Методы распознавания текста
Немного теории
Тема распознавания текста попадает под раздел распознавания образов. И для начала коротко о самом распознавании образов.
Распознавание образов или теория распознавания образов это раздел информатики и смежных дисциплин, развивающий основы и методы классификации и идентификации предметов, явлений, процессов, сигналов, ситуаций и т. п. объектов, которые характеризуются конечным набором некоторых свойств и признаков. Данное определение нам дает Wikipedia.
Итак, моя тема — это распознавание текста на графических изображениях и сейчас говорить о важности данного подраздела не приходиться. Всем давно известно, что существуют миллионы старых книг, которые хранятся в хранилищах строгого режима, доступ к которым имеет только специализированный персонал. Использование этих книг запрещено по причине их ветшалости и дряхлости, так как возможно, что они могут рассыпаться прямо в руках читателя, но знания которые они хранят, представляют, несомненно, большой клад для человечества и поэтому оцифровка этих книг столь важна. Именно этим в частности занимаются специалисты в области обработки данных.
Теперь о самой работе. Было написано приложение, способное распознавать текст при использовании изображений высокого либо среднего качества, со слабым шумом либо без него. Приложение способно распознавать буквы английского алфавита, верхнего и нижнего регистра. Изображение подается для распознавания непосредственно из самого приложения.
Фильтрация и обработка

Сегментация
Непосредственно перед распознаванием изображение нормализуется и приводится до размеров шаблонов, подготовленных заранее.
Далее наступает сам процесс распознавания. Для пользователя имеется два выбора, при помощи метрик и при помощи нейронной сети.
Распознавание
Рассмотрим первый случай — распознавание при помощи метрик.
Метрика – некоторое условное значение функции, определяющее положение объекта в пространстве. Таким образом, если два объекта расположены близко друг от друга, то есть похожи (например, две буквы А написанные разным шрифтом), то метрики для таких объектов будут совпадать или быть предельно похожими. Для распознавания в этом режиме была выбрана метрика Хэмминга.
Метрика Хэмминга – метрика которая показывает, как сильно объекты не похожи между собой.
Данную метрику часто используют при кодировании информации и передаче данных. Например, после сеанса передачи на выходе имеется следующая последовательность бит (1001001), также нам известно, что должна прийти другая последовательность бит (1000101). Мы вычисляем метрику путем сравнения частей последовательности с соответствующими местами из другой последовательности. Таким образом метрика Хэмминга в нашем случае равна 2. Так как объекты отличаются в двух позициях. 2- это степень непохожести, чем больше, тем хуже в нашем случае.
Следовательно, чтобы определить какая буква изображена нужно найти ее метрику со всеми готовыми шаблонами. И тот шаблон, чья метрика окажется наиболее близкой к 0 будет ответом.
Но как показала практика подсчет одной лишь метрики не дает положительного результата, так многие буквы похожи между собой. например «j» «i», что приводит к ошибочному распознаванию.
Тогда было принято решение придумать новые метрики, позволяющие разграничить некоторое множество букв в отдельный класс. В частности, были реализованы метрики (Отражения горизонтального и вертикального, преобладания веса горизонтального и вертикального).
Экспериментом было выяснено, что такие буквы как «H» «I» «i» «O» «o» «X» «x» «l» обладают суперсимметрией (полностью совпадают со своими отражениями и значимые пиксели распределены равномерно по всему изображению), поэтому они были вынесены в отдельный класс, что сокращает перебор всех метрик примерно в 6 раз. Аналогичные действия были проведены в отношении других букв. В среднем уменьшение перебора достигает примерно 3 раза.
Также есть уникальная буква такая как «J», которая находится в своем классе одна, и значит идентифицируются однозначно. Далее, для каждого класса высчитывается метрика Хэмминга, которая на данном этапе дает лучшие показатели чем при прямом применении.
При создании шаблонов использовался шрифт «consolas», поэтому, если распознаваемый текст написан этим шрифтом, распознавание имеет точность порядка 99 процентов. При изменении шрифта, точность падает до 70 процентов.
Второй способ распознавания – при помощи нейронной сети.
Что такое нейронная сеть и в биологическом понимании, и в математическом я рассказывать не буду, так как данного материала полно в интернете и повторять его не хочется. Сказать лишь можно то, что в математическом смысле нейронная сеть — это лишь модель биологического определения.
Существуют также множества разновидностей этих моделей. В своей работе я использовал однослойную сеть Кохонена.
Принцип работы нейронной сети таков, что поучив на входной слой нейронов новое изображение сеть реагирует импульсом того или иного нейрона. Так как все нейроны поименованы значениями букв, следовательно, среагировавший нейрон и несет ответ распознавания. Углубляясь в терминологию сетей можно сказать, что нейрон помимо выхода имеет также множество входов. Данные входы описывают значение пикселя изображения. То есть, если имеется изображение 16х16, входов у сети должно быть 256.
Каждый вход воспринимается с определенным коэффициентом и в результате, по окончанию распознавания на каждом нейроне скапливается определенный заряд, чем заряд будет больше тот нейрон и испустит импульс.
Но что бы коэффициенты входов были правильно настроены необходимо сначала обучить сеть. Этим занимается отдельный модуль обучения. Данный модуль берет очередное изображение из обучающей выборки и скармливает сети. Сеть анализирует все позиции черных пикселей и выравнивает коэффициенты минимизируя ошибку совпадения методом градиента, после чего определенному нейрону сопоставляется данное изображение.
Все коэффициенты выровнены и готовы воспринимать изображения.
Точность распознавания при этом методе достигает 80 процентов. Следует заметить, что точность распознавания зависит от обучающей выборки, как от количества, так и от качества.
Оцифровка текста
Как часто мы сталкиваемся с необходимостью срочно распознать текст с картинки и перевести его в текстовый файл? Если вы студент или офисный работник это даже необходимость! В этой статье приведу пару простых способов, которые будут полезны каждому, кто хоть раз сталкивался с этой проблемой.
Существует великое множество онлайн сервисов, программ и приложений для оцифровки текста, приведу пару самых популярных:
Отличный онлайн сервис, не требующий регистрации.
Без ограничений можно бесплатно распознавать файлы в формате JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu, загружать можно сразу по несколько страниц. Может распознавать тексты с изображений в файлах DOC, DOCX, RTF и ODT. Выделять и разворачивать требуемую область текста страницы для распознавания. Поддерживает 58 языков и может сделать перевод текста с помощью Google переводчика. Сохранить полученные результаты распознавания можно в форматах TXT, DOC, ODT, RTF, PDF, HTML.
Бесплатный онлайн сервис по распознаванию текстов, не требующий регистрации. Поддерживает форматы PDF, GIF, BMP, JPEG. Распознав текст, сохраняет в виде URL ссылки с расширением TXT, который можно скопировать и вставить в нужный вам файл. Позволяет загружать одновременно пять документов объемом до 5 МБ.
Здесь требуется регистрация, если нет своего аккаунта в Google. Можно распознавать изображения PNG, JPG, GIF и файлы PDF размером не более 2 МБ. В файлах PDF распознаются только первые десять страниц. Распознанные документы можно сохранять в форматах DOC, TXT, PDF, PRT и ODT.
Пользуясь онлайн переводчиком от Яндекс можно считать текст с картинки на 42 языках и перевести на имеющиеся 95 языков. Регистрации не требуется, возможно загрузить только одно изображение за раз.
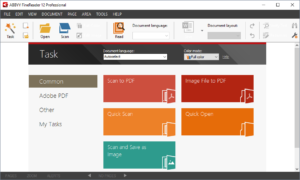
Профессиональная система оптического распознавания текста. Её устанавливают не только для домашнего использования, но также и в крупных компаниях. Пожалуй, это самый популярный софт в данном сегменте. Единственное, что следует иметь в виду – в полной версии программа платная. Однако, можно скачать и бесплатный вариант, так называемую испытательную версию ABBYY FineReader: Home Edition. Она будет работать в течение 15 дней и за это время сможет распознать 50 страниц. Программа позволит из бумажных документов, PDF-файлов и цифровых фото сделать редактируемый текст. Она распознает 179 языков и экспортирует тексты в Word, Excel, PowerPoint или Outlook.
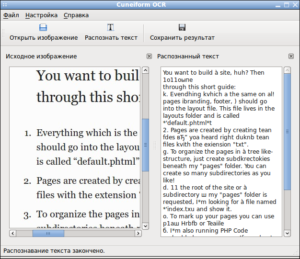
Это совершенно бесплатная программа от российского разработчика Cognitive OpenOCR. Среди возможностей CuneiForm — сканирование текста и изображений; распознавание текста на 20 языках; работа с различными шрифтами (книжными, газетными, с пишущих машинок); распознавание таблиц и их содержимого (в том числе без сетки); «понимание» как чёрно-белых, так и цветных документов.
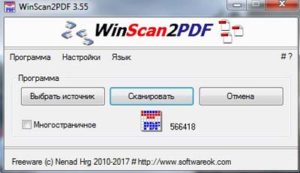
Пожалуй, самая простая программа для сканирования текста. Запустив ее, вы сможете управлять меню WinScan2PDF, в котором будет всего три кнопки: «Выбрать источник», «Сканировать в PDF», «Отмена». Что касается настроек, то их практически нет. Разве что выбор языка при инсталляции (к слову, есть и русский). Таким образом, отсканировать документ можно всего одним кликом. При этом разработка с легкостью обеспечивает сохранение большого количества документов в PDF.
Приложения для смартфона

Этот сервис от компании Microsoft превращает камеру смартфона или ПК в мощный сканер документов. С помощью Office Lens вы можете распознать текст на любом физическом носителе и сохранить его в одном из «офисных» форматов или в PDF. Итоговые текстовые файлы можно редактировать в Word, OneNote и других сервисах Microsoft, интегрированных с Office Lens.
Adobe Scan 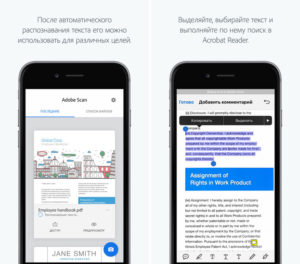
Adobe Scan тоже использует камеру смартфона, чтобы сканировать бумажные документы, но сохраняет их копии только в формате PDF. Результаты удобно экспортировать в кросс-платформенный сервис Adobe Acrobat, который позволяет редактировать PDF-файлы: выделять, подчёркивать и зачёркивать слова, выполнять поиск по тексту и добавлять комментарии.
CamScanner является одним из самых популярных
Scanner Pro by Readdle
Платное приложение. Доступно два режима сканирования. В первом случае мы фотографируем объект и сразу приступаем к его обработке, а во втором — делаем несколько снимков подряд, затем редактируем снятые изображения по очереди. Во время фокусировки приложение практически идеально определяет границы документа. После того, как фотография готова, мы можем выбрать один из двух фильтров, изменить яркость и контрастность для лучшего отображения. Готовый документ можно сохранить в фотопленку, отправить на почту или в облачное хранилище в формате JPEG или PDF.
Подытожим, в наш век технологий оцифровать текст с изображения в удобный для вас формат не так уж и сложно, достаточно сделать пару кликов.
Сервисы для распознавания текста — подборка лучших


Заказчик прислал сканы рабочих документов, в университете скинули фотку конспекта? Когда-то тексты умели распознавать только сканеры и то далеко не все. Сейчас же даже приложения на смартфоне могут перевести визуальный текст в редактируемый документ. А в этом материале ищем лучшие сервисы по распознаванию текста для вашего компьютера и смартфона тоже.
Finereaderonline.com
Компания ABBYY идет в плане распознавания текстов и обработки цифровых документов впереди всех. В арсенале их софта даже цифровые подписи, которые почти невозможно отличить от настоящих. Finereaderonline поддерживает почти 200 языков, работает быстро и онлайн — ничего не надо устанавливать. Можно выбрать разные форматы для сохранения текста, обработка текста происходит очень быстро и достаточно точно. Единственный нюанс — лимит на загрузку файлов до 100 Мб. Но никто не запрещает вам загрузить несколько документов подряд. Сервис работает полностью онлайн, русифицирован и интуитивно понятен в управлении.
Sodapdf.com
Еще один неплохой сервис, хотя тут нам предлагают скачать прогу отдельно. Правда, чуть менее обученный, чем софт от ABYYY — Sodapdf знает только 46 языков. Впрочем, если вам не нужно переводить с ацтекского или зулу, то проблем не возникнет. Программа условно бесплатная — есть триальная версия, полный функционал стоит от 7 до 17 евро в месяц в зависимости от пакета. Soda умеет конвертировать разные форматы, распознавать тексты, ставить электронные подписи и имеет большой набор инструментов для работы с PDF файлами и изображениями.

WinScan2PDF
Элементарная, простая маленькая утилита, которая состоит из трех кнопок: «выбрать источник», «сканировать» и подтвердить или отменить операцию. Поддерживает 23 языка, работает с многостраничными файлами и сохраняет обработанный файл в формате PDF. У этой программы есть одна особенность — она не работает с готовыми файлами и считывает документы только с подключенного сканера.

Free Online OCR
Не такой симпатичный, как Finereader, но тоже вполне умелый онлайн-сервис. Англоязычный, слегка устаревший интерфейс, в котором, впрочем, несложно разобраться. Free Online OCR поддерживает 106 языков и распознает текст с большинства самых популярных форматов файлов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu. Сохранять готовые доки может не только в PDF, но и в стандарных doc и txt. Кроме текста, может распознать математические уравнения, правильно форматировать текст в колонках и столбцах или обработать только выделенный фрагмент. Качество распознавания довольно высокое даже c картинок низкого качества.

Microsoft OneNote
Распознавание текста здесь скорее дополнительная фича, а не основная задача. Вы можете вставить картинку в текущую запись OneNote и правой кнопкой мыши выбрать «Копировать текст из рисунка». Цифровая записная книжка от Microsoft однозначно не подойдет для обработки больших файлов, документов и постоянной работы с файлами. Но может помочь в мелких повседневных задачах — перевести небольшой текст с картинки, скриншота, рекламного макета, чтобы не вводить вручную. Качество распознавания у OneNote не очень высокое, а добавлять в файл многостраничные документы неудобно. Но OneNote и не для этого все-таки.

Readiris
Мощный и удобный конкурент ABBYY FineReader. Быстро и очень чисто распознает даже едва различимые тексты, при этом поддерживает 137 языков, включая русский. Работает очень быстро и легко обрабатывает даже большие объемы текста. Сохраняет исходное форматирование, не игнорируя кавычки, размеры шрифта и стиль написания. Может почистить текст от помарок и предложить исправления в словах. Знает символы, уравнения. Контактирует со сканерами, облачными сервисами, поддерживает кучу форматов. В общем, полноценный и удобный сервис, который не умеет разве что редактировать итоговый файл PDF. Правда, за полный инструментарий придется платить, но есть бесплатная триальная версия.

Img2txt.com
Приятный дизайн, понятный интерфейс и высокая скорость обработки текста — что еще нужно для работы? Продвинутые алгоритмы распознавания помогают считывать документы даже плохого качества. Молниеносно конвертирует большие объемы текста, но при желании можно выбрать отдельную область файла для работы. Есть интеграция с Google Documents, хороший инструментарий для работы с документами PDF. Маловато языков — всего 35, но для основных задач этого может вполне хватить.

OCR CuneiForm
Шустро и тщательно распознает сфотографированные или отсканированные тексты, графические файлы. Старается сохранить исходную структуру текста, элементов и шрифты. Переводит все в редактируемые форматы на выбор. В общем, стандартный набор функционала. И, что самое главное, полностью бесплатный.
TextGrabber 6
Полностью бесплатное приложение для смартфонов за авторством компании ABBYY. Собственно, этим все сказано — в TextGrabber 6 все хорошо с распознаванием текста, есть встроенный модуль переводчика. Программа работает с помощью камеры и на распознавание, и на перевод. Поддерживает кучу языков, работает быстро и выглядит приятно.
Что такое оцифровка?
![]()
Сканирование, ретроконверсия и сопутствующие услуги. Обзор технологий перевода документов в электронный вид.
Существует несколько вариантов организации процессов оцифровки. Они могут производиться самостоятельно или с аутсорсингом услуг, с вывозом документов или выполнением работ на своей территории. При оцифровке могут применяться офисные, профессиональные документные или планетарные сканеры. Данные могут извлекаться в ручном, полуавтоматическом или автоматическом режимах, с проведением предварительной архивной обработки бумажных документов или классификацией информации уже в электронном виде и т.д.
Какой путь выбрать?
Решение зависит от конкретной задачи, потому что каждое из вышеупомянутых «или» определяет качество получаемого результата и стоимость работ. Например, извечен вопрос сшитых документов: выгодней медленно отсканировать в сшитом состоянии или потратиться на расшивку, зато быстро оцифровать на документных сканерах?
Самый простой способ выбрать наиболее подходящий для вас путь – обратиться за экспертизой к специализирующейся на оцифровке организации. Заинтересованные в работах, крупные компании проведут обследование бесплатно, и за вас определят оптимальный подход. Не пренебрегайте этой возможностью и не ждите склонения к заказу услуг: большинство этих компаний также заинтересованы в поставке оборудования и ПО для самостоятельной оцифровки.
Сколько документов нужно сканировать?

Определяющий параметр – объем документов.
Определяющий параметр – объем документов. Для ежедневного сканирования небольших пачек расшитых документов (например, первичной бухгалтерии) подойдет обычный офисный сканер, выдерживающий нагрузку в несколько тысяч страниц в день. Нужно лишь дополнить его удобной программой для индексирования.
Для регулярного сканирования больших объемов необходимо профессиональное оборудование. Это – промышленные сканеры, которые стоят немалых денег (подобное оборудование используют ФНС, ФТС, крупные банки). Поэтому менее дорогой альтернативой может стать рамочное соглашение на оказание периодических услуг оцифровки.
Перевод в электронный вид больших ретроспективных массивов своими силами экономически не обоснован: помимо закупки оборудования и обучения сотрудников, потребуются значительные трудовые и временные затраты. Однозначно эффективнее заказывать услугу, так как крупная компания может выделить большой штат и решить задачу оперативно.
Где сканировать документы?
Определяющий параметр – востребованность сканируемых документов. Влияет ли на деятельность организации изъятие документов на время сканирования? Особенно это критично при оцифровке документов, к которым регулярно обращаются сотрудники, либо которые могут быть внезапно запрошены контролирующим органом, а также для устранения связанных с документами ЧП. Примеры: финансовые и кадровые документы, техническая и эксплуатационная документация, книги ЗАГС и другие отраслевые фонды.

Участок сканирования, организованный в помещениях компании-заказчика услуг.
Если необходимо оцифровать их достаточно быстро, то традиционным подходом является заказ услуг с выездом бригады сканирования на вашу территорию. Зачастую это оказывается дешевле, чем доставлять документы на производство исполнителя и обратно, но все определяет территориальная удаленность. Регламент выездных работ подразумевает сканирование выданного дела в течение одного-двух рабочих дней, без длительного изъятия из рабочего процесса.
Расшивать ли документы?
Определяющие параметры: состояние документов и возможность расшивки. Если есть такая возможность, и бумага пригодна для протяжки документным сканером, то следует расшивать. Дело в том, что сканирование сшитых документов на планетарном (книжном) сканере в несколько десятков раз медленнее потоковой оцифровки. Пропорционально увеличиваются время работ и стоимость труда. Сканирование на документных сканерах, даже с учетом расшивки, оперативнее и дешевле.

Расшивать можно самостоятельно, а можно доверить это исполнителю.
Расшивать можно самостоятельно, а можно доверить это исполнителю: если выбрана авторитетная компания, опасаться утраты документов не стоит. Наоборот, жесткая регламентация всех процессов и качественные материалы позволяют компаниям застраховаться от дополнительных финансовых потерь и ущерба имиджу. Этому подходу доверяют даже российские суды: при организации сканирования обычно внутренним приказом разрешается расшивка и последующая сшивка судебных дел.
К слову, крупные компании параллельно могут провести профессиональную архивную обработку: во-первых, часть работ итак выполняется при подготовке к сканированию, во-вторых, архивная обработка помогает выявить невостребованные документы и сократить объемы сканируемых массивов, что может снизить стоимость работ.
Какое качество выбрать?

Сегодня высококачественно можно отсканировать любой объект: от маленькой библиотечной карточки до карт формата 8А0 и театральных декораций.
Определяющие параметры: вид документа и объем получаемого ресурса в электронной форме. Сегодня сканирующее оборудование позволяет получать образы с разрешением от 200 до 1200 точек на дюйм (dpi). Для художественных произведений обычно применяется разрешение 400–600 dpi, позволяющее создавать высококачественные репродукции. Более высокое качество используется только при необходимости увеличения изображения и детализации мелких предметов, например, монет.
Детализированные и неконтрастные чертежи, часто выполненные на кальке и синьке, нуждаются в сканировании с разрешением 300-400 точек на дюйм и дополнительной обработке изображений в графических редакторах. Остальные документы обычно сканируются с разрешением 300 dpi, достаточным для распечатки копий без потери качества. Необходимая обрезка изображений, геометрическое исправление, цветокоррекция, конвертация в форматы pdf, tiff, jpegи др. может проводиться в полностью автоматическом режиме программами, встроенными в сканирующее оборудование или поставляемыми вместе с ним.
В большинстве случаев используется цветной режим съемки. Это нужно для всех документов, в которые вносились исправления или ставились печати поверх текста, для удостоверения того, что электронная копия снималась с оригинала документа с печатью и подписью, а также для читаемости угасающих текстов и передачи уникальных особенностей оригинала. Необходимость цветного сканирования художественных произведений не обсуждается. Режим «градации серого» применяется лишь в некоторых случаях: когда документы не содержат цветных атрибутов, либо когда необходимо сократить объем получаемого электронного ресурса.
Сканирование может осуществляться самостоятельно. Главной задачей становится обучение сотрудников правильной работе со сложной техникой, так как качество получаемых изображений важно для последующего индексирования: плохо отсканированный документ, тени, засветка и другие дефекты на электронном образе могут сделать нечитаемой важную информацию. Это не позволит применить технологии автоматического извлечения данных и может привести к ошибкам в индексировании. Загрузка ошибочных данных в некоторые системы (государственные реестры, бухгалтерские учетные системы) не позволительна.
Индексирование
Простое сканирование применяется редко, поскольку при последующей работе искать информацию в наборе графических файлов будет лишь немногим проще перелистывания бумаги. Для возможности поиска необходимо выделить в документе несколько атрибутов (индексных полей).

Сотрудники, задействованные в массовом индексировании документов методом ручного ввода.
Выделенные атрибуты можно внести в имя файла. Такая практика сложилась в российских судах: для того чтобы оператор сканирования не имел доступа к внутренним системам суда, при оцифровке все необходимые реквизиты вносятся в имя файла. В последующем эти реквизиты распознаются системой судопроизводства при загрузке каждого документа по отдельности.
Но обычно оцифрованные документы загружаются в информационную систему группой, что требует создания базы данных. Так, если необходимо прикрепить документ к уже существующей карточке в учетной системе, бывает достаточно извлечь пару однозначно определяющих его реквизитов – обычно номер и дату.
Если же нужно сформировать поисковую базу на основании самих документов, то объем извлекаемых данных определяется задачей: от пары реквизитов для поиска файла в электронном архиве до переноса всей значимой информации в аналитическую БД (ФИО, адресов, ИНН, КПП, дат, номеров документов-приложений и т.д.).
Свои правила индексирования применяются в музеях, библиотеках и архивах при оцифровке единиц хранения и учетных документов. Отдельным направлением услуг также является векторизация, которая применяется, в частности, при оцифровке каротажных лент (автоматическая) и чертежей (ручная отрисовка в CAD-системах).
Сколько данных извлекать?Ответ на этот вопрос также лучше получить, воспользовавшись экспертизой, так как количество извлекаемых реквизитов зависит от функциональной задачи и в значительной мере определяет стоимость оцифровки. В некоторых случаях можно ограничиться подборками документов, когда электронные образы объединяются под эгидой основного документа (например, договора или реестра счетов). В других необходимо извлечение всех содержащихся в документе данных для заполнения карточки информационной системы.
Примеры извлекаемых данных
Анализ размещенных на портале zakupki.gov.ru заказов компаний с государственным участием и госучреждений (44-ФЗ, 223-ФЗ), показывает, что:
– Для привязки электронных копий ОРД к системе электронного документооборота достаточно номера, даты и типа документа.
– Сканирование финансовой документации часто сопровождается извлечением номера, даты, наименований и реквизитов плательщиков, сумм.
– Оцифровка архивных документов муниципалитетов (постановления администраций, горисполкомов, сельсоветов и т.д.) в целях оказания услуг и инвентаризации объектов земельно-имущественных отношений требует извлечения номера и даты документа, всех встречаемых ФИО и адресов. Причем адреса необходимо сопоставлять с текущими справочниками КЛАДР/ФИАС.
– Оцифровка документов Архивного фонда РФ сопровождается строгим заполнением НСА и описанием фондов в соответствии с архивным законодательством.
– Индексирование описей и реестров подразумевает распознаванием всех порядковых записей.
– Для работы с чертежами в электронном виде необходимо извлечь практически все поля штампа.
– Сканирование составных дел требует не только извлечения реквизита каждого документа, но и установления взаимосвязей. Наиболее сложен случай конструкторской документации, где формируемая база данных обладает многоуровневой иерархией и связями документов.
Источник: zakupki.gov.ru, 2015
Какие методы извлечения данных выбрать?
Определяющий параметр – качество текста. Применяемые технологии, скорость и стоимость формирования баз данных зависят от того, как написан и в каком состоянии находится текст документа.
Напечатанный на современном принтере текст может быть автоматически распознан, необходимые данные могут быть извлечены с использованием различных автоматизированных методов: применением шаблонов и автоэкстракцией индексов (алгоритмы определения ключевых слов, семантического анализа и т.д.). Эти методы быстрые, и в большинстве случаев их стоимость ниже цены ручного распознавания.
Напечатанные необычным шрифтом, в низком качестве или поврежденные тексты книг, газет, архивных документов распознаются не всегда или с недостаточной точностью. Поэтому в большинстве случаев требуется ручной ввод или, по крайней мере, ручная проверка сведений. Предварительно для каждого ресурса формируются или подключаются внешние справочники, которые помогают операторам индексирования и значительно ускоряют процесс.
Документы с рукописным текстом индексируются только вручную. Это гораздо более медленный и дорогой процесс. Поэтому крупные компании применяют уникальные технологии, служащие ускорению обработки и, соответственно, снижению цены без потери качества. Показателен пример официальной переписки: в этих документах традиционно реквизиты печатаются, а номер и дата проставляется вручную по факту, что делает невозможным полноценное программное индексирование.
Можно ли провести индексирование самостоятельно?

Альтернативой является технология извлечения данных с помощью анализа текста, применимая для любых документов, в том числе неструктурированных. Этот метод зачастую более доступен по цене, но предлагается только парой крупных компаний, так как требует накопления серьезной семантическо-морфологической базы для каждой отрасли деятельности.
Можно также вносить данные напрямую в информационную систему. Однако этот способ связан с высокой вероятностью ошибок, отследить которые в системе крайне сложно. При самостоятельном индексировании рекомендуется сначала создавать определенную базу данных, которую перед загрузкой можно проверить.
Именно так работают специализирующиеся на оцифровке компании: жесткая регламентация процесса, с протоколированием всех действий, и обязательная проверка сформированного массива ОКК позволяет минимизировать количество возможных ошибок. Например, корпорацией ЭЛАР в официальных договорах и контрактах используется стандартный критерий качества ≥99,8%. Теме выборы критериев качества будет посвящена одна из следующих статей.
