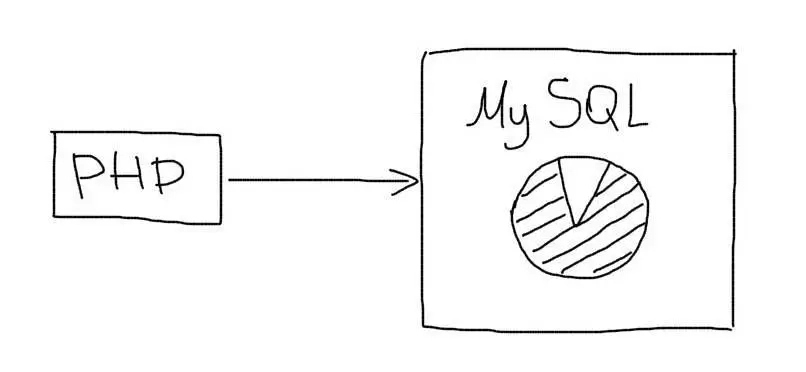
Один сервер базы данных в какой-то момент перестает справляться с нагрузкой. В этот момент и следует применять описанные тут техники масштабирования.
Перед тем, как приступать к масштабированию, необходимо провести анализ медленных запросов и убедиться, что сервер MySQL настроен оптимально.
Стратегии
В основе масштабирования данных лежит тот же принцип, что и в основе масштабирования Web приложений. Это разделение данных на группы и выделение их на отдельные сервера. Существует две основные стратегии — репликация и шардинг.
Репликация
Репликация позволяет создать полный дубликат базы данных. Так, вместо одного сервера у Вас их будет несколько: 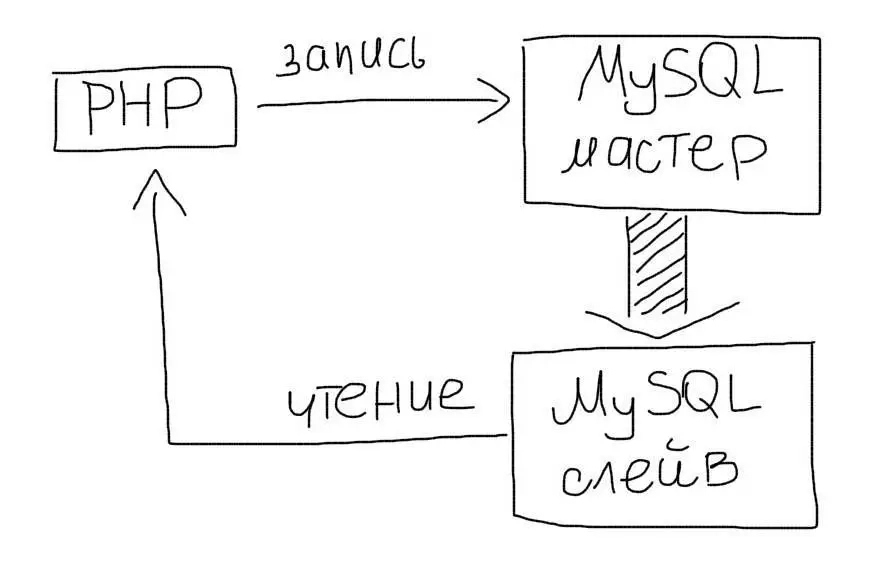
Master-slave
Чаще всего используют схему master-slave:
Репликация позволяет использовать два или больше одинаковых серверов вместо одного. Операций чтения (SELECT) данных часто намного больше, чем операций изменения данных (INSERT/UPDATE). Поэтому, репликация позволяет разгрузить основной сервер за счет переноса операций чтения на слейв.
Работа из приложения
В приложении у Вас будет два соединения с базой данных. Одно — для мастера и одно для слейва:
При выполнении запросов необходимо использовать соответствующее соединение
Репликация обычно поддерживается самой СУБД (например, MySQL) и настраивается независимо от приложения.
Читайте детальнее про настройку, использование и типы репликации данных на примере MySQL.
Следует отметить, что репликация сама по себе не очень удобный механизм масштабирования. Причиной тому — рассинхронизация данных и задержки в копировании с мастера на слейв. Зато это отличное средство для обеспечения отказоустойчивости. Вы всегда можете переключиться на слейв, если мастер ломается и наоборот. Чаще всего репликация используется совместно с шардингом именно из соображений надежности.
Шардинг (sharding)
Шардинг (иногда шардирование) — это другая техника масштабирования работы с данными. Суть его в разделении (партиционирование) базы данных на отдельные части так, чтобы каждую из них можно было вынести на отдельный сервер. Этот процесс зависит от структуры Вашей базы данных и выполняется прямо в приложении в отличие от репликации: 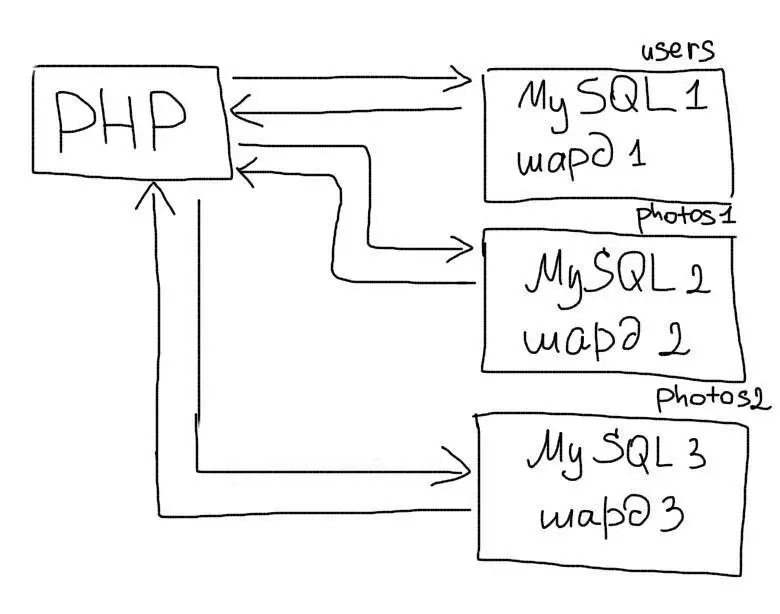
Вертикальный шардинг
Вертикальный шардинг — это выделение таблицы или группы таблиц на отдельный сервер. Например, в приложении есть такие таблицы:
Таблицу users Вы оставляете на одном сервере, а таблицы photos и albums переносите на другой. В таком случае в приложении Вам необходимо будет использовать соответствующее соединение для работы с каждой таблицей:
Для каждой таблицы или группы таблиц будет отдельное соединение
В отличие от репликации, мы используем разные соединения для любых операций, но с определенными таблицами. Читайте подробнее об использовании вертикального шардинга на практике.
Горизонтальный шардинг
Горизонтальный шардинг — это разделение одной таблицы на разные сервера. Это необходимо использовать для огромных таблиц, которые не умещаются на одном сервере. Разделение таблицы на куски делается по такому принципу:
Допустим, наше приложение работает с огромной таблицей, которая хранит фотографии пользователей. Мы подготовили два сервера (обычно они называются шардами) для этой таблицы. Для нечетных пользователей мы будем работать с первыми сервером, а для четных — со вторым. Таким образом, на каждом из серверов будет только часть всех данных о фотках пользователей. Это будет выглядеть так:
Перед обращением к таблице, мы выбираем нужное нам соединение
Горизонтальный шардинг — это очень мощный инструмент масштабирования данных. Но в то же время и очень нетривиальный. Читайте детально об использовании горизонтального шардинга на практике.
Не следует применять технику шардинга ко всем таблицам. Правильный подход — это поэтапный процесс разделения растущих таблиц. Следует задумываться о горизонтальном шардинге, когда количество записей в одной таблице переходит за пределы от нескольких десятков миллионов до сотен миллионов.
Совместное использование
Шардинг и репликация часто используются совместно. В нашем примере, мы могли бы использовать по два сервера на каждый шард таблицы:
Тогда в приложении работа с этой табличкой может выглядеть так:
Читаем данные со слейвов, а записываем на мастер-сервера
Такая схема часто используется не для масштабирования, а для обеспечения отказоустойчивости. Так, при выходе из строя одного из серверов шарда, всегда будет запасной.
Key-value базы данных
Следует отметить, что большинство [p165 Key-value баз данных] поддерживает шардинг на уровне платформы. Например, Memcache. В таком случае, Вы просто указываете набор серверов для соединения, а платформа сделает все остальное:
Мемкеш сам умеет определять нужный сервер для каждого ключа
Самое важное
Шардинг и репликация — это популярные и мощные техники масштабирования систем работы с данными. Несмотря на примеры для MySQL, эти подходы универсальны и могут применяться для любой технологии.
Помните, процесс масштабирования данных — это архитектурное решение, оно не связано с конкретной технологией. Не делайте ошибок наших отцов — не переезжайте с известной Вам технологии на новую из-за поддержки или не поддержки шардинга. Проблемы обычно связаны с архитектурой, а не конкретной базой данных.
Этот текст был написан несколько лет назад. С тех пор упомянутые здесь инструменты и софт могли получить обновления. Пожалуйста, проверяйте их актуальность.
Что такое индексы в Mysql и как их использовать для оптимизации запросов
Как исправить ошибку доступа к базе 1045 Access denied for user
Настройка Master-Master репликации на MySQL за 6 шагов
Примеры ad-hoc запросов и технологии для их исполнения
Анализ медленных запросов (профилирование) в MySQL с помощью Percona Toolkit
Как создать и использовать составной индекс в Mysql
Типы и способы применения репликации на примере MySQL
Синтаксис и оптимизация Mysql LIMIT
Настройка Master-Slave репликации на MySQL за 6 простых шагов
Правильная настройка Mysql под нагрузки и не только. Обновлено.
И как правильно работать с длительными соединениями в MySQL
Check-unused-keys для определения неиспользуемых индексов в базе данных
Запрос для определения версии Mysql: SELECT version()
3 примера установки индексов в JOIN запросах
Анализ медленных запросов с помощью EXPLAIN
Что значит и как это починить
Описание, рекомендации и значение параметра query_cache_size
Быстрый подсчет уникальных значений за разные периоды времени
Использование партиций для ускорения сложных удалений
Правила выбора типов данных для максимальной производительности в Mysql
Включение и использование логов ошибок, запросов и медленных запросов, бинарного лога для проверки работы MySQL
Принципы шардинга реляционных баз данных

Когда ваша база данных небольшая (10 ГБ), вы можете легко добавить больше ресурсов и таким образом масштабировать ее. Однако, поскольку таблицы растут, нужно подумать и о других способах масштабирования базы данных.
С одной стороны шардинг — лучший способ масштабирования. Он позволяет линейно масштабировать ресурсы базы данных, памяти и диска, дробя базу данных на более мелкие части. С другой стороны целесообразность использования шаринга — спорная тема. Интернет полон советов по шардингу, от «масштабирования инфраструктуры базы данных» до «почему вы никогда не используете шардинг». Итак, вопрос в том, какую сторону принять.
Всегда, когда возникал вопрос шардинга, ответ был «раз на раз не приходится». Теория шардинга проста: выберите один ключ (столбец), который равномерно распределяет данные. Убедитесь, что большинство запросов могут быть решены с помощью этого ключа. Эта теория проста, но только до того момента, пока вы не приступите к практике.
В Citus мы помогли сотням команд, когда они обращались к шардингу баз данных. С получением опыта мы обнаружили, что имеются ключевые шаблоны.
В этой статье мы сначала рассмотрим ключевые параметры, которые влияют на успех шардинга, а затем раскроем основную причину, по которой мнения о шардинге столь разные. Когда дело доходит до шардинга базы данных, на успех в большей степени влияет тип приложения, которое вы создаете.
3 ключевых параметра успешности шардинга
На успех шардинга базы данных влияют 3 ключевых параметра. На диаграмме они показаны на трех осях, а также приведены примеры известных компаний.

Ось X на диаграмме показывает тип рабочей нагрузки. Эта ось начинается с транзакционных нагрузок слева и продолжается организацией хранилищ данных. Изменения этой оси более заметны при шардинге.
Ось Z демонстрирует еще один важный параметр — нахождение в жизненном цикле приложения. Сколько таблиц у вас есть в базе данных (10, 100, 1000) или как долго приложение находится в производстве? Приложение, запущенное на PostgreSQL в течение нескольких месяцев, будет легче шардироваться, чем приложение, которое было в производстве в течение многих лет.
В Citus мы обнаружили, что большинство пользователей имеют достаточно развитые приложения. Когда приложение развито, ось У становится критической. К сожалению, изменения этой оси не так заметны, как изменения остальных осей. Фактически большинство статей, которые противоречат выводам о фрагментации, предоставляют свои рекомендации в контексте одного типа приложения.
Что имеет наибольшее значение в шардинге: тип приложения (B2B или B2C)
Ось У на диаграмме показывает наиболее важный параметр при шардинге баз данных — тип приложения. В верхней части этой оси находятся приложения B2B, модели данных которых более удобны для фрагментации. В нижней части этой оси — приложения B2C, такие как Amazon и Facebook, которые требуют больше работы. Далее мы расскажем о различиях трех известных компаний.
B2B Example: Salesforce
Хорошим примером приложения для B2B является программное обеспечение CRM. Когда вы создаете CRM-приложение, такое как Salesforce, ваше приложение будет обслуживать других клиентов. Например, компания GE Aviation будет одним из ваших клиентов, использующих Salesforce.
В GE Aviation есть пользователи, которые входят в свою панель мониторинга компании. GE также фиксирует:
потенциальных клиентов, с которыми они могут вести бизнес,
контакты/людей, которые уже известны и с которыми установлены деловые отношения,
счета, которые представляют бизнес-единицы и у которых есть работающие на них контакты,
возможности, которые являются событиями продаж, связанными с учетной записью и одного или нескольких контактов.
Сопоставление этих сложных соотношений выглядит следующим образом:
График выглядит сложным. Но изучив график, можно заметить, что большинство таблиц происходит из таблицы клиентов. Графы можно преобразовать, добавив столбец customer_id ко всем таблицам.
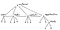
С помощью этого простого преобразования у базы данных теперь есть хороший ключ оглавления: customer_id. Он равномерно распределяет данные, и большинство запросов к базе данных будут включать ключ клиента. Кроме того, вы можете размещать таблицы в client_id и продолжать использовать ключевые функции реляционной базы данных, такие как транзакция, объединение таблиц и ограничение внешнего ключа.
Другими словами, если у вас есть приложение B2B, характер ваших данных дает вам фундаментальное преимущество при шардинге.
Пример B2C: Amazon.com
Amazon.com — хороший пример расширенного приложения B2C. Если бы вы строили сайт Amazon.com сегодня, у вас было бы несколько концепций для рассмотрения. Во-первых, пользователь приходит на ваш сайт и начинает смотреть продукты: книги, электронику. Когда пользователь посещает страницу продукта, скажем, Harry Potter 7, он видит информацию каталога, связанную с этим продуктом. Пример информации о каталоге включает автора, цену, обложку и другие изображения.
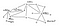
Когда пользователь регистрируется на веб-сайте, он получает доступ к данным, связанным с пользователем. Пользователь должен быть аутентифицирован, может писать отзывы о любимых продуктах и добавлять элементы в корзину покупок. В какой-то момент пользователь решает сделать покупку и размещает заказ. Заказ обрабатывается, забирается со склада и отправляется.
При сопоставлении отношений в реляционнной базе данных вы обнаружите, что они отличаются от примера Salesforce одной важной чертой. У вас нет единого измерения, которое является центром всех отношений, а есть как минимум три: каталог, пользователь и данные заказа.
При фрагментации данных типа B2C один из вариантов заключается в преобразовании приложения в микросервисы. Например, есть связанные службы каталога, которые владеют каталогом и предлагают данные, а также связанные с пользователем службы, которые владеют данными корзины проверки подлинности и покупок. API-интерфейсы между службами определяют границы доступа к базам данным.
При создании такого разделения между данными можно шардировать данные, которые предоставляют каждую услугу или группу услуг отдельно. Фактически Amazon.com использовал аналогичный подход к шардингу, когда перешел на сервис-ориентированную архитектуру.
Такой подход к очертаниям имеет более выгодное соотношение затрат и стоимости, чем шардинг приложения B2B. Что касается преимуществ, при разделении данных на группы таким образом можно полагаться на базу данных для объединения данных из разных источников или обеспечения транзакций и ограничений для групп данных. Со стороны затрат теперь нужно очертить не одну, а несколько групп данных.
Пример B2C2C: Instacart
Подкатегория, которая находится между B2B и B2C, включает такие приложения, как Postmates, Instacart или Lyft. Например, Instacart доставляет продукты пользователям из местных магазинов. В некотором смысле Instacart похож на пример Amazon.com. Instacart имеет три основных габаритных поля: местные магазины (предлагают продукты), пользователи (заказывают продукты) и водители (доставляют продукты). Таким образом, трудно выбрать один ключ, на котором можно очертить базу данных.
Если у вас есть расширенные приложения B2C2C, такие как Instacart, вы можете следовать другой стратегии. Большинство таблиц базы данных имеют другое измерение: география. В этом случае вы можете выбрать город или местоположение в качестве своего ключа и очертить таблицы по ключу географии.
В общем, шардинг приложений B2B2C / B2C2C находится в середине спектра. Шардинг для B2B2C имеет тенденцию к более высокому соотношению выгод и затрат, чем шардинг приложений B2C, и более низкое, чем приложения B2B.
Мнения о шардинге
Интернет полон мнений о шардинге. Мы обнаружили, что большинство этих мнений формируются с учетом одного типа приложения. Фактически тип приложения (B2B или B2C) влияет на успех более всего. В частности, если у вас приложение для B2B, то вам будет легче шардировать реляционную базу данных.
При планировании масштабирования базы данных нужно иметь полное представление об этом процесcе и оценить все параметры с учетом требований проекта.
Масштабирование базы данных через шардирование и партиционирование

Масштабирование базы данных через шардирование и партиционирование
Денис Иванов (2ГИС)
Всем привет! Меня зовут Денис Иванов, и я расскажу о масштабировании баз данных через шардирование и партиционирование. После этого доклада у всех должно появиться желание что-то попартицировать, пошардировать, вы поймете, что это очень просто, оно никак жрать не просит, работает, и все замечательно.
Немного расскажу о себе — я работаю в команде WebAPI в компании 2GIS, мы предоставляем API для организаций, у нас очень много разных данных, 8 стран, в которых мы работаем, 250 крупных городов, 50 тыс. населенных пунктов. У нас достаточно большая нагрузка — 25 млн. активных пользователей в месяц, и в среднем нагрузка около 2000 RPS идет на API. Все это располагается в трех датацентрах.
Перейдем к проблемам, которые мы с вами сегодня будем решать. Одна из проблем — это большое количество данных. Когда вы разрабатываете тот или иной проект, у вас в любой момент времени может случиться так, что данных становится очень много. Если бизнес работает, он приносит деньги. Соответственно, данных больше, денег больше, и с этими данными что-то нужно делать, потому что эти запросы очень долго начинают выполняться, и у нас сервер начинает не вывозить. Одно из решений, что с этими данными делать — это масштабирование базы данных.
Я в большей степени расскажу про шардинг. Он бывает вертикальным и горизонтальным. Также бывает такой способ масштабирования как репликация. Доклад «Как устроена MySQL репликация» Андрея Аксенова из Sphinx про это и был. Я эту тему практически не буду освещать.
Перейдем подробнее к теме партицирования (вертикальный шардинг). Как это все выглядит?

У нас есть большая таблица, например, с пользователями — у нас очень много пользователей. Партицирование — это когда мы одну большую таблицу разделяем на много маленьких по какому-либо принципу.
С горизонтальным шардингом все примерно так же, но при этом у нас таблички лежат в разных базах на других инстансах.
Единственное отличие горизонтального масштабирования от вертикального в том, что горизонтальное масштабирование будет разносить данные по разным инстансам.
Про репликацию я не буду останавливаться, тут все очень просто.
Перейдем глубже к этой теме, и я расскажу практически все о партицировании на примере Postgres’а.
Давайте рассмотрим простую табличку, наверняка, практически в 99% проектов такая табличка есть — это новости.
У новости есть идентификатор, есть категория, в которой эта новость расположена, есть автор новости, ее рейтинг и какой-то заголовок — совершенно стандартная таблица, ничего сложного нет.
Как же эту таблицу разделить на несколько? С чего начать?
Всего нужно будет сделать 2 действия над табличкой — это поставить у нашего шарда, например, news_1, то, что она будет наследоваться таблицей news. News будет базовой таблицей, будет содержать всю структуру, и мы, создавая партицию, будем указывать, что она наследуется нашей базовой таблицей. Наследованная таблица будет иметь все колонки родителя — той базовой таблицы, которую мы указали, а также она может иметь свои колонки, которые мы дополнительно туда добавим. Она будет полноценной таблицей, но унаследованной от родителя, и там не будет ограничений, индексов и триггеров от родителя — это очень важно. Если вы на базовой таблице насоздаете индексы и унаследуете ее, то в унаследованной таблице индексов, ограничений и триггеров не будет.
2-ое действие, которое нужно сделать — это поставить ограничения. Это будет проверка, что в эту таблицу будут попадать данные только вот с таким признаком.
В данном случае признак — это category_id=1, т.е. только записи с category_id=1 будут попадать в эту таблицу.
Какие типы проверок бывают для партицированных таблиц?
Бывает строгое значение, т.е. у нас какое-то поле четко равно какому-то полю. Бывает список значений — это вхождение в список, например, у нас может быть 3 автора новости именно в этой партиции, и бывает диапазон значений — это от какого и до какого значения данные будут храниться.
Тут нужно подробнее остановиться, потому что проверка поддерживает оператор BETWEEN, наверняка вы все его знаете.
И так просто его сделать можно. Но нельзя. Можно сделать, потому что нам разрешат такое сделать, PostgreSQL поддерживает такое. Как вы видите, у нас в 1-ую партицию попадают данные между 100 и 200, а во 2-ую — между 200 и 300. В какую из этих партиций попадет запись с рейтингом 200? Не известно, как повезет. Поэтому так делать нельзя, нужно указывать строгое значение, т.е. строго в 1-ую партицию будут попадать значения больше 100 и меньше либо равно 200, и во вторую больше 200, но не 200, и меньше либо равно 300.
Это обязательно нужно запомнить и так не делать, потому что вы не узнаете, в какую из партиций данные попадут. Нужно четко прописывать все условия проверки.
Также не стоит создавать партиции по разным полям, т.е. что в 1-ую партицию у нас будут попадать записи с category_id=1, а во 2-ую — с рейтингом 100.
Опять же, если нам придет такая запись, в которой category_id = 1 и рейтинг =100, то неизвестно в какую из партиций попадет эта запись. Партицировать стоит по одному признаку, по какому-то одному полю — это очень важно.
Давайте рассмотрим нашу партицию целиком:
Ваша партицированная таблица будет выглядеть вот так, т.е. это таблица news_1 с признаком, что туда будут попадать записи только с category_id = 1, и эта таблица будет унаследована от базовой таблицы news — все очень просто.
Мы на базовую таблицу должны добавить некоторое правило, чтобы, когда мы будем работать с нашей основной таблицей news, вставка на запись с category_id = 1 попала именно в ту партицию, а не в основную. Мы указываем простое правило, называем его как хотим, говорим, что когда данные будут вставляться в news с category_id = 1, вместо этого будем вставлять данные в news_1. Тут тоже все очень просто: по шаблончику оно все меняется и будет замечательно работать. Это правило создается на базовой таблице.
Таким образом мы заводим нужное нам количество партиций. Для примера я буду использовать 2 партиции, чтобы было проще. Т.е. у нас все одинаково, кроме наименований этой таблицы и условия, по которому данные будут туда попадать. Мы также заводим соответствующие правила по шаблону на каждую из таблиц.
Давайте рассмотрим пример вставки данных:
Данные будем вставлять как обычно, будто у нас обычная большая толстая таблица, т.е. мы вставляем запись с category_id=1 с category_id=2, можем даже вставить данные с category_id=3.
Вот мы выбираем данные, у нас они все есть:
Все, которые мы вставляли, несмотря на то, что 3-ей партиции у нас нет, но данные есть. В этом, может быть, есть немного магии, но на самом деле нет.
Мы также можем сделать соответствующие запросы в определенные партиции, указывая наше условие, т.е.category_id = 1, или вхождение в числа (2, 3).
Все будет замечательно работать, все данные будут выбираться. Опять же, несмотря на то, что с партиции с category_id=3 у нас нет.
Мы можем выбирать данные напрямую из партиций — это будет то же самое, что в предыдущем примере, но мы четко указываем нужную нам партицию. Когда у нас стоит точное условие на то, что нам именно из этой партиции нужно выбрать данные, мы можем напрямую указать именно эту партицию и не ходить в другие. Но у нас нет 3-ей партиции, а данные попадут в основную таблицу.
Хоть у нас и применено партицирование к этой таблице, основная таблица все равно существует. Она настоящая таблица, она может хранить данные, и с помощью оператора ONLY можно выбрать данные только из этой таблицы, и мы можем найти, что эта запись здесь спряталась.
Здесь можно, как видно на слайде, вставлять данные напрямую в партицию. Можно вставлять данные с помощью правил в основную таблицу, но можно и в саму партицию.
Если мы будем вставлять данные в партицию с каким-то чужеродным условием, например, с category_id = 4, то мы получим ошибку «сюда такие данные нельзя вставлять» — это тоже очень удобно — мы просто будем класть данные только в те партиции, которые нам действительно нужно, и если у нас что-то пойдет не так, мы на уровне базы все это отловим.
Тут пример побольше. Можно bulk_insert использовать, т.е. вставлять несколько записей одновременно и они все сами распределятся с помощью правил нужной партиции. Т.е. мы можем вообще не заморачиваться, просто работать с нашей таблицей, как мы раньше и работали. Приложение продолжит работать, но при этом данные будут попадать в партиции, все это будет красиво разложено по полочкам без нашего участия.
Напомню, что мы можем выбирать данные как из основной таблицы с указанием условия, можем, не указывая это условие выбирать данные из партиции. Как это выглядит со стороны explain’а:
У нас будет Seq Scan по всей таблице целиком, потому что туда данные могут все равно попадать, и будет скан по партиции. Если мы будем указывать условия нескольких категорий, то он будет сканировать только те таблицы, на которые есть условия. Он не будет смотреть в остальные партиции. Так работает оптимизатор — это правильно, и так действительно быстрее.
Мы можем посмотреть, как будет выглядеть explain на самой партиции.
Это будет обычная таблица, просто Seq Scan по ней, ничего сверхъестественного. Точно так же будут работать update’ы и delete’ы. Мы можем update’тить основную таблицу, можем также update’ы слать напрямую в партиции. Так же и delete’ы будут работать. На них нужно так же соответствующие правила создать, как мы создавали с insert’ом, только вместо insert написать update или delete.
Перейдем к такой вещи как Index’ы
Индексы, созданные на основной таблице, не будут унаследованы в дочерней таблице нашей партиции. Это грустно, но придется заводить одинаковые индексы на всех партициях. С этим есть что поделать, но придется заводить все индексы, все ограничения, все триггеры дублировать на все таблицы.
Как мы с этой проблемой боролись у себя. Мы создали замечательную утилиту PartitionMagic, которая позволяет автоматически управлять партициями и не заморачиваться с созданием индексов, триггеров с несуществующими партициями, с какими-то бяками, которые могут происходить. Эта утилита open source’ная, ниже будет ссылка. Мы эту утилиту в виде хранимой процедуры добавляем к нам в базу, она там лежит, не требует дополнительных extension’ов, никаких расширений, ничего пересобирать не нужно, т.е. мы берем PostgreSQL, обычную процедуру, запихиваем в базу и с ней работаем.
Вот та же самая таблица, которую мы рассматривали, ничего нового, все то же самое.
Как же нам запартицировать ее? А просто вот так:
Мы вызываем процедуру, указываем, что таблица будет news, и партицировать будем по category_id. И все дальше будет само работать, нам больше ничего не нужно делать. Мы так же вставляем данные.
У нас тут три записи с category_id =1, две записи с category_id=2, и одна с category_id=3.
После вставки данные автоматически попадут в нужные партиции, мы можем сделать селекты.
Все, партиции уже создались, все данные разложились по полочкам, все замечательно работает.
Какие мы получаем за счет этого преимущества:
Перейдем ко второй части доклада — это горизонтальный шардинг. Напомню, что горизонтальный шардинг — это когда мы данные разносим по нескольким серверам. Все это делается тоже достаточно просто, стоит один раз это настроить, и оно будет работать замечательно. Я расскажу подробнее, как это можно сделать.
Рассматривать будем такую же структуру с двумя шардами — news_1 и news_2, но это будут разные инстансы, третьим инстансом будет основная база, с которой мы будем работать:
Та же самая таблица:
Единственное, что туда нужно добавить, это CONSTRAINT CHECK, того, что записи будут выпадать только с category_id=1. Так же, как в предыдущем примере, но это не унаследованная таблица, это будет таблица с шардом, которую мы делаем на сервере, который будет выступать шардом с category_id=1. Это нужно запомнить. Единственное, что нужно сделать — это добавить CONSTRAINT.
Мы еще можем дополнительно создать индекс по category_id:
Несмотря на то, что у нас стоит check — проверка, PostgreSQL все равно обращается в этот шард, и шард может очень надолго задуматься, потому что данных может быть очень много, а в случае с индексом он быстро ответит, потому что в индексе ничего нет по такому запросу, поэтому его лучше добавить.
Как настроить шардинг на основном сервере?
Мы подключаем EXTENSION. EXTENSION идет в Postgres’e из коробки, делается это командой CREATE EXTENSION, называется он postgres_fdw, расшифровывается как foreign data wrapper.
Далее нам нужно завести удаленный сервер, подключить его к основному, мы называем его как угодно, указываем, что этот сервер будет использовать foreign data wrapper, который мы указали.
Таким же образом можно использовать для шарда MySql, Oracle, Mongo… Foreign data wrapper есть для очень многих баз данных, т.е. можно отдельные шарды хранить в разных базах.
В опции мы добавляем хост, порт и имя базы, с которой будем работать, нужно просто указать адрес вашего сервера, порт (скорее всего, он будет стандартный) и базу, которую мы завели.
Далее мы создаем маппинг для пользователя — по этим данным основной сервер будет авторизироваться к дочернему. Мы указываем, что для сервера news_1 будет пользователь postgres, с паролем postgres. И на основную базу данных он будет маппиться как наш user postgres.
Я все со стандартными настройками показал, у вас могут быть свои пользователи для проектов заведены, для отдельных баз, здесь нужно именно их будет указать, чтобы все работало.
Далее мы заводим табличку на основном сервере:
Это будет табличка с такой же структурой, но единственное, что будет отличаться — это префикс того, что это будет foreign table, т.е. она какая-то иностранная для нас, отдаленная, и мы указываем, с какого сервера она будет взята, и в опциях указываем схему и имя таблицы, которую нам нужно взять.
Схема по дефолту — это public, таблицу, которую мы завели, назвали news. Точно так же мы подключаем 2-ую таблицу к основному серверу, т.е. добавляем сервер, добавляем маппинг, создаем таблицу. Все, что осталось — это завести нашу основную таблицу.
Это делается с помощью VIEW, через представление, мы с помощью UNION ALL склеиваем запросы из удаленных таблиц и получаем одну большую толстую таблицу news из удаленных серверов.
Также мы можем добавить правила на эту таблицу при вставке, удалении, чтобы работать с основной таблицей вместо шардов, чтобы нам было удобнее — никаких переписываний, ничего в приложении не делать.
Мы заводим основное правило, которое будет срабатывать, если ни одна проверка не сработала, чтобы не происходило ничего. Т.е. мы указываем DO INSTEAD NOTHING и заводим такие же проверки, как мы делали ранее, но только с указанием нашего условия, т.е. category_id=1 и таблицу, в которую данные вместо этого будут попадать.
Т.е. единственное отличие — это в category_id мы будем указывать имя таблицы. Также посмотрим на вставку данных.
Я специально выделил несуществующие партиции, т.к. эти данные по нашему условию не попадут никуда, т.е. у нас указано, что мы ничего не будем делать, если не нашлось никакого условия, потому что это VIEW, это не настоящая таблица, туда данные вставить нельзя. В том условии мы можем написать, что данные будут вставляться в какую-то третью таблицу, т.е. мы можем завести что-то типа буфера или корзины и INSERT INTO делать в ту таблицу, чтобы там копились данные, если вдруг каких-то партиций у нас нет, и данные стали приходить, для которых нет шардов.
Выбираем данные
Обратите внимание на сортировку идентификаторов — у нас сначала выводятся все записи из первого шарда, затем из второго. Это происходит из-за того, что postgres ходит по VIEW последовательно. У нас указаны select’ы через UNION ALL, и он именно так исполняет — посылает запросы на удаленные машины, собирает эти данные и склеивает, и они будут отсортированы по тому принципу, по которому мы эту VIEW создали, по которому тот сервер отдал данные.
Делаем запросы, какие мы делали ранее из основной таблицы с указанием категории, тогда postgres отдаст данные только из второго шарда, либо напрямую обращаемся в шард.
Так же, как и в примерах выше, только у нас разные сервера, разные инстансы, и все точно так же работает как работало раньше.
Посмотрим на explain.
У нас foreign scan по news_1 и foreign scan по news_2, так же, как было с партицированием, только вместо Seq Scan-а у нас foreign scan — это удаленный скан, который выполняется на другом сервере.
Партицирование — это действительно просто, стоит всего лишь несколько действий совершить, все настроить, и оно все будет замечательно работать, не будет просить есть. Можно так же работать с основной таблицей, как мы работали ранее, но при этом у нас все красиво лежит по полочкам и готово к масштабированию, готово к большому количеству данных. Все это работает на одном сервере, и при этом мы получаем прирост производительности в 3-4 раза, за счет того, что у нас объем данных в таблице сокращается, т.к. это разные таблицы.
Шардинг — лишь немного сложнее партицирования, тем, что нужно настраивать каждый сервер по отдельности, но это дает некое преимущество в том, что мы можем просто бесконечное количество серверов добавлять, и все будет замечательно работать.
