Типы ядер свертки: упрощенный
Дата публикации Oct 18, 2019
Интуитивное введение в различные вариации гламурного слоя CNN
Просто краткое вступление


Вместо использования ядер, созданных вручную, для извлечения функций через Deep CNN мы можем узнать эти значения ядра, которые могут извлечь скрытые функции. Для дальнейшего изучения работы обычных CNN я бы предложил этот блог.
Интуитивно понятное понимание сверток для глубокого обучения
Изучение сильных визуальных иерархий, которые заставляют их работать
towardsdatascience.com
Ядро против фильтра
Прежде чем мы углубимся в это, я просто хочу провести четкое различие между терминами «ядро» и «фильтр», потому что я видел, что многие люди используют их взаимозаменяемо. Ядро, как описано ранее, представляет собой матрицу весов, которые умножаются на входные данные для извлечения соответствующих признаков. Размеры матрицы ядракак свертка получает свое имя, Например, в двумерных свертках матрица ядра является двумерной матрицей.
Однако фильтр представляет собой объединение нескольких ядер, каждое из которых назначено определенному каналу ввода. Фильтры всегда на одно измерение больше, чем ядра. Например, в двумерных свертках фильтры являются трехмерными матрицами (что по существу является объединением двумерных матриц, то есть ядер). Таким образом, для слоя CNN с размерами ядра h * w и входными каналами k размеры фильтра k * h * w.
Общий слой свертки фактически состоит из нескольких таких фильтров.Для простоты в последующем обсуждении предположим наличие только одного фильтра, если он не указан, поскольку одинаковое поведение реплицируется во всех фильтрах.
1D, 2D и 3D свертки
1D свертки обычно используются для анализа данных временных рядов (поскольку в таких случаях вводится 1D). Как упоминалось ранее, ввод данных 1D может иметь несколько каналов. Фильтр может двигаться только в одном направлении, и, следовательно, выходной сигнал равен 1D. Ниже приведен пример одноканальной свертки 1D.

Мы уже видели пример одноканальной двухмерной свертки в начале публикации, поэтому давайте представим многоканальную двухмерную свертку и попытаемся обернуть ее вокруг. На диаграмме ниже размеры ядра 3 * 3, и в фильтре несколько таких ядер (помечено желтым). Это потому, что на входе есть несколько каналов (отмечены синим), и у нас есть одно ядро, соответствующее каждому каналу на входе. Очевидно, что здесь фильтр может двигаться в 2 направлениях, и, таким образом, конечный результат является 2D. 2D-свертки являются наиболее распространенными и часто используются в Computer Vision.

Трудно визуализировать 3D-фильтр (поскольку это 4-мерная матрица), поэтому мы обсудим здесь одноканальную 3D-свертку. Как видно из изображения ниже, в трехмерных свертках ядро может двигаться в 3 направлениях, и, таким образом, полученный результат также является трехмерным.

Большая часть работы, проделанной в модификации и настройке слоев CNN, была сфокусирована только на двухмерных свертках, и поэтому с этого момента я буду обсуждать только эти вариации в контексте двухмерных сверток.
Транспонированная Свертка (Деконволюция)
GIF ниже хорошо показывает, как двумерная свертка уменьшает размеры входных данных. Но иногда нам нужно выполнять обработку ввода, например, чтобы увеличить ее размеры (также называемые «повышающей дискретизацией»).

Чтобы достичь этого с помощью свертки, мы используем модификацию, известную как транспонированная свертка или деконволюция (хотя это не совсем «обратная» операция свертки, поэтому многие люди не предпочитают использовать этот термин). Пунктирные блоки в GIF ниже представляют отступы.

Я думаю, что эти анимации дают хорошее представление о том, как различные выходные данные с повышенной частотой дискретизации могут быть созданы из одного и того же входа на основе шаблона заполнения. Такие свертки очень часто используются в современных сетях CNN, главным образом из-за их способности увеличивать размеры изображения.

Отделимая свертка
Разделяемая свертка относится к разбиению ядра свертки на ядра более низкой размерности. Отделимые свертки бывают двух основных типов Во-первых, это пространственно отделимые свертки, см., Например, ниже.


Однако пространственно отделимые свертки не так часто встречаются в Deep Learning. С другой стороны, отделимые глубиной извилины широко используются в облегченных моделях CNN и обеспечивают действительно хорошие характеристики. Смотрите ниже, например.


Дилатационная (злокачественная) свертка
Как вы видели во всех вышеупомянутых слоях свертки (без исключения), они обрабатывают все соседние значения вместе. Тем не менее, иногда в интересах конвейера было бы пропустить определенные входные значения, и именно так были введены расширенные свертки (также называемые сверточными свертками). Такая модификация позволяет ядру увеличить егодальность обзора,без увеличения количества параметров.

Из приведенной выше анимации ясно видно, что ядро способно обрабатывать более широкие окрестности с теми же 9 параметрами, что и ранее. Это также означает потерю информации из-за невозможности обработать детализированную информацию (поскольку она пропускает определенные значения). Тем не менее, общий эффект представляется положительным в некоторых приложениях.
Деформируемая свертка


Что дальше?
Было несколько вариантов слоев CNN, которые использовались независимо или в комбинации друг с другом для создания успешных и сложных архитектур. Каждый вариант был основан на интуиции о том, как должно работать извлечение признаков. Таким образом, я считаю, что хотя эти сети Deep CNN изучают веса, которые мы не можем объяснить, интуиция, связанная с их формированием, очень важна для их работы, и дальнейшая работа в этом направлении важна для успеха очень сложных CNN.
Этот блог является частью усилий по созданию упрощенного введения в области машинного обучения. Следуйте за полной серией здесь
Машинное обучение: упрощенное
Знай это, прежде чем погрузиться в
towardsdatascience.com
Или просто прочитайте следующий блог в серии
Фильтрация изображений методом свертки
Автором данного топика является хабраюзер Popik, который сам не может запостить этот топик в силу астральных причин.
Введение.
 Вероятно, большинство хабросообщества не понаслышке знает о фильтрах обработки изображений, таких как размытие, повышение резкости, нахождение краев, тиснение и прочие. Некоторые работали с ними более тесно, некоторые использовали их как данность. Однако все ли знают, как именно происходит фильтрация изображения, и что общего между перечисленными фильтрами? В данном топике я постараюсь в общем виде описать алгоритм, по которому это все выполняется, а так же приведу его реализацию.
Вероятно, большинство хабросообщества не понаслышке знает о фильтрах обработки изображений, таких как размытие, повышение резкости, нахождение краев, тиснение и прочие. Некоторые работали с ними более тесно, некоторые использовали их как данность. Однако все ли знают, как именно происходит фильтрация изображения, и что общего между перечисленными фильтрами? В данном топике я постараюсь в общем виде описать алгоритм, по которому это все выполняется, а так же приведу его реализацию.
Немного теории.
Итак, фильтры, которые были перечислены, а так же множество других основаны на свертке. Что же такое свертка? Свертка (англ. convolution) — это операция, показывающая «схожесть» одной функции с отражённой и сдвинутой копией другой. Понятие свёртки обобщается для функций, определённых на группах, а также мер. Несколько сложноватое определение, не так ли? Те, кому интересна математическая теоретическая часть, могут заглянуть по ссылке на Википедию, и, возможно, почерпнуть для себя что нибудь полезное.
Я же постараюсь дать свое определение-объяснение свертки «на пальцах» только для случая обработки изображений, которое может быть, не настолько умное и точное как в научной литературе, но как мне кажется, позволяющее понять суть данного процесса.
Итак, свертка – это операция вычисления нового значения выбранного пикселя, учитывающая значения окружающих его пикселей. Для вычисления значения используется матрица, называемая ядром свертки. Обычно ядро свертки является квадратной матрицей n*n, где n — нечетное, однако ничто не мешает сделать матрицу прямоугольной. Во время вычисления нового значения выбранного пикселя ядро свертки как бы «прикладывается» своим центром (именно тут важна нечетность размера матрицы) к данному пикселю. Окружающие пиксели так же накрываются ядром. Далее высчитывается сумма, где слагаемыми являются произведения значений пикселей на значения ячейки ядра, накрывшей данный пиксель. Сумма делится на сумму всех элементов ядра свертки. Полученное значение как раз и является новым значением выбранного пикселя. Если применить свертку к каждому пикселю изображения, то в результате получится некий эффект, зависящий от выбранного ядра свертки.
На этом мы закончим с теорией, и перейдем к примерам и реализации данного алгоритма. Мозг еще жив? 🙂
Несколько примеров.




Реализация алгоритма.
Приведу лишь главную часть кода на C#, полный исходный код свертки и небольшую программку для наглядного тестирования можно будет скачать по ссылке в конце статьи. Оговорюсь заранее, что код не писался как нечто очень оптимальное, и поле для оптимизаций еще есть. Например повысить скорость можно использованием предвычисленных значений пикселей, но не в этом суть.
public static class Convolution
<
public static Bitmap Apply( Bitmap input, double [,] kernel)
<
//Получаем байты изображения
byte [] inputBytes = BitmapBytes.GetBytes(input);
byte [] outputBytes = new byte [inputBytes.Length];
int width = input.Width;
int height = input.Height;
int kernelWidth = kernel.GetLength(0);
int kernelHeight = kernel.GetLength(1);
//Производим вычисления
for ( int x = 0; x for ( int y = 0; y double rSum = 0, gSum = 0, bSum = 0, kSum = 0;
byte r = inputBytes[3 * (width * pixelPosY + pixelPosX) + 0];
byte g = inputBytes[3 * (width * pixelPosY + pixelPosX) + 1];
byte b = inputBytes[3 * (width * pixelPosY + pixelPosX) + 2];
double kernelVal = kernel[i, j];
rSum += r * kernelVal;
gSum += g * kernelVal;
bSum += b * kernelVal;
if (kSum //Контролируем переполнения переменных
rSum /= kSum;
if (rSum if (rSum > 255) rSum = 255;
gSum /= kSum;
if (gSum if (gSum > 255) gSum = 255;
bSum /= kSum;
if (bSum if (bSum > 255) bSum = 255;
Вот и все. Надеюсь что данный материал был полезен и преподнес вам что-то новое. Если данная тема вас заинтересовала, то могу написать еще про базовые методы формирования ядер свертки, а так же про оптимизации данного алгоритма. Спасибо за внимание!
Наглядно о том, как работает свёрточная нейронная сеть

К старту курса о машинном и глубоком обучении мы решили поделиться переводом статьи с наглядным объяснением того, как работают CNN — сети, основанные на принципах работы визуальной коры человеческого мозга. Ненавязчиво, как бы между строк, автор наталкивает на размышления о причинах эффективности CNN и на простых примерах разъясняет происходящие внутри этих нейронных сетей преобразования.
Начинаем сначала
Свёрточная нейронная сеть (ConvNet/CNN) — это алгоритм глубокого обучения, который может принимать входное изображение, присваивать важность (изучаемые веса и смещения) аспектам или объектам изображении и отличать одно от другого. При этом изображения в сравнении с другими алгоритмами требуют гораздо меньше предварительной обработки. В примитивных методах фильтры разрабатываются вручную, но достаточно обученные сети CNN учатся применять эти фильтры/характеристики.
Архитектура CNN аналогична структуре связей нейронов в мозгу человека, учёные черпали вдохновение в организации зрительной коры головного мозга. Отдельные нейроны реагируют на стимулы только в некоторой области поля зрения, также известного как перцептивное поле. Множество перцептивных полей перекрывается, полностью покрывая поле зрения CNN.
Почему слои свёртки расположены над сетью с прямой связью
Изображение — не что иное, как матрица значений пикселей, верно? Так почему бы не сделать его плоским (например, матрицу 3×3 сделать вектором 9×1) и скормить этот вектор многослойному перцептрону, чтобы тот выполнил классификацию? Хм… всё не так просто.
В случаях простейших двоичных изображений при выполнении прогнозирования классов метод может показать среднюю точность, но на практике, когда речь пойдёт о сложных изображениях, в которых повсюду пиксельные зависимости, он окажется неточным.
Сеть CNN способна с успехом схватывать пространственные и временные зависимости в изображении через применение соответствующих фильтров. Такая архитектура за счёт сокращения числа задействованных параметров и возможности повторного использования весов даёт лучшее соответствие набору данных изображений. Иными словами, сеть можно научить лучше понимать сложность изображения.
Входное изображение
На рисунке мы видим разделённое на три цветовых плоскости (красную, зелёную и синюю) RGB-изображение, которое можно описать в разных цветовых пространствах — в оттенках серого (Grayscale), RGB, HSV, CMYK и т. д.
Можно представить, насколько интенсивными будут вычисления, когда изображения достигнут размеров, например, 8 K (76804320). Роль CNN заключается в том, чтобы привести изображения в форму, которую легче обрабатывать, без потери признаков, имеющих решающее значение в получении хорошего прогноза. Это важно при разработке архитектуры, которая не только хорошо изучает функции, но и масштабируется для массивных наборов данных.
Слой свёртки — ядро
1 — количество каналов, например, RGB.
В демонстрации выше зелёная секция напоминает наше входное изображение 5×5×1. Элемент, участвующий в выполнении операции свёртки в первой части слоя свёртки, называется ядром/фильтром K, он представлен жёлтым цветом. Пусть K будет матрицей 3×3×1:
Ядро смещается 9 раз из-за длины шага в единицу (то есть шага нет), каждый раз выполняя операцию умножения матрицы K на матрицу P, над которой находится ядро.
 Перемещение ядра
Перемещение ядра
Фильтр перемещается вправо с определённым значением шага, пока не проанализирует всю ширину. Двигаясь дальше, он переходит к началу изображения (слева) с тем же значением шага и повторяет процесс до тех пор, пока не проходит всё изображение.
Операция свёртки на матрице изображения M×N×3 с ядром 3×3×3
В случае изображений с несколькими каналами (например, RGB) ядро имеет ту же глубину, что и у входного изображения. Матричное умножение выполняется между стеками Kn и In ([K1, I1]; [K2, I2]; [K3, I3]), все результаты суммируются со смещением, чтобы получить уплощённый канал вывода свёрнутых признаков с глубиной в 1.
Операция свёртки с длиной шага, равной 2
Свёртка делается, чтобы извлечь высокоуровневые признаки, например края входного изображения. Сеть не нужно ограничивать единственным слоем. Первый слой условно несёт ответственность за схватывание признаков низкого уровня, таких как кромки, цвет, ориентация градиента и т. д. Через дополнительные слои архитектура адаптируется к признакам высокого уровня, мы получаем сеть со здравым пониманием изображений в наборе данных, похожем на наше.
У результатов свёртки два типа: первый — свёрнутый признак уменьшается в размере по сравнению с размером на входе, второй тип касается размерности — она либо остаётся прежней, либо увеличивается. Это делается путём применения допустимого заполнения в первом случае или нулевого заполнения — во втором.
Нулевое заполнение: для создания изображения 6×6×1 изображение 5×5×1 дополняется нулями
Увеличивая изображение 5×5×1 до 6×6×1, а затем проходя над ним ядром 3×3×1, мы обнаружим, что свёрнутая матрица будет обладать разрешением 5×5×1. Отсюда и название — нулевое заполнение. С другой стороны, проделав то же самое без заполнения, мы обнаружим матрицу с размерами самого ядра (3×3×1); эта операция называется допустимым заполнением.
В этом репозитории содержится множество таких GIF-файлов, они помогут лучше понять, как заполнение и длина шага работают вместе для достижения необходимых результатов.
Слой объединения
Подобно свёрточному слою, слой объединения отвечает за уменьшение размера свёрнутого объекта в пространстве. Это делается для уменьшения необходимой при обработке данных вычислительной мощности за счёт сокращения размерности. Кроме того, это полезно для извлечения доминирующих признаков, которые являются вращательными и позиционными инвариантами, тем самым позволяя поддерживать процесс эффективного обучения модели.
Есть два типа объединения: максимальное и среднее. Первое возвращает максимальное значение из покрытой ядром части изображения. А среднее объединение возвращает среднее значение из всех значений покрытой ядром части.
Максимальное объединение также выполняет функцию шумоподавления. Оно полностью отбрасывает зашумленные активации, а также устраняет шум вместе с уменьшением размерности. С другой стороны, среднее объединение для подавления шума просто снижает размерность. Значит, можно сказать, что максимальное объединение работает намного лучше среднего объединения.
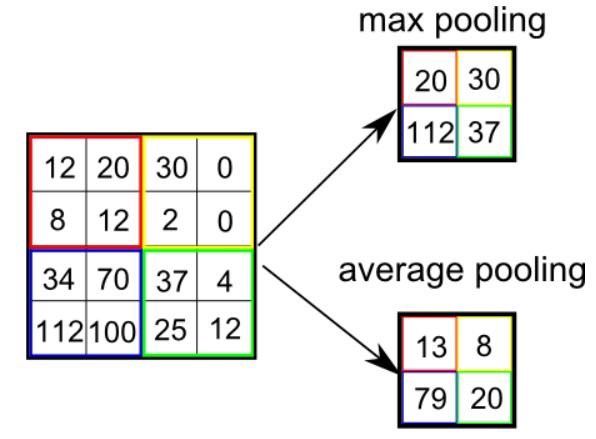 Типы объединения
Типы объединения
Слои объединения и свёртки вместе образуют i-тый слой свёрточной нейронной сети. Количество таких слоёв может быть увеличено в зависимости от сложности изображений, чтобы лучше схватывать детали, но это делается за счёт увеличения вычислительной мощности.
Выполнение процесса выше позволяет модели понимать особенности изображения. Преобразуем результат в столбцовый вектор и скормим его обычной классифицирующей нейронной сети.
Классификация — полносвязный слой

Добавление полносвязного слоя — это (обычно) вычислительно недорогой способ обучения нелинейным комбинациям высокоуровневых признаков, которые представлены на выходе слоя свёртки. Полносвязный слой изучает функцию в этом пространстве, которая может быть нелинейной.
После преобразования входного изображения в подходящую для многоуровневого перцептрона форму мы должны сгладить изображение в вектор столбец. Сглаженный выходной сигнал подаётся на нейронную сеть с прямой связью, при этом на каждой итерации обучения применяется обратное распространение. За серию эпох модель обретает способность различать доминирующие и некоторые низкоуровневые признаки в изображениях и классифицировать их методом классификации Softmax.
У CNN есть различные архитектуры, сыгравшие ключевую роль в построении алгоритмов, на которых стоит и в обозримом будущем будет стоять искусственный интеллект в целом. Некоторые из этих архитектур перечислены ниже:
Репозиторий с проектом по распознаванию цифр.
CNN имеет огромное количество практических приложений; и если вам интересны эксперименты и поиски в области ИИ, обратите внимание на наш курс о машинном и глубоком обучении или прокачайтесь в работе с данными или освойте перспективную специальность с помощью нашего флагманского курса о Data Science.
Узнайте, как прокачаться и в других специальностях или освоить их с нуля:
Наглядно объясняем операцию свертки в моделях глубокого обучения
При помощи анимированных изображений и визуализаций слоев CNN-сетей раскрываем широко применяемое в моделях глубокого обучения понятие свертки.
В современных фреймворках глубокого обучения сверточные слои в моделях нередко представляются в виде однострочного кода. Само же понятие свертки обычно остается для начинающих аналитиков труднодоступным, как и лежащие в его основе понятия ядра, фильтра, канала и т. д. Тем не менее, свертка представляет собой мощный и расширяемый инструмент, позволяющий разреживать взаимодействия нейронов, находить общие параметры, работая одинаковым образом со входными данными различного размера. Сравним механики операции свертки и полносвязной нейросети.
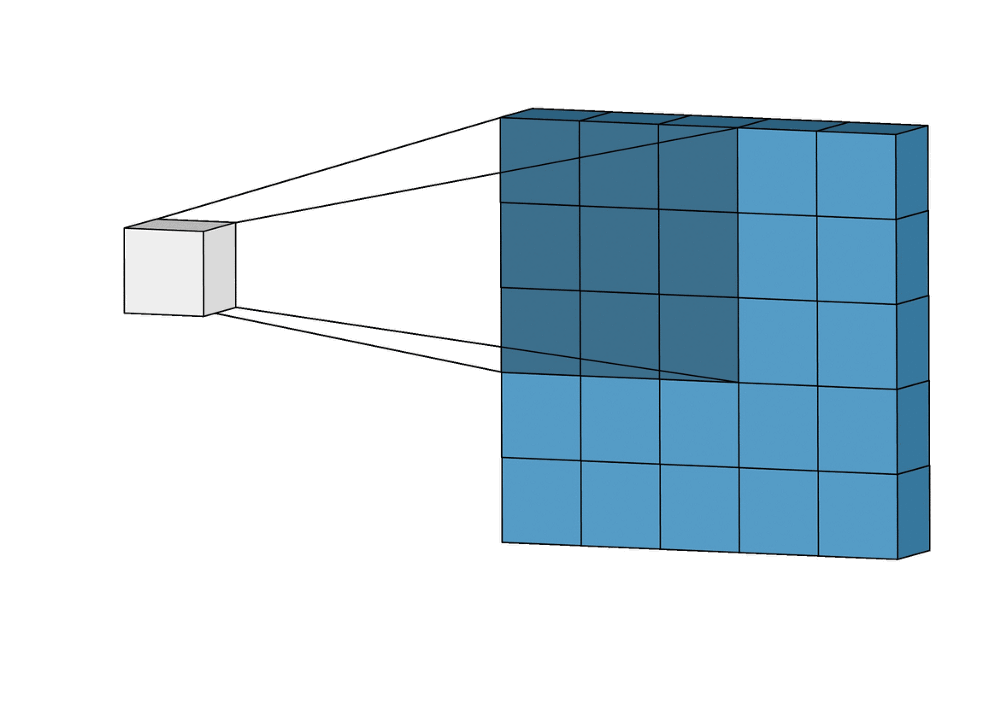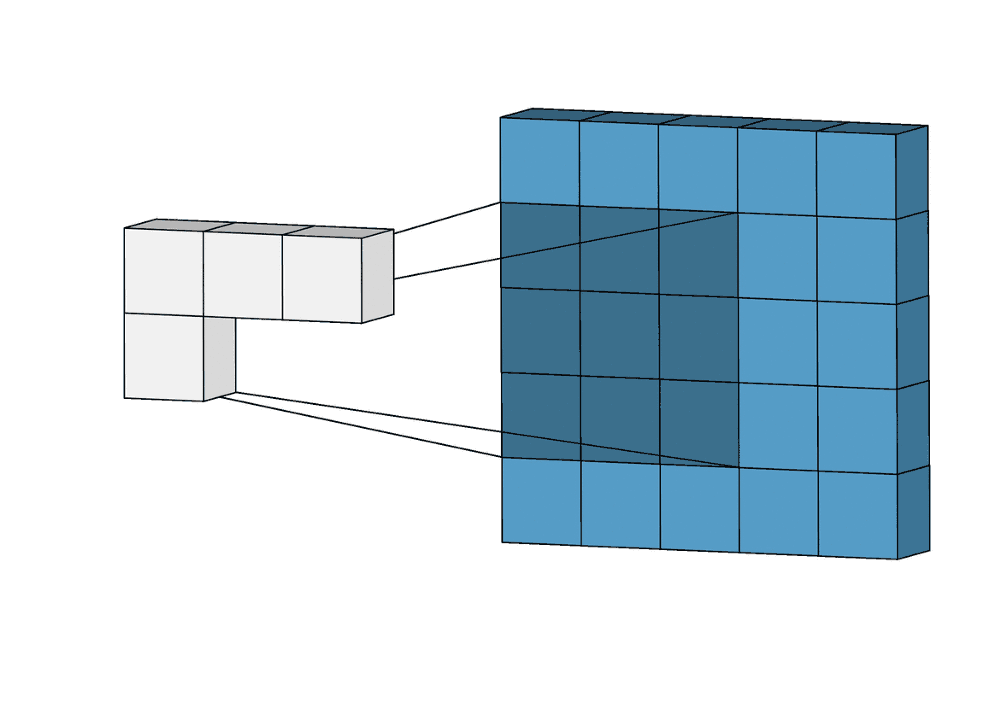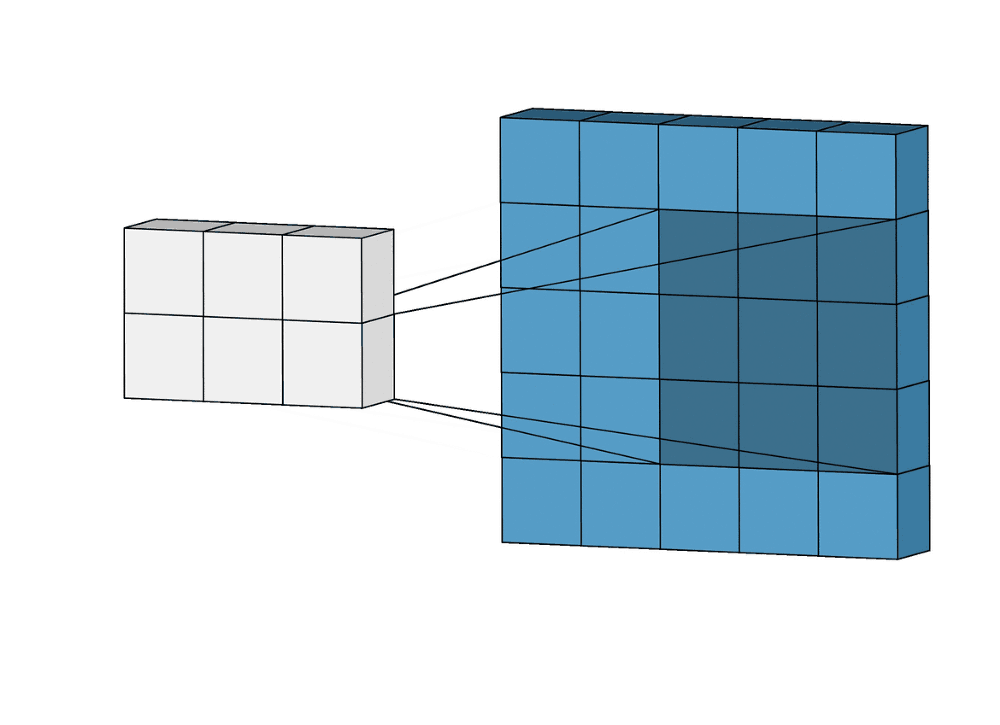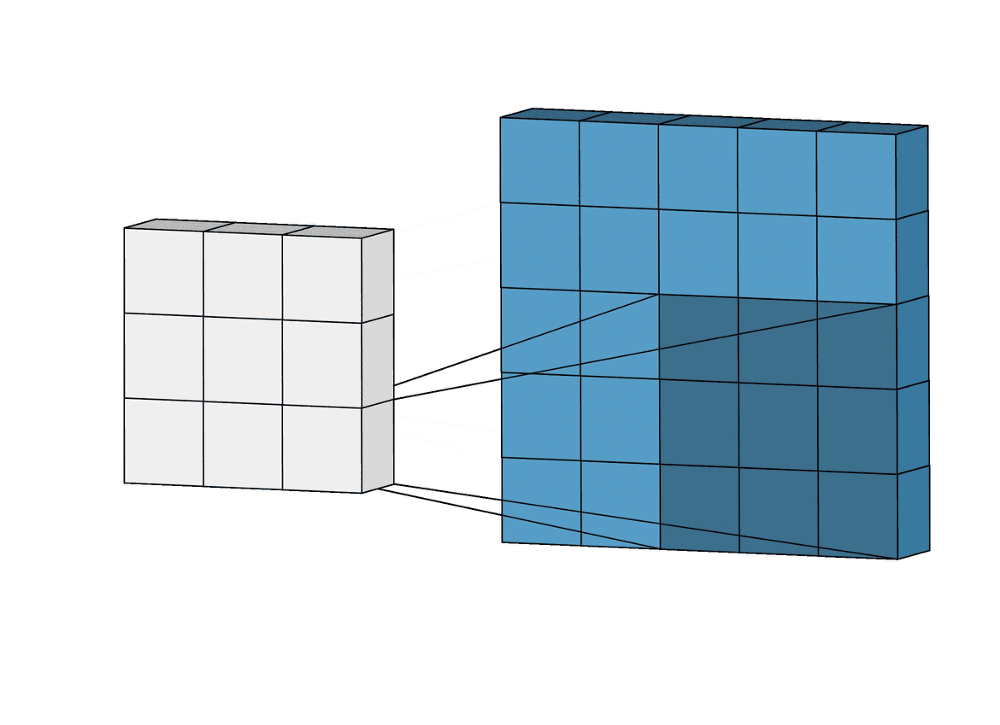
Суть операции свертки на примере черно-белых изображений
В математическом отношении в двумерной свертке нет ничего сложного. Имеется ядро – небольшая матрица весов. Это ядро «скользит» по двумерным входным данным, выполняя поэлементное умножение для той части данных, которую сейчас покрывает. Результаты перемножений ячеек суммируются в одном выходном пикселе. В случае сверточных нейросетей ядро определяется в ходе обучения сети. Начальные веса, аналогично случаю перцептрона, могут иметь рандомные значения, и корректируются в процессе обучения.

Перемножение и суммирование повторяются для каждой локации, по которой проходит ядро. Двумерная матрица входных признаков преобразуется в двумерную матрицу выходных. Выходные признаки, таким образом, являются взвешенными суммами входных признаков. Число входных признаков в комбинации для одного выходного признака определяет размер ядра.
Такой подход контрастирует с полносвязными сетями. Так, в приведенном выше примере имеется 5×5=25 входных признаков и 3×3=9 выходных. Если бы это были два полносвязных слоя, весовая матрица состояла бы из 25×9=225 весовых параметров. При этом каждая функция вывода была бы взвешенной суммой всех входов. В случае свертки, взвешенная сумма берется только по числу весов ядра. И в рассмотрении одновременно участвуют только близлежащие элементы.
Свертка соответствует модели иерархий абстрактных представлений: совокупность пикселей обобщается до ребер, те – до паттернов, и, наконец, до самого объекта. Малозначимые детали отфильтровываются в процессе перехода к более абстрактным образам.
Некоторые распространенные методы
Обратим внимание на два характерных метода, связанных с операцией свертки: дополнение отступа (padding) и выбор шага (strides).
Нулевой отступ
В вышеприведенном примере скольжение ядра «обрезает» исходный двумерный массив по краю, преобразуя матрицу 5×5 в 3×3. Краевые пиксели теряются из-за того, что ядро не может распространяться за пределы края. Однако иногда необходимо, чтобы размер выходного массива был тем же, что и у входных данных.
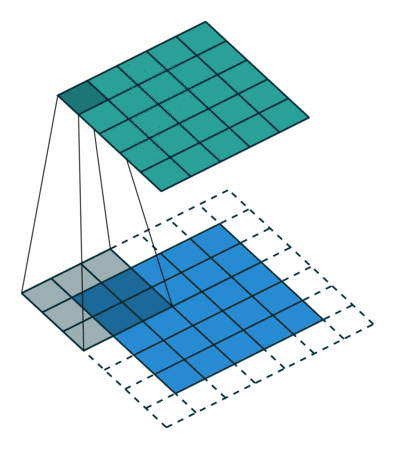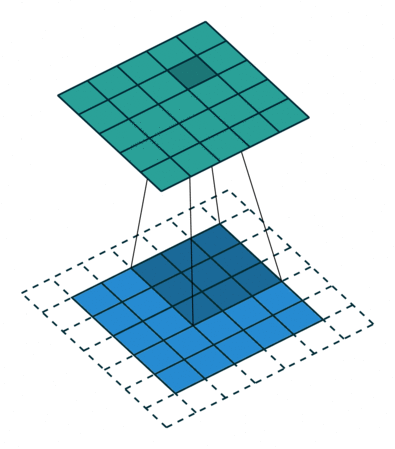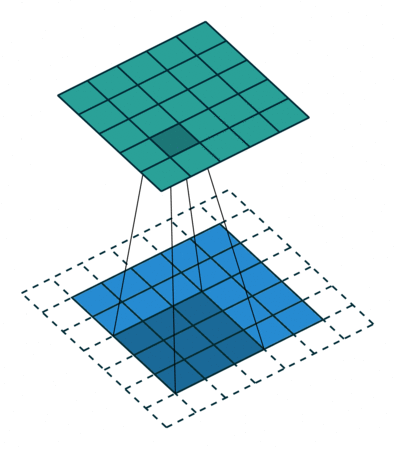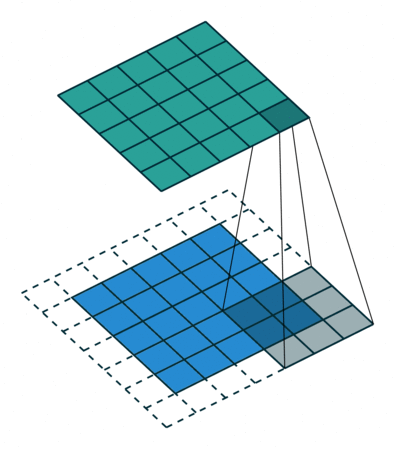
Чтобы решить эту задачу, исходный массив можно дополнить «поддельными» пикселями. Например, в виде краевого поля, окружающего массив. Если в качестве значений берутся нули, говорят о «нулевом отступе» (zero padding).
Еще чаще стоит задача субдискретизации – уменьшения размерности выходного сигнала в сравнении с исходным. Это обычное явление в сверточных нейросетях, где размер пространственных измерений уменьшается при увеличении количества каналов. Одним из способов является применение объединяющего (pooling) слоя. За счет отбора средних/максимальных значений из каждых соседствующих счетверенных ячеек 2×2 можно уменьшить размерность исходной сетки вдвое. Другой подход – использовать шаг свертки.
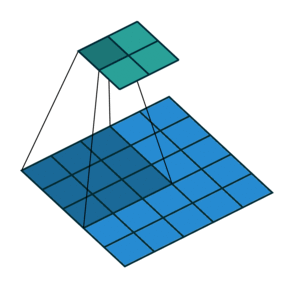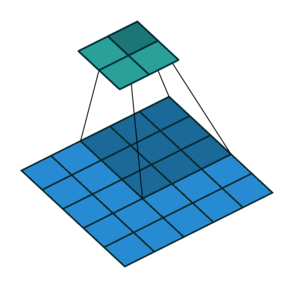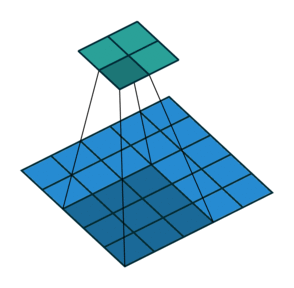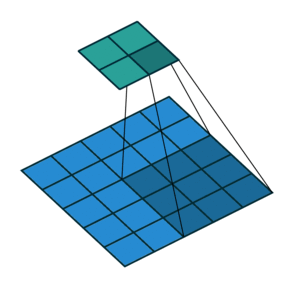
Идея шага состоит в том, чтобы при скольжении ядра пропускать часть позиций массива. Значения шага 1 означает выбор каждого пикселя сетки. Шаг 2 означает отбор пикселей на расстоянии в два пикселя с пропуском одного промежуточного, и так далее.
Многоканальная версия – цветные изображения
Вышеприведенные диаграммы соответствуют лишь изображениям с одним входным каналом. На практике большинство изображений имеют три канала: красный, зеленый и синий.

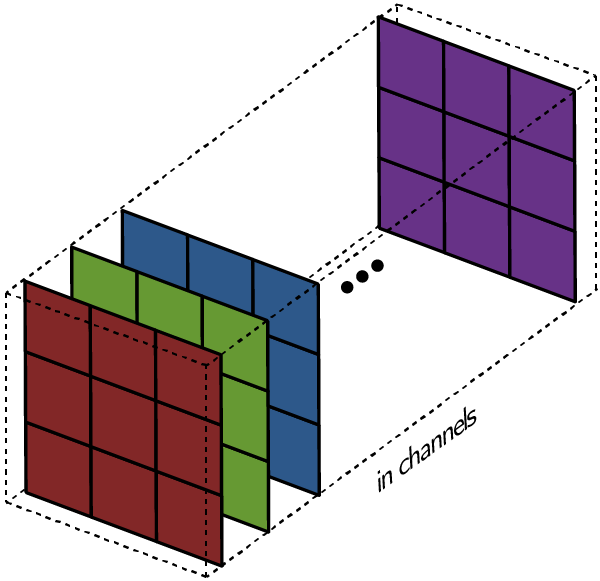
В случае с одним каналом термины фильтр и ядро взаимозаменяемы. Для цветного изображения они различны. Фильтр – это коллекция ядер, каждое из которых соответствует одному каналу. Ядро фильтра скользит по данным канала, создавая их обработанную версию. Значимость ядер определяется взаимным отношением их весов. Например, ядро для красного канала может быть более значимым в модели, чем другие ядра фильтра, тогда будут больше и соответствующие веса.
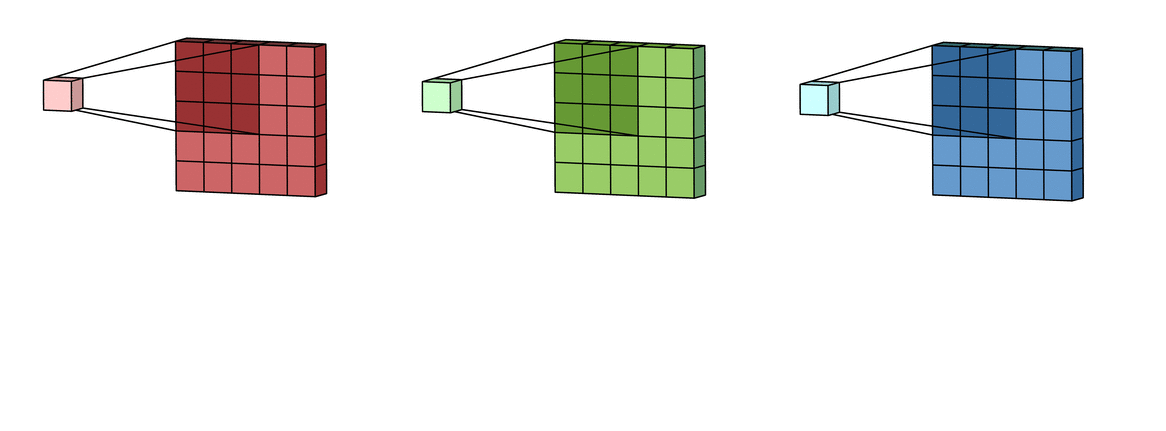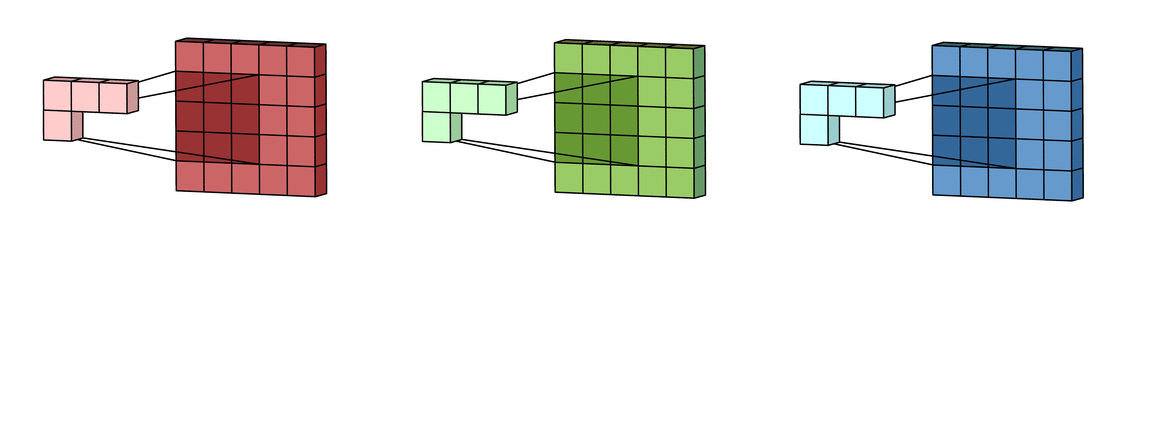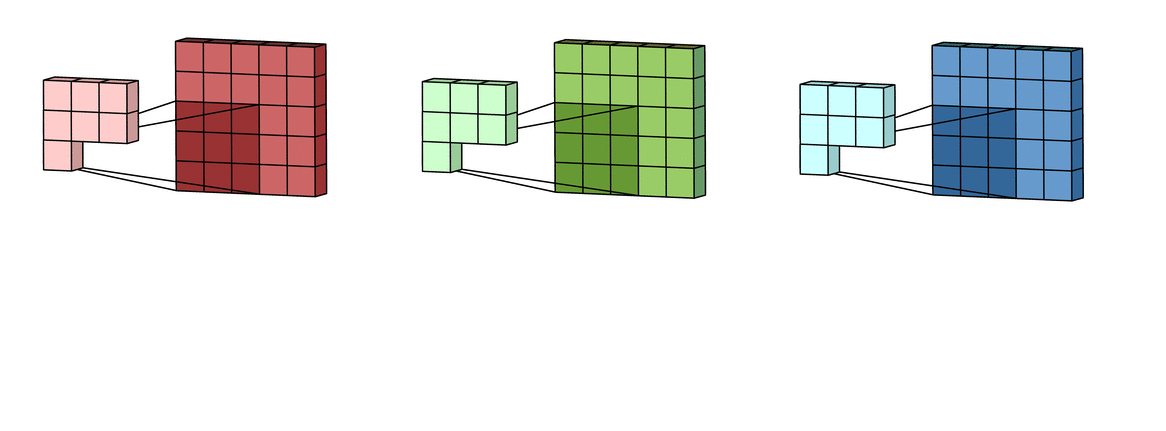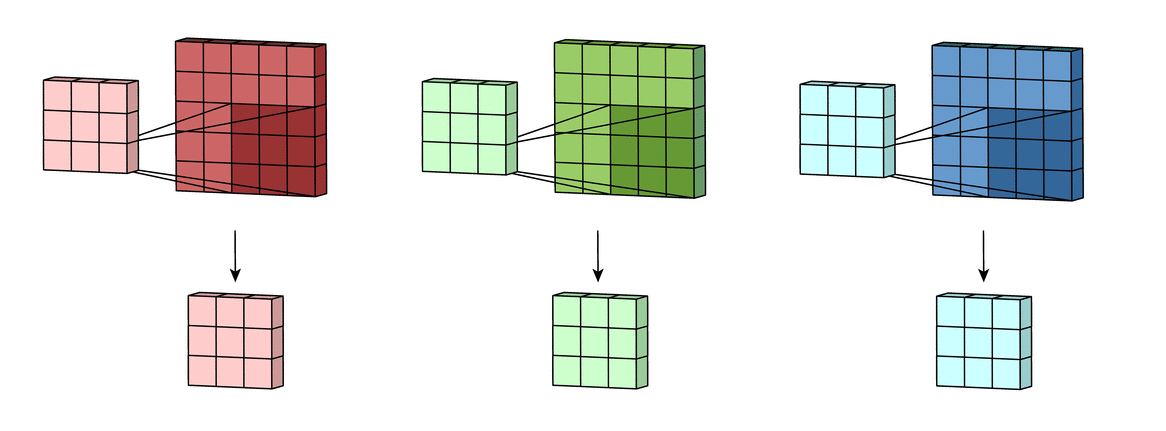
Каждая из обработанных в своих каналах версий суммируется для формирования общего канала.
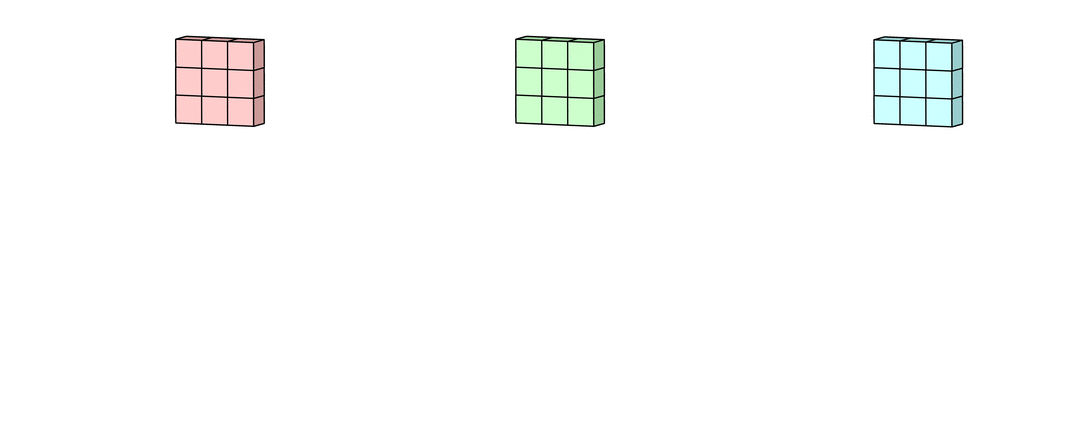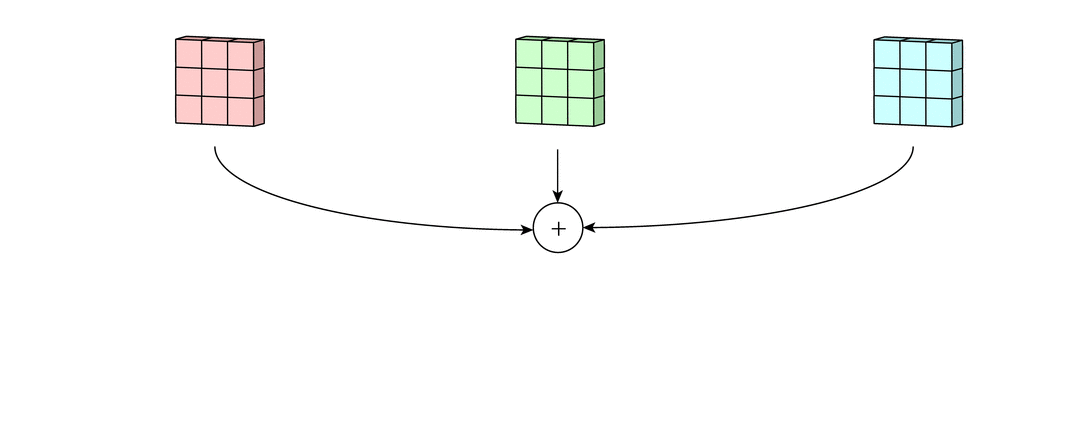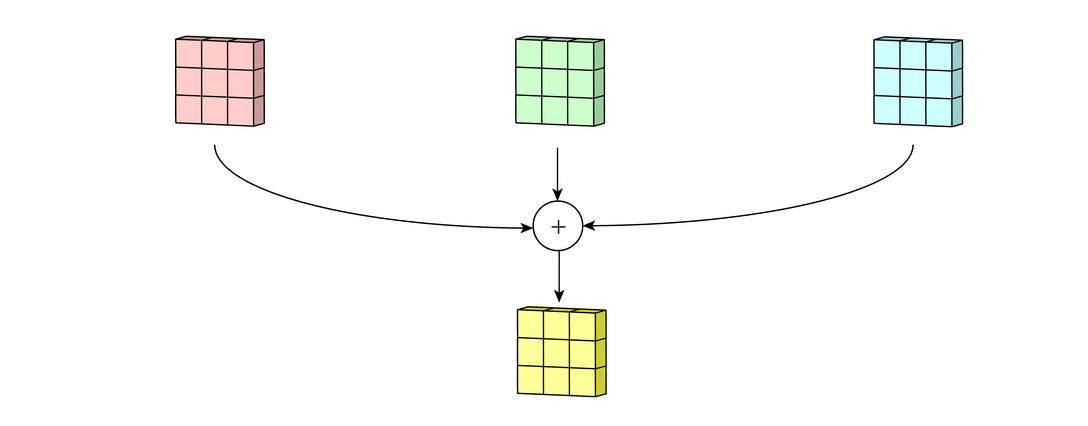
В выходном терминале может присутствовать линейное смещение, независимое от функций каждого из ядер и свойственное лишь выходному каналу.
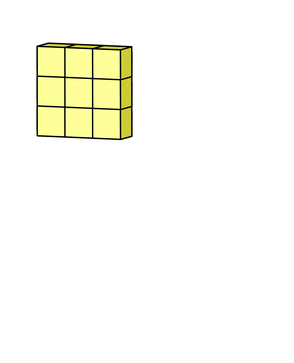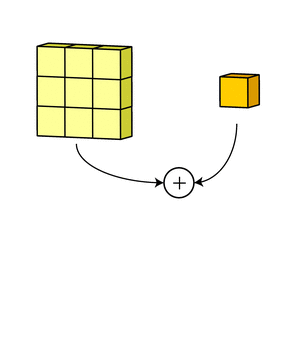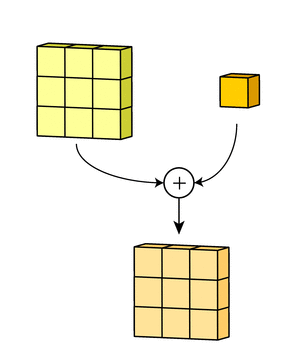
Математическая подоплека свертки – особенности линейного преобразования
Предположим, что у нас есть вход 4×4. Мы хотим преобразовать его в сетку 2×2. Если мы используем сеть прямого распространения, потребуется входной вектор из 16 нейронов, полностью связанных с 4 выходными нейронами. Такую ситуацию можно визуализировать весовой матрицей w.

Хотя операция ядерной свертки может показаться вначале немного странной, она является линейным преобразованием. Если бы мы использовали ядро K размера 3 для тех же размеров входа и выхода, эквивалентная матрица линейного преобразования выглядела бы следующим образом:
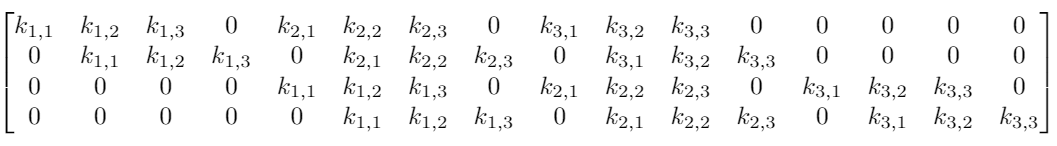
Для матрицы с 16×4=64 элементами имеется всего 9 нетривиальных параметров, подлежащих оптимизации вместо 64 весовых параметров для полносвязной двухслойной нейронной сети. Обнуление значительной части параметров обусловлено локальностью применяемой операции. Помимо ускорения расчетов, свертка приводит и к лучшей инвариантности относительно размеров входных данных.
Впрочем это не объясняет, почему такой подход может быть не менее эффективным, чем полносвязная сеть. Ядро, формирующее выходной сигнал, представляет взвешенную комбинацию небольшой области близкорасположенных пикселей. Но в то же время операция взаимодействия с ядром применяется одинаково ко всему изображению.
Локальность свертки
Если бы это был какой-то другой тип данных, а не изображения (например, набор категориальных данных), обобщение, осуществляемое сверткой, могло бы привести к катастрофе. В выходных признаках появлялась бы отсутствовавшая исходно корреляция.
В то же время любое изображение с точки зрения математики представляет собой совокупность правил взаимного расположения элементов. Использование фильтров для поиска элементов изображений – это одна из старых идей компьютерного зрения. Например, для обнаружения контуров можно использовать фильтр Собеля. В отличие от обучаемых ядер сверточных нейронных сетей, ядро этого фильтра имеет фиксированные веса:

Для фонового неба, не содержащего краевых элементов большинство пикселей на изображении имеют одинаковые значения. Суммарные значения выхода ядра в этих местах равны нулю. Для части изображения с вертикальными границами в местах границ существует разница между пикселями слева и справа от края. Ядро, вычисляя эту ненулевую разницу, определяет положение контуров. Повторимся, ядро работает каждый раз только с локальными областями 3×3, обнаруживая аномалии в локальном масштабе.
Применяя один и тот же подход ко всему изображению, можно получить результат для всего массива. Аналогично свертка с транспонированным ядром позволяет выделить горизонтальные края.
Визуализация признаков при помощи оптимизации
Целая отрасль исследований в сфере глубокого обучения посвящена тому, чтобы сделать модели нейронных сетей интерпретируемыми. Одним из мощных инструментов для подобного рода задач является предложенная в работе 2017 года визуализация признаков при помощи оптимизации. Идея в корне простая: оптимизировать изображение, инициализированное шумом, так, чтобы активировать фильтр как можно сильнее.
На трех изображениях ниже представлены визуализации трех различных каналов для первого сверточного слоя GoogleNet. Хотя слои детектируют различные типы контуров, все они являются низкоуровневыми детекторами.

На двух следующих изображениях представлены примеры визуализации фильтров сверточных слоев второго и третьего уровней.

Одна из важных вещей: изображения после операции свертки – это все еще изображения. Операция действует эквивариантно: если изменяется вход, то выход изменяется так же.
Элементы, находившиеся в левом верхнем углу, после свертки имеют соответствующие отображения также в левом верхнем углу. Как бы глубоко ни заходили детекторы признаков, они все равно будут работать на очень маленьких ядерных участках. Неважно, насколько глубоко происходит свертка, но вы не можете обнаружить лица из сеток размером 3х3. Здесь возникает идея локальной зоны восприимчивости (receptive field).
Зона восприимчивости свертки
Существенной составляющей архитектуры сверточной нейронной сети является уменьшение объема данных от входа к выходу модели с одновременным увеличением глубины канала. Как упоминалось ранее, обычно это делается при помощи выбора шага свертки или pooling-слоев. Зона восприимчивости определяет, какая площадь оригинальных входных данных из исходной сетки обрабатывается на выходе. На изображениях ниже представлен пример шагающей свертки с выкидыванием промежуточных пикселей.
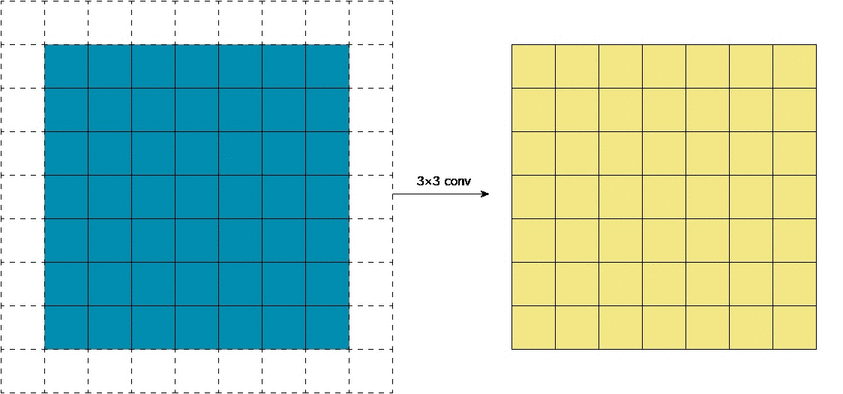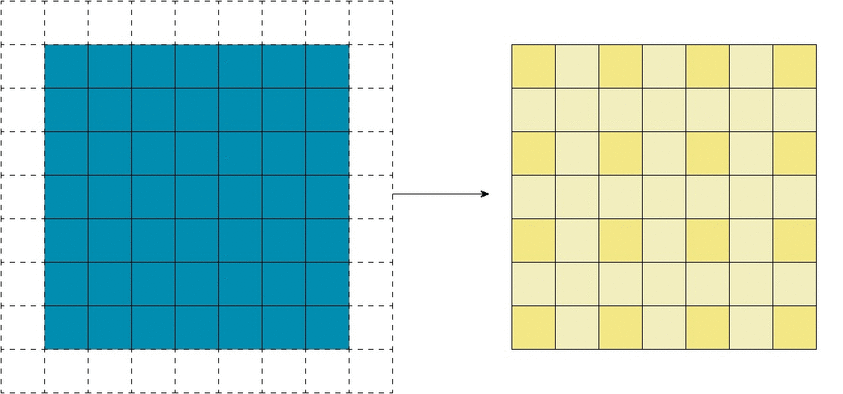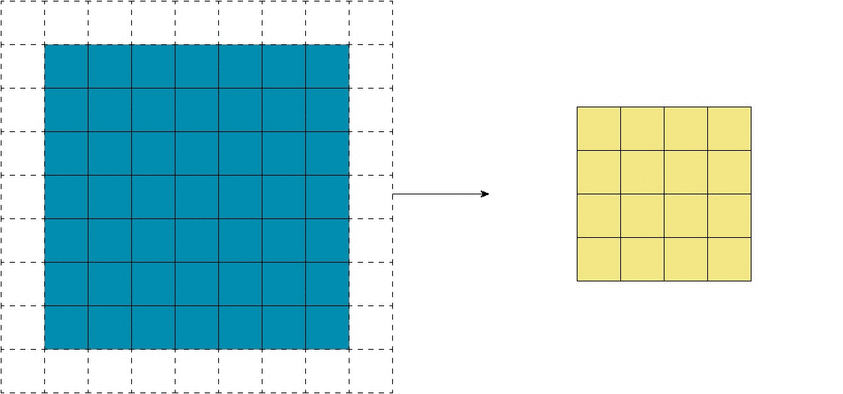
Ниже представлены примеры визуализации признаков набора блоков свертки, показывающие постепенное увеличение сложности. Расширение поля восприимчивости позволяет сверточным слоям комбинировать низкоуровневые признаки (линии, края) в более высокоуровневые (кривые, текстуры).

Сеть развивается от небольшого количества низкоуровневых фильтров на начальных этапах (64 в случае GoogleNet) до очень большого количества фильтров (1024 в финальной свертке), каждый из которых находит специфичный высокоуровневый признак. Переход от уровня к уровню обеспечивает иерархию распознавания образов.
Обобщающие процессы свертки имеет свою оборотную сторону – возможность подделки изображений под удовлетворение особенностей распознающих фильтров. На изображениях ниже человек в обоих случаях узнает фотографии панды. А сверточные нейросети можно запутать, добавив шум, подстроенный под фильтры распознавания других образов.
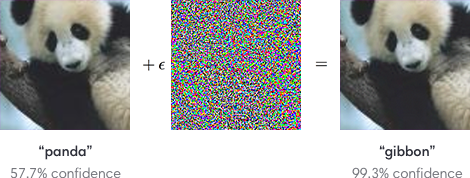
Однако именно сверточные нейронные сети позволили компьютерному зрению пройти путь от простых приложений до сложных продуктов и услуг, таких как распознавание лиц и улучшение качества медицинских диагнозов.
