Какие правильно почистить таблицы в базе Zabbix?
Есть база zabbix c секционными таблицами. Структуру базы со связями в документации не нашел. Проблема такая. Быстро растет таблица history и все ее секции.
В manage_partitions смотрю сколько хранятся данные.
Самый большие секции в history_uint, там за день выходит 5-6 Gb. History_text в день занимает по 500 Mb и если хранить его 120 дней, то места у меня не хватит точно.
Вопросы. Можно ли через UPDATE в базе поменять количество дней и не сломается ли тогда заббикс полностью? Если я правильно понял, то в эти секциях history_* хранятся только данные для графиков?

А вообще, по партицированию есть хорошая тема на zabbix forums.

Однозначно утверждать, что всё пройдет хорошо, Вам никто не будет. Я бы перед такой операцией сначала забэкапился.
И еще, у Вас действительно так много критичных данных для которых требуется хранить историю 120 дней? Вы их действительно анализируете? Может быть для этих целей логичнее использовать тренды (хранят усредненную информацию за каждый час), а период хранения истории ограничить, допустим, месяцем?
Заметки цифрового кочевника
Иногда в результате ошибки конфигурирования шаблона или ошибки конфигурирования оборудования, в данные системы мониторинга попадает масса ложной информации. Возможна ситуация, когда в период времени от А до Б информация верная, от Б до В – ложная, от В до Г верная. Эта статья ответит на вопрос, как удалить информацию на участке от Б до В, не затронув прочие данные.
Подготовка запросов MySQL.
Если ваш мониторинг осуществляется через zabbix proxy, а сервер выступает в роли коллектора данных, то вам несказанно повезло. Вы безболезненно можете остановить zabbix server, сделать резервную копию базы данных, провести удаление данных и после его запуска сервера получить всю информацию за время проведения работ. Таким образом, вы сможете работать в большей безопасности. Однако пока вы проводите свои работы, вам не будут приходить уведомления о событиях в наблюдаемых объектах, что может быть критично для некоторых компаний. В любом случае, вам стоит подумать над шагами к возворату системы в состояния до вносимых изменений. Я делаю резервное копирование базы данных Zabbix перед любыми подобными работами, работы провожу при выключенном сервере. Для резервного копирования используя следующий скрипт:
Подсвечены строки, требующие внесения ваших параметров!
Пока идёт резервное копирование — займёмся определением исходных данных. Нужно выяснить какие данные нужно удалить и где они находятся. Поможет нам в этом веб интерфейс системы. Веб интерфейс работает независимо от сервера заббикс, поэтому с доступом проблем быть не должно, однако возможно долгое выполнение запросов к интерфейсу в связи с загруженностью базы данных.
Чаще всего ошибки в данных обнаруживаются в двух случаях: неправильно срабатывают триггеры или графики показывают неактуальную информацию. В моём случае имела место вторая ситуация. Мои графики загрузки сетевых интерфейсов выглядели совсем неправдоподобно, и я знал, что 13 сентября были проведены изменения в шаблон:
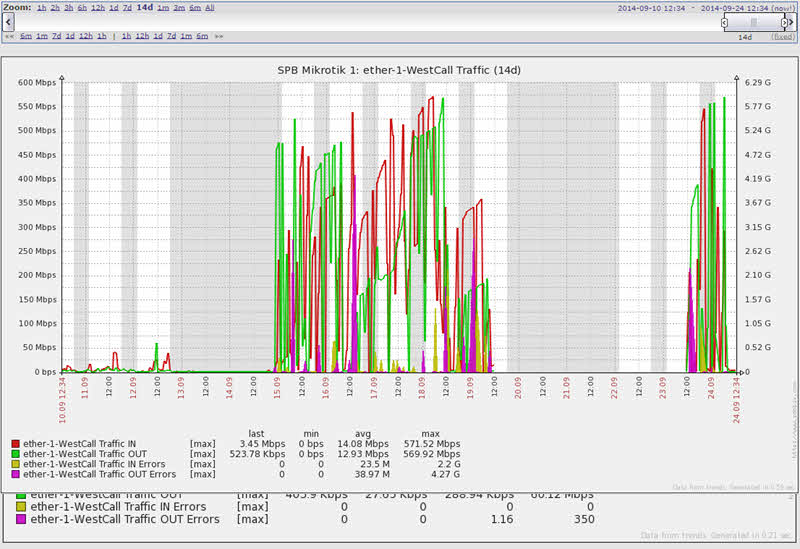
Кроме информации по сетевым интерфейсам ошибочной была признана информация и по большинству других параметров данных устройств. Решено было удалить всю информацию по конкретным устройствам за последние две недели. Для этого нам нужно узнать id хостов, чтобы на их базе получить id параметров для удаления. Сделать это можно просто посмотрев на ссылку в веб интерфейсе zabbix. Например, при просмотре графиков:

В моём случае хосты имеют номера 10276, 10245, 10089. На базе данной информации я получаю список всех наблюдаемых параметров прямо из базы данных. Для этого используется следующий sql запрос:
Следующий необходимый кусок мозаики — временной промежуток, который нужно удалить. Даты и время в базе данных zabbix хранятся в unixtime формате. Поэтому нам нужно конвертировать начальное и конечное время в этот формат. Моя начальная дата — 14 сентября 2014 года 6 часов вечера, в unixtime формате это 1410703200. Конечная дата — 24 сентября 2014 года 12 часов дня вечера, в unixtime формате это 1411545600. При переводе времени между форматами не забывайте про часовые пояса, это самая частая ошибка. Перевод между часовыми часами вы должны делать до написания запроса, т.е. в уме. Unixtime – часовой пояс GMT. Перевод между форматами можно делать прямо в SQL запросе.
Определив промежуток времени, нам нужно выяснить тип удаляемых данных. От этого зависит внутренняя таблица базы данных zabbix, в которой нужно производить манипуляции. Либо можно пройтись запросами по всем таблицам без разбора. Я предпочитаю второй метод. Он не оставляет никаких следов за указанный период.
В заббикс за хранения исторических данных отвечают следующие таблицы:
В исторические таблицы записываются непосредственно снимаемые данные. Срок их хранения устанавливается в шаблонах отдельным параметром. Долгое хранение данных в этих таблицах не имеет смысла, так как графики с детализацией более 1 недели строятся по трендам и этот параметр жёстко записан в коде zabbix. По объёму данных исторические таблицы обычно одни из самых объёмных во всех установках систем мониторинга zabbix.
За хранения трендов отвечает всего две таблицы:
Тренды являются встроенным механизмом обработки данных истории, где для каждого часа хранятся значения минимума, максимума и усредненное значение, а также общее количество значений за этот час. Поэтому таблицы трендов занимают значительно меньше места в системе хранения. Тренды на русском – динамика изменений, да простит меня русский язык за кальку.
Проверка запросов MySQL и выполнение удаления.
Итак, осталось запустить запрос и проверить правильность его написания в вашем случае. Запрос на просмотр удаляемых данных будет выглядеть так:
Запрос должен вернуть список объектов, соответствующих заданным условиям. В конце строки запроса стоит фраза «LIMIT 0, 1000», которая лимитирует количество строк в ответе. Для понимания правильности достаточно 1000 строк. Если же сделать запрос безграничным, то это может вызвать значительную нагрузку на сервер баз данных. Здесь важно учитывать, остаётся он или нет рабочим в момент проведения манипуляций.
Если ответ на запрос получен, значит всё сделано верно. Осталось изменить тип запроса на запрос удаления. Удалять мы будем через команду DELETE.
Приведённые запросы тоже имеют лимит количества строк на выполнение. Это сделано, чтобы вы могли оценить загрузку вашего сервера баз данных и системы хранения в момент выполнения команды. Команда DELETE работает очень медленно и ресурсоёмко. В зависимости от участка удаляемых данных выполнение данной команды может занять несколько часов, в экстремальных, не лимитированных случаях – несколько дней.
Заключение.
Я думаю, что данную задачу можно оптимизировать на участке синтаксиса SQL запроса, однако алгоритм выполнения задачи будет соответствовать указанному в статье. Я с радостью отвечу на ваши вопросы или критику в комментариях к статье. Результат наших монипуляций виден в правильном графике:
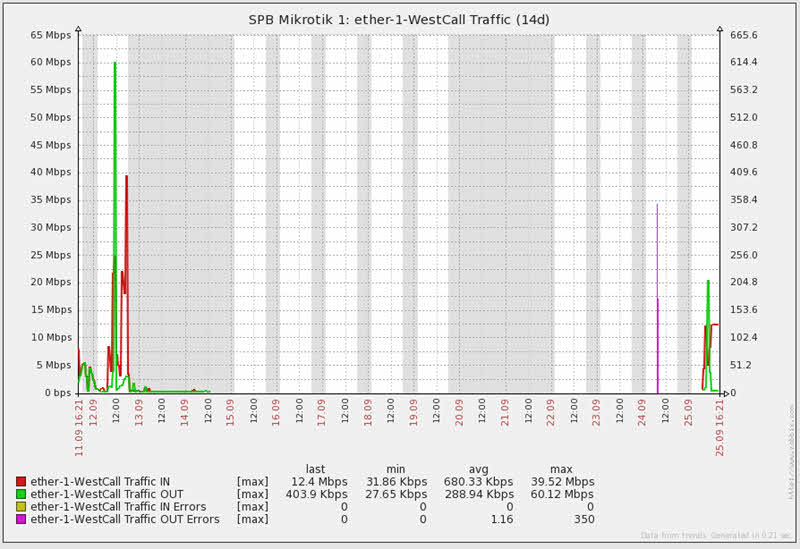
На большом графике провал есть, но в целом график более информативен:
Zabbix: Оптимизация и чистка базы данных

Основная задача, которую пытаемся решить — малой кровью обеспечить хорошую производительность сервера и предотвратить неконтролируемый рост базы.
Характеристики текущего сервера:
Ubuntu 14.04.4
psql (PostgreSQL) 9.3.13
Zabbix 3.4.4
Cpu: 8 x Intel(R) Xeon(R) CPU E5-2660 v4 @ 2.00GHz
MemTotal: 16Gb
Disk: 300Gb Raid 10 4x15k
Состояние Zabbix:
Количество узлов сети (активированных/деактивированных/шаблонов) >1k
Количество элементов данных (активированных/деактивированных/неподдерживаемых) >60k
Количество триггеров (активированных/деактивированных [проблема/ок]) >20k
Требуемое быстродействие сервера, новые значения в секунду 748
Расчет планируемого места в базе:
В зависимости от необходимого срока хранения и элементов данных.
У нас 60к элементов данных, опрашиваем мы их каждую минуту, т.е. в день у нас получается:
60000 событий x 60 минут x 24 часа = 86400000 событий в день.
Одно событие в среднем занимает около 90 байт, т.е.
86400000 x 90 байт = 7,77Гб в день.
Для трендов Zabbix хранит только ежечасную статистику для каждого элемента (max/min/avg/count), выкидываем из формулы «минуты»:
60000 событий x 24 часа x 90 байт = 0,13Гб в день.
Итог: месяц хранения истории обойдется нам в 230Гб и 4Гб в виде трендов.
Если сделать запрос в базу, то в столбце «size» можно увидеть «большие» таблицы и их размер, который в целом соответствует расчетам.
Лечение:
1) Запросы для чистки базы:
— keep 1 week of history and 3 months of trends \set history_interval 7 \set trends_interval 90 DELETE FROM alerts where age(to_timestamp(alerts.clock)) > (:history_interval * interval ‘1 day’); DELETE FROM acknowledges where age(to_timestamp(acknowledges.clock)) > (:history_interval * interval ‘1 day’); DELETE FROM events where age(to_timestamp(events.clock)) > (:history_interval * interval ‘1 day’); DELETE FROM history where age(to_timestamp(history.clock)) > (:history_interval * interval ‘1 day’); DELETE FROM history_uint where age(to_timestamp(history_uint.clock)) > (:history_interval * interval ‘1 day’) ; DELETE FROM history_str where age(to_timestamp(history_str.clock)) > (:history_interval * interval ‘1 day’) ; DELETE FROM history_text where age(to_timestamp(history_text.clock)) > (:history_interval * interval ‘1 day’) ; DELETE FROM history_log where age(to_timestamp(history_log.clock)) > (:history_interval * interval ‘1 day’) ; DELETE FROM trends where age(to_timestamp(trends.clock)) > (:trends_interval * interval ‘1 day’); DELETE FROM trends_uint where age(to_timestamp(trends_uint.clock)) > (:trends_interval * interval ‘1 day’) ;
2) Обработка базы при помощи pgtoolkit:
pgtoolkit — инструмент для уменьшения раздувания таблиц и индексов без тяжелых блокировок и полной перестройки таблицы (https://github.com/grayhemp/pgtoolkit)
Иногда может возникнуть необходимость проверить и удалить временные индексы, оставшиеся от работы pgcompact:
Результат работы можно увидеть на графиках.
В данном случае я пропустил момент распухания базы и на раздел пришлось экстренно добавлять место.

Чтобы не пропускать переполнение диска, рекомендуется добавить задание в cron:
Если у вас mysql:
При использовании движка базы данных InnoDB, все таблицы и индексы хранятся в системном табличном пространстве (в одном файле /var/lib/mysql/ibdata).
Для того, чтобы хранить каждую таблицу InnoDB и связанные индексы в отдельных файлах — нужно активировать опцию innodb_file_per_table.
Очистка, оптимизация, настройка mysql базы Zabbix
Я работаю с серверами малого и среднего бизнеса, небольших компаний, где требования к объему и производительности базы данных не высоки. Чаще всего хватает дефолтных настроек, поэтому какого-то особенного внимания бд я не уделял. Но сегодня я разберу вопрос большого размера базы данных zabbix, расскажу как ее уменьшить и как оптимизировать ее работу для увеличения быстродействия.
Введение
В своей инструкции по установке и настройке zabbix я вообще не затрагиваю вопрос базы данных mysql или производительности сервера в целом. Я просто беру дефолтные настройки mariadb, которые идут с установкой и использую их. Когда у вас не очень большая инфраструктура на мониторинге этого вполне достаточно, чтобы нормально пользоваться системой.
Если вы активно используете zabbix и внедряете его повсеместно во все используемые системы (а я рекомендую так делать), то вы рано или поздно столкнетесь с вопросом производительности системы мониторинга и размера базы данных zabbix.
Тема производительности zabbix очень индивидуальная. Она напрямую зависит от того, как вы его используете, а схемы мониторинга могут быть очень разные. Одно дело мониторить несколько серверов, а другое дело нагруженные свичи на 48 портов со съемом метрик с каждого порта раз в 30 секунд.
Чтобы помочь вам разобраться в этой теме и прикинуть, к чему готовиться, я поделюсь с вами своим опытом эксплуатации заббикса, его нагрузки, производительности и обслуживания базы данных mysql. Расскажу, как можно уменьшить размер базы.
Как спланировать нагрузку на Zabbix
Под небольшой структурой, упомянутой в начале, я подразумеваю 50-100 узлов (не сетевое оборудование с десятками портов) сети на мониторинге и примерно 2000-4000 активных элементов данных, которые записывают 20-40 новых значений в секунду. Под такую сеть вам будет достаточно небольшой виртуальной машины с 2 ядрами и 4 гб памяти. База данных на преимущественно стандартных шаблонах будет расти примерно на 2-4 Гб в год. Дальше еще меньше, так как будет автоматически очищаться.
Для решения вопроса производительности нужно будет двигаться в двух направлениях:
Каждый из указанных вопросов многогранен. Далее мы частично их рассмотрим и выполним наиболее простые, очевидные и результативные изменения.
Очистка и уменьшение mysql базы zabbix
Начнем с очистки базы данных zabbix от ненужных данных. Рассмотрим по пунктам в той последовательности, в которой это нужно делать.
Для очистки базы данных zabbix от значений неактивных итемов, можно воспользоваться следующими запросами. Запускать их можно как в консоли mysql сервера (максимально быстрый вариант), так и в phpmyadmin, кому как удобнее.
Данными запросами можно прикинуть, сколько данных будет очищено:
Если запросы нормально отрабатывают и возвращают счетчик данных, которые будут удалены, дальше можете их удалять из базы следующими sql запросами.
Данными запросами вы очистите базу данных zabbix от значений неактивных элементов данных. Но реально размер базы данных у вас не уменьшится, потому что в дефолтной настройке базы данных используется формат innodb. Все данные хранятся в файле ibdata1, который автоматически не очищается после удаления данных из базы.
Администрировать такую базу неудобно. Нужно как минимум настроить хранение каждой таблицы в отдельном файле. Этим мы далее и займемся, а заодно обновим сервер базы данных до свежей версии mariadb и реально очистим базу, уменьшив ее размер.
Обновление и настройка сервера mysql
В данном примере я использую сервер CentOS 7. Из стандартных репозиториев устанавливается достаточно старая версия MariaDB 5.5. Для начала обновим ее до последней стабильной на момент написания статьи версии 10.2. Перед этим сделаем полный бэкап базы данных zabbix, предварительно остановив сервер.
Теперь удалим с сервера mysql все базы данных, кроме системных.
Удаляем старые файлы базы zabbix.
Начинаем обновлять сервер. Добавляем репозиторий MariaDB в систему. Для этого создаем файл /etc/yum.repos.d/mariadb.repo следующего содержания:
Далее предлагаю свой вариант конфига для mysql сервера. Положите его в директорию /etc/my.cnf.d.
Сразу предупреждаю, что универсальных настроек для mariadb не существует. Я не большой специалист по тонкой настройке mysql и детально не вникал в оптимизацию работы с zabbix. И тем более не тестировал производительность с разными параметрами. Данный пример это набор рекомендаций, полученных из разных источников. Я сам использую этот конфиг и каких-то нареканий к нему у меня нет, поэтому делюсь с вами. Возможно, тут есть что-то, что совершенно не подходит и надо поменять. Если вы увидите такое, прошу поделиться информацией.
Будет вообще здорово, если кто-то предложит свой более оптимальный конфиг для zabbix. Хотя я понимаю, что настройки будут сильно зависеть от параметров сервера (память и cpu в основном). Их нужно подбирать в каждом конкретном случае. В ситуации со стандартной установкой zabbix, когда проблем с производительностью нет, мне не хочется этим заниматься.
Запускаем сервер mariadb.
Если сервер не стартует, а в логе /var/log/messages ошибка:
Удалите файлы aria_log.
И снова запускайте mariadb. Проверить статус запуска можно командой:
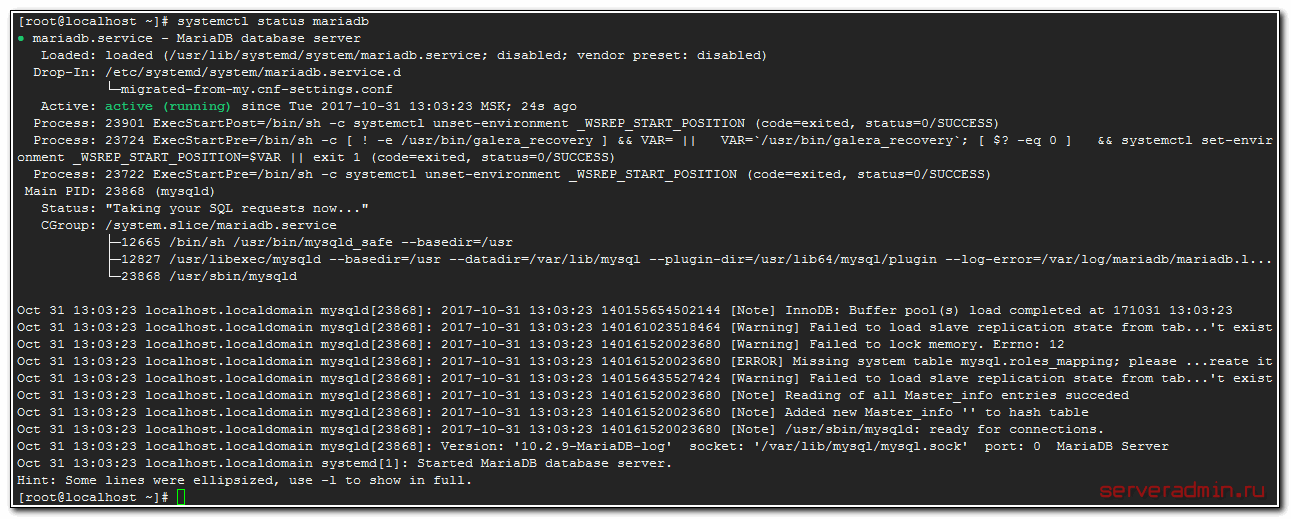
Сервер запустился. Есть пару замечаний, мы их позже исправим. Теперь восстанавливаем базу данных zabbix из выгрузки.
Запускаем утилиту mysql_upgrade для генерации новой базы performance_schema.
Запускаем сервер zabbix.
Проверяем работу. По идее, все должно быть в порядке. Теперь база данных zabbix хранится в директории /var/lib/mysql/zabbix. Она уменьшилась в размере, и каждая таблица хранится в отдельном файле.
Заключение
Я описал простой способ очистки и небольшого увеличения производительности базы zabbix. Кардинально этот вопрос решают с помощью партицирования базы данных mysql. Подробнее об этом можно почитать на сайте заббикса в wiki в разделе howto. Ничего сложного в этом нет, примеров в сети много, но лично я сам не настраивал никогда, не было необходимости.
Высокая производительность и нативное партиционирование: Zabbix с поддержкой TimescaleDB
Zabbix — это система мониторинга. Как и любая другая система, она сталкивается с тремя основными проблемами всех систем мониторинга: сбор и обработка данных, хранение истории, ее очистка.
Этапы получения, обработки и записи данных занимают время. Немного, но для крупной системы это может выливаться в большие задержки. Проблема хранения — это вопрос доступа к данным. Они используются для отчетов, проверок и триггеров. Задержки при доступе к данным также влияют на производительность. Когда БД разрастаются, неактуальные данные приходится удалять. Удаление — это тяжелая операция, которая также съедает часть ресурсов.

Проблемы задержек при сборе и хранении в Zabbix решаются кэшированием: несколько видов кэшей, кэширование в БД. Для решения третьей проблемы кэширование не подходит, поэтому в Zabbix применили TimescaleDB. Об этом расскажет Андрей Гущин — инженер технической поддержки Zabbix SIA. В поддержке Zabbix Андрей больше 6 лет и напрямую сталкивается с производительностью.
Как работает TimescaleDB, какую производительность может дать по сравнению с обычным PostgreSQL? Какую роль играет Zabbix для БД TimescaleDB? Как запустить с нуля и как мигрировать с PostgreSQL и производительность какой конфигурации лучше? Обо всем этом под катом.
Вызовы производительности
Каждая система мониторинга встречается с определенными вызовами производительности. Я расскажу о трех из них: сбор и обработка данных, хранение, очистка истории.
Быстрый сбор и обработка данных. Хорошая система мониторинга должна оперативно получать все данные и обрабатывать их согласно триггерным выражениям — по своим критериям. После обработки система должна также быстро сохранить эти данные в БД, чтобы позже их использовать.
Хранение истории. Хорошая система мониторинга должна хранить историю в БД и предоставлять удобный доступ к метрикам. История нужна, чтобы использовать ее в отчетах, графиках, триггерах, пороговых значениях и вычисляемых элементах данных для оповещения.
Очистка истории. Иногда наступает день, когда вам не нужно хранить метрики. Зачем вам данные, которые собраны за 5 лет назад, месяц или два: какие-то узлы удалены, какие-то хосты или метрики уже не нужны, потому что устарели и перестали собираться. Хорошая система мониторинга должна хранить исторические данные и время от времени их удалять, чтобы БД не разрослась.
Очистка устаревших данных — острый вопрос, который сильно отражается на производительности базы данных.
Кэширование в Zabbix
В Zabbix первый и второй вызовы решены с помощью кэширования. Для сбора и обработки данных используется оперативная память. Для хранения — истории в триггерах, графиках и вычисляемых элементах данных. На стороне БД есть определенное кэширование для основных выборок, например, графиков.
Кэширование на стороне самого Zabbix-сервера это:
ConfigurationCache
Это основной кэш, в котором мы храним метрики, хосты, элементы данных, триггеры — все, что нужно для PreProcessing и для сбора данных.

Все это хранится в ConfigurationCache, чтобы не создавать лишних запросов в БД. После старта сервера мы обновляем этот кэш, создаем и периодически обновляем конфигурации.
Сбор данных
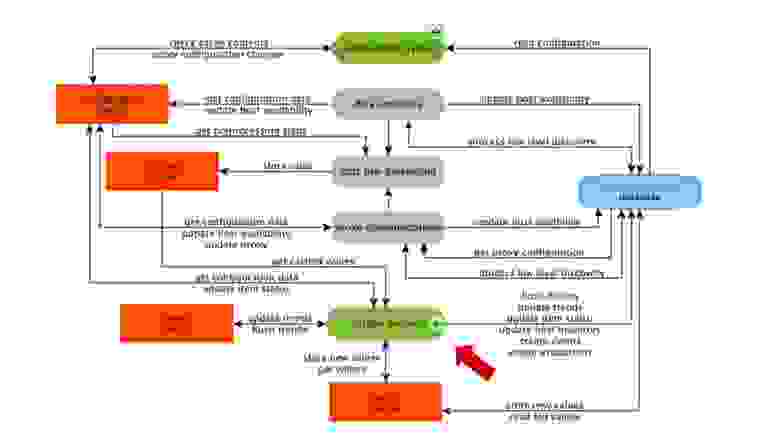
Схема достаточно большая, но основное в ней — это сборщики. Это различные «pollers» — процессы сборки. Они отвечают за разные виды сборки: собирают данные по SNMP, IPMI, и передают это все на PreProcessing.
 Сборщики обведены оранжевой линией.
Сборщики обведены оранжевой линией.
В Zabbix есть вычисляемые агрегационные элементы данных, которые нужны, чтобы агрегировать проверки. Если у нас они есть, мы забираем данные для них напрямую из ValueCache.
PreProcessing HistoryCache
Все сборщики используют ConfigurationCache, чтобы получать задания. Дальше они передают их на PreProcessing.
PreProcessing использует ConfigurationCache, чтобы получать шаги PreProcessing. Он обрабатывает эти данные различными способами.
После обработки данных с помощью PreProcessing, сохраняем их в HistoryCache, чтобы обработать. На этом заканчивается сбор данных и мы переходим к главному процессу в Zabbix — history syncer, так как это монолитная архитектура.
Примечание: PreProcessing достаточно тяжелая операция. С v 4.2 он вынесен на proxy. Если у вас очень большой Zabbix с большим количеством элементов данных и частотой сбора, то это сильно облегчает работу.
ValueCache, history & trends cache
History syncer — это главный процесс, который атомарно обрабатывает каждый элемент данных, то есть каждое значение.
History syncer берет значения из HistoryCache и проверяет в Configuration наличие триггеров для вычислений. Если они есть — вычисляет.
History syncer создает событие, эскалацию, чтобы создать оповещения, если требуется по конфигурации, и записывает. Если есть триггеры для последующей обработки, то это значение он запоминает в ValueCache, чтобы не обращаться в таблицу истории. Так ValueCache наполняется данными, которые необходимы для вычисления триггеров, вычисляемых элементов.
History syncer записывает все данные в БД, а она — в диск. Процесс обработки на этом заканчивается.
Кэширование в БД
На стороне БД есть различные кэши, когда вы хотите смотреть графики или отчеты по событиям:
Производительность БД критически важна
Zabbix-сервер постоянно собирает данные и записывает их. При перезапуске он тоже читает из истории для наполнения ValueCache. Скрипты и отчеты использует Zabbix API, который построен на базе Web-интерфейса. Zabbix API обращается в базу данных и получает необходимые данные для графиков, отчетов, списков событий и последних проблем.
Для визуализации — Grafana. Среди наших пользователей это популярное решение. Она умеет напрямую отправлять запросы через Zabbix API и в БД, и создает определенную конкурентность для получения данных. Поэтому нужна более тонкая и хорошая настройка БД, чтобы соответствовать быстрой выдаче результатов и тестирования.
Housekeeper
Третий вызов производительности в Zabbix — это очистка истории с помощью Housekeeper. Он соблюдает все настройки — в элементах данных указано, сколько хранить динамику изменений (трендов) в днях.
TrendsCache мы вычисляем на лету. Когда поступают данные, мы их агрегируем за один час и записываем в таблицы для динамики изменений трендов.
Housekeeper запускается и удаляет информацию из БД обычными «selects». Это не всегда эффективно, что можно понять по графикам производительности внутренних процессов.
Красный график показывает, что History syncer постоянно занят. Оранжевый график сверху — это Housekeeper, который постоянно запускается. Он ждет от БД, когда она удалит все строки, которые он задал.
Когда стоит отключить Housekeeper? Например, есть «Item ID» и нужно удалить последние 5 тысяч строк за определенное время. Конечно, это происходит по индексам. Но обычно dataset очень большой, и БД все равно считывает с диска и поднимает в кэш. Это всегда очень дорогая операция для БД и, в зависимости от размеров базы, может приводить к проблемам производительности.
Housekeeper просто отключить. В Web-интерфейсе есть настройка в «Administration general» для Housekeeper. Отключаем внутренний Housekeeping для внутренней истории трендов и он больше не управляет этим.
Housekeeper отключили, графики выровнялись — какие в этом случае могут быть проблемы и что может помочь в решении третьего вызова производительности?
Partitioning — секционирование или партиционирование
Обычно партиционирование настраивается различным способом на каждой реляционной БД, которые я перечислил. У каждой своя технология, но они похожи, в целом. Создание новой партиции часто приводит к определенным проблемам.
Обычно партиции настраивают в зависимости от «setup» — количества данных, которые создаются за один день. Как правило, Partitioning выставляют за один день, это минимум. Для трендов новой партиции — за 1 месяц.
Значения могут изменяться в случае очень большого «setup». Если малый «setup» — это до 5 000 nvps (новых значений в секунду), средний — от 5 000 до 25 000, то большой — выше 25 000 nvps. Это большие и очень большие инсталляции, которые требуют тщательной настройки именно базы данных.
На очень больших инсталляциях отрезок в один день может быть не оптимальным. Я видел на MySQL партиции по 40 ГБ и больше за день. Это очень большой объем данных, который может приводить к проблемам, и его нужно уменьшать.
Что дает Partitioning?
Секционирование таблиц. Часто это отдельные файлы на диске. План запросов более оптимально выбирает одну партицию. Обычно партиционирование используется по диапазону — для Zabbix это тоже верно. Мы используем там «timestamp» — время с начала эпохи. У нас это обычные числа. Вы задаете начало и конец дня — это партиция.
Заметно ускоряет выборку данных SELECT — использует одну или более партиций, а не всю таблицу. Если вы обращаетесь за данными двухдневной давности, они выбираются из БД быстрее, потому что нужно загрузить в кэш и выдать только один файл, а не большую таблицу.
Зачастую многие БД также ускоряет INSERT — вставки в child-таблицу.
TimescaleDB
Для v 4.2 мы обратили внимание на TimescaleDB. Это расширение для PostgreSQL с нативным интерфейсом. Расширение эффективно работает с time series данными, при этом не теряя преимуществ реляционных БД. TimescaleDB также автоматически партицирует.
В TimescaleDB есть понятие гипертаблица (hypertable), которую вы создаете. В ней находятся чанки — партиции. Чанки — это автоматически управляемые фрагменты гипертаблицы, который не влияет на другие фрагменты. Для каждого чанка свой временной диапазон.
TimescaleDB vs PostgreSQL
После 200 млн строк PostgreSQL обычно начинает сильно проседать и теряет производительность до 0. TimescaleDB позволяетэффективно вставлять «inserts» при любом объеме данных.
Установка
Установить TimescaleDB достаточно просто для любых пакетов. В документации все подробно описано — он зависит от официальных пакетов PostgreSQL. TimescaleDB также можно собрать и скомпилировать вручную.
Для БД Zabbix мы просто активируем расширение:
Вы активируете extension и создаете его для БД Zabbix. Последний шаг — создание гипертаблицы.
Миграция таблиц истории на TimescaleDB
Для этого есть специальная функция create_hypertable :
У функции три параметра. Первый — таблица в БД, для которой нужно создать гипертаблицу. Второй — поле, по которому надо создать chunk_time_interval — интервал чанков партиций, которые нужно использовать. В моем случае интервал это один день — 86 400.
Конфигурация железа
Я использовал два сервера. Первый — VMware-машина. Она достаточно маленькая: 20 процессоров Intel® Xeon® CPU E5-2630 v 4 @ 2.20GHz, 16 ГБ оперативной памяти и SSD-диск на 200 ГБ.
Я установил на ней PostgreSQL 10.8 с ОС Debian 10.8-1.pgdg90+1 и файловой системой xfs. Все минимально настроил, чтобы использовать именно эту базу данных, за вычетом того, что будет использовать сам Zabbix.
Изначально конфигурация содержала 5 000 элементов данных на каждый хост. Почти каждый элемент содержал триггер, чтобы это было схоже с реальными инсталляциями. В некоторых случаях было больше одного триггера. На один узел сети приходилось 3 000-7 000 триггеров.
Интервал обновления элементов данных — 4-7 секунд. Саму нагрузку я регулировал тем, что использовал не только 50 агентов, но добавлял еще. Также, с помощью элементов данных я динамических регулировал нагрузку и снижал интервал обновления до 4 с.
PostgreSQL. 35 000 nvps
Первый запуск на этом железе у меня был на чистом PostgreSQL — 35 тыс значений в секунду. Как видно, вставка данных занимает фракции секунды — все хорошо и быстро. Единственное, что SSD диск на 200 ГБ быстро заполняется.

Это стандартный dashboard производительности Zabbix — сервера.
Первый голубой график — количество значений в секунду. Второй график справа — загрузка процессов сборки. Третий — загрузка внутренних процессов сборки: history syncers и Housekeeper, который здесь выполнялся достаточное время.
Четвертый график показывает использование HistoryCache. Это некий буфер перед вставкой в БД. Зеленый пятый график показывает использование ValueCache, то есть сколько хитов ValueCache для триггеров — это несколько тысяч значений в секунду.
PostgreSQL. 50 000 nvps
Дальше я увеличил нагрузку до 50 тыс значений в секунду на этом же железе.
При загрузке с Housekeeper вставка 10 тыс значений записывалась 2-3 с.
Housekeeper уже начинает мешать работе.
По третьему графику видно, что, в целом, загрузка трапперов и history syncers пока еще на уровне 60%. На четвертом графике HistoryCache во время работы Housekeeper уже начинает достаточно активно заполняться. Он заполнился на 20% — это около 0,5 ГБ.
PostgreSQL. 80 000 nvps
Дальше я увеличил нагрузку до 80 тыс значений в секунду. Это примерно 400 тыс элементов данных и 280 тыс триггеров.

Вставка по загрузке тридцати history syncers уже достаточно высокая.
Также я увеличивал различные параметры: history syncers, кэши.
На моем железе загрузка history syncers увеличивалась до максимума. HistoryCache быстро заполнился данными — в буфере накопились данные для обработки.
Все это время я наблюдал, как используется процессор, оперативная память и другие параметры системы, и обнаружил, что утилизация дисков была максимальна.

Я добился использования максимальных возможностей диска на этом железе и на этой виртуальной машине. При такой интенсивности PostgreSQL начал сбрасывать данные достаточно активно, и диск уже не успевал работать на запись и чтение.
Второй сервер
Я взял другой сервер, который имел уже 48 процессоров и 128 ГБ оперативной памяти. Затюнинговал его — поставил 60 history syncer, и добился приемлемого быстродействия.
Фактически, это уже предел производительности, где необходимо что-то предпринимать.
TimescaleDB. 80 000 nvps
Моя главная задача — проверить возможности TimescaleDB от нагрузки Zabbix. 80 тыс значений в секунду — это много, частота сбора метрик (кроме Яндекса, конечно) и достаточно большой «setup».
На каждом графике есть провал — это как раз миграция данных. После провалов в Zabbix-сервере профиль загрузки history syncer очень сильно изменился — упал в три раза.
TimescaleDB позволяет вставлять данные практически в 3 раза быстрее и использовать меньше HistoryCache.
Соответственно, у вас своевременно будут поставляться данные.
TimescaleDB. 120 000 nvps
Дальше я увеличил количество элементов данных до 500 тыс. Главная задача была проверить возможности TimescaleDB — я получил расчетное значение 125 тыс значений в секунду.
Это рабочий «setup», который может долго работать. Но так как мой диск был всего на 1,5 ТБ, то я его заполнил за пару дней.
Самое важное, что в это же время создавались новые партиции TimescaleDB.
Для производительности это совершенно незаметно. Когда создаются партиции в MySQL, например, все иначе. Обычно это происходит ночью, потому что блокирует общую вставку, работу с таблицами и может создавать деградацию сервиса. В случае с TimescaleDB этого нет.
Для примера покажу один график из множества в community. На картинке включен TimescaleDB, благодаря этому загрузка по использованию io.weight на процессоре упала. Использование элементов внутренних процессов тоже снизилось. Причем это обычная виртуалка на обычных блинных дисках, а не SSD.

Выводы
TimescaleDB хорошее решение для маленьких «setup», которые упираются в производительность диска. Оно позволит неплохо продолжать работать до миграции БД на железо побыстрее.
TimescaleDB прост в настройке, дает прирост производительности, хорошо работает с Zabbix и имеет преимущества по сравнению с PostgreSQL.
Если вы применяете PostgreSQL и не планируете его менять, то рекомендую использовать PostgreSQL с расширением TimescaleDB в связке с Zabbix. Это решение эффективно работает до средних «setup».
Говорим «высокая производительность» — подразумеваем HighLoad++. Ждать, чтобы познакомиться с технологиями и практиками, позволяющими сервисам обслуживать миллионы пользователей, совсем недолго. Список докладов на 7 и 8 ноября мы уже составили, а вот митапы еще можно предложить.
Подписывайтесь на нашу рассылку и telegram, в которых мы раскрываем фишки предстоящей конференции, и узнайте, как извлечь максимум пользы.
