Анализируем стоимость текстурирования в современных видеокартах
реклама
С момента появления первых серьёзных ускорителей трёхмерной графики, показатель производительности блока наложения текстур (Texture Mapping Unit, TMU) считался одним из самых важных при выборе 3D ускорителя. По сути, наложение текстур до сих пор является базовым функционалом, который присутствует в любом графическом ускорителе. Более того, этот функционал не желает никуда уходить и, судя по всему, будет сопровождать нас на протяжении ещё нескольких десятилетий, потому что титаны мировой индустрии всеми силами отказываются от перехода на воксельные технологии, продолжая кормить нас треугольными полигонами с текстурами. В итоге мы имеем то, что от факта того, насколько быстро видеокарта наложит текстуры на 3D модели объектов, зависит то, насколько быстро мы сможем увидеть объект на экране.
Понятно, что со временем технологии менялись, процесс визуализации сцены усложнялся и по одному только параметру скорости наложения текстур нельзя измерять производительность всей видеокарты, но всё это не может отрицать роли блока текстурирования, ведь если не будет текстур, то на экране мы увидим только WireFrame, палочки каркаса, понять происходящее в игре по которым будет практически невозможно.
реклама
Мы можем прожить без «вау» специальных эффектов (FX, effects) типа красивых перекатов волн морской воды, развевающихся на ветру белых волос эльфийки или огня с искрами от костров орков. Мы можем прожить без красивых теней, без «анти-элайзинга» (anti aliasing) текстур и без эффектов «эмбиент эклюжен» (ambient occlusion). Многие профессиональные геймеры специально отключают эти эффекты, пожирающие количество кадров в секунду, когда становится важна молниеносность реакции на действия в игре.
Более того, если изучить историю, то можно вспомнить, что аппаратная поддержка трансформации и освещения (Hardware T&L) в видеокартах появилась только с приходом легендарной видеокарты GeForce 256 от nVidia одиннадцатого октября 1999 года (11.10.1999). У знаменитой карты Voodoo5 5500 фирмы 3dfx не было никакой аппаратной реализации T&L, и люди ведь как-то жили и играли в трёхмерные игры. И, Боже упаси, большинству из нас до сих пор не важна трассировка лучей в реальном времени, потому что на быстрой скорости передвижения персонажа игры человеческий глаз не способен уловить все эти тонкости.
Можно сказать точно, что без текстур в играх мы пройти игру не сможем. Весь игровой мир без текстур на объектах рассыпется в труху. Всем, кто отрицает важность текстур в мире 3D визуализации можем только предложить посмотреть на следующий кадр из замечательного фильма с названием «13-ый Этаж».
реклама
Если Вы не испугались всего ранее сказанного и до сих пор остались на этой странице, то нижеследующий анализ предназначен для Вас.
реклама
Каждая серия видеокарт выделена в подраздел, отделённый сплошной линией. Для каждой серии цветным фоном выделена карта с наиболее выгодным соотношением между ценой и производительностью блока TMU. Отдельно, для самой эффективной по наложению текстур видеокарты жирным текстом выделена её стоимость в долларах США (USD), отражающая её привлекательность для конченого потребителя.
Предоставляем читателю возможность самостоятельно сделать выводы из имеющихся данных. Каждый, кому это будет интересно, сможет увидеть в таблице то, что захочет.
Как верно было замечено в комментариях ко статье, в исходных данных, взятых с сайта Википедия, оказалась неточность. Для полноты картины были проведены дополнительные расчёты по данным, взятым с сайта TechPowerUp, которые содержат более точную информацию по производительности блока TMU.
Блоки адресации, выборки и фильтрации текстур
в составе современных графических чипов
Более подробно ознакомиться с 3D терминологией можно в статье Ликбез по 3D.
Немного истории
Трудно переоценить значение специализированных блоков загрузки и фильтрации текстур в составе архитектуры современного графического процессора. Собственно, аппаратное ускорение 3D-графики на персональных компьютерах началось именно с их появления. Первый удачный 3D-акселератор для массового рынка, Voodoo Graphics, был двухчиповым решением. Один чип, TexelFX, представлял собой один простой текстурный блок, загружавший четыре текселя и выполнявший билинейную интерполяцию между ними за один такт. Другой чип, PixelFX, являлся простым блоком растеризации (ROP), выводящим один пиксель за такт. В Voodoo 2 был добавлен второй текстурный блок, что позволило применять несколько более сложные эффекты, накладывая до двух текстур на пиксель за такт. Либо, если игра не поддерживала мультитекстурирования, включать трилинейную фильтрацию.
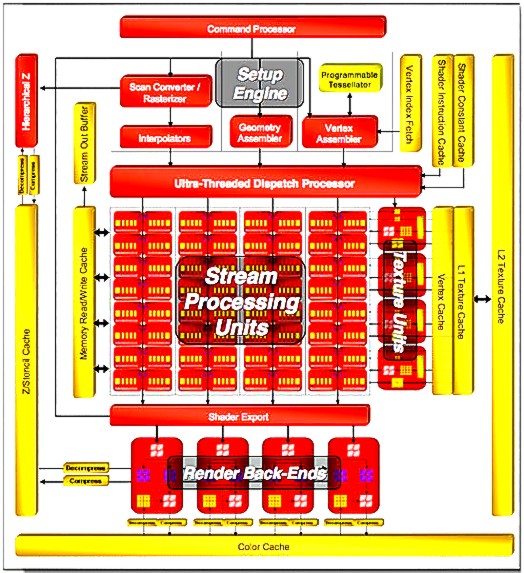
R580+ в качестве примера старой архитектуры
![]()
R580+ имел 48 пиксельных процессоров, распределенных по четырем SIMD-квадам (пиксельные процессоры одного квада выполняли одни и те же инструкции, но над разными пикселями). При этом, внутри квадов они были сгруппированы в группы по 3. К каждой группе был привязан свой текстурный блок, который получал инструкцию одновременно со своей группой пиксельных процессоров.
Текстурный блок мог выбирать до четырех текселей и выполнять одну билинейную интерполяцию за такт до 16-ти раз за проход. Поддерживалась адресация текстур размером до 4096х4096. Поддерживались сжатые форматы DXTC/S3TC 1-5 и 3DC+. Отличие 3DC+ от 3DC, в дополнение к 4:1 компрессии двухканальных текстур, заключается в поддержке 2:1 компрессии одноканальных текстур, которые могут быть использованы для карт освещения или затенения, для хранения свойств материалов и т.п.. Конечно же, можно было выполнять анизотропную фильтрацию степенью до 16х.
Учитывая соотношение 3:1 количества пиксельных процессоров к количеству текстурных блоков, в чипах ATI, начиная с RV530, была введена поддержка технологии под названием Fetch4, призванной ускорить выборку из одноканальных текстур в 4 раза.
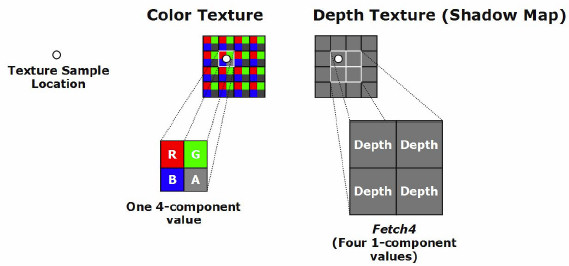
Обычные текстуры являются четырёхканальными (красный, зелёный, синий цвета и альфа-канал). Fetch4 использует 4 канала RGBA для одновременной выборки из четырёх текселей одноканальной текстуры. Основное применение этой технологии видится в чтении карт теней и в последующем усреднении значений затенённости в пиксельном шейдере.
Отдельно остановимся на вопросе доступа к текстурам из вершинного шейдера. SM3.0 требует возможность текстурирования в вершинном шейдере, в то время как WHQL сертицифицированный R580+ не имел никаких специальных узлов для доступа к текстурам из вершинных процессоров. Этот факт породил немало недоумений о неполном соответствии R580+ спецификациям SM3.0. Все дело в том, что хотя бит возможности текстурирования в вершинном шейдере и должен быть включен, спецификация SM3.0 не диктует каких-либо форматов текстур, которые должен поддерживать вершинный процесор. Этой брешью в спецификации успешно пользовался R580+, проходя все SM3.0 тесты Microsoft.
ATI осознанно не стала внедрять модули текстурирования в вершинные процессоры. Внедрение полноценных блоков для адресации, выборки, фильтрации и кеширования текстур в каждый из 8-ми вершинных процессоров потребовало бы слишком много места на кристалле, либо сокращая функциональность других блоков графического контроллера, либо лимитируя его частотный потенциал. Внедрение простых текстурников с минимальной функциональностью, как было сделано, например, в NV40, ATI также сочла нерациональным. Позиция ATI в этом вопросе выглядит особенно убедительно в свете вскоре свершившегося перехода на унифицированную архитектуру, где вершинные и пиксельные шейдеры выполняются одними и теми же функциональными блоками, и вершинные шейдеры, наконец, получили прямой доступ к мощным текстурным модулям, ранее используемым только пиксельными процессорами.
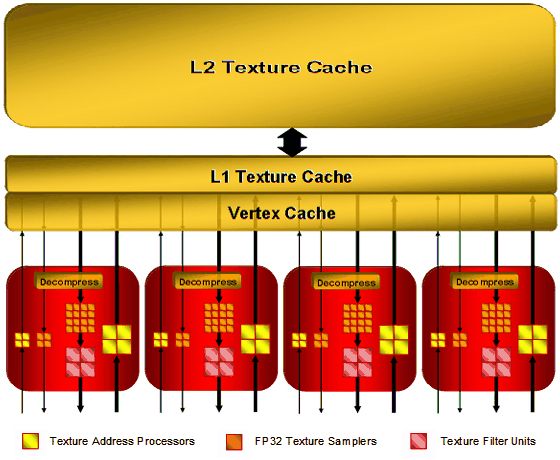
Текстурные блоки R600
R600 имеет квартет текстурных блоков, и они теперь почти полностью отделены от вычислительных массивов АЛУ. Единственным ограничением является привязанность каждого текстурного блока к своим квадам шейдерных процессоров. Т.е., если представить R600 как 4 массива по 16 шейдерных блоков, то каждый массив представляет собой 4 квада, и каждый текстурный блок загружает данные только в свой квад в каждом из четырёх массивов.
Была добавлена поддержка адресации 8192х8192 текстур, а также нового 32-бит RGBE (9:9:9:5) формата. По-прежнему поддерживается Fetch4, и появилась поддержка PCF (Percentage Closer Filtering), благодаря её включению в DirectX 10. PCF долгое время оставалась проблемой для ATI, т.к. она не была документирована в DirectX и вообще являлась интеллектуальной собственностью SGI, доступ к которой nVidia получила путём специального соглашения. Тем не менее, технология смогла получить широкую поддержку в играх, благодаря использованию NV2A в игровой приставке XBOX, где поведение PCF было хорошо известно разработчикам. Реализация технологии сходна с применением Fetch4 для сглаживания теней, за исключением того, что PCF усредняет значения текселей аппаратно блоком фильтрации текстур.
Текстурные блоки имеют L1 кеши по 32 КБ каждый, вершинный кеш может использоваться для ускорения поточечных выборок (у RV610 вершинный и L1 кеши сложены в один), размер L2 кеша равен 256 КБ у R600 и 128 КБ у RV630 (RV610 не имеет L2 текстурного кеша).
Текстурные блоки управляются выделенным арбитром. Одновременно может быть запущено множество потоков, чтобы блоки выборки и фильтрации (как следствие и шейдерные процессоры) простаивали как можно меньше времени. Этот арбитр работает совместно с арбитром шейдерных процессоров, который останавливает потоки (отдавая ресурсы другим потокам), ждущие данных от текстурных блоков.
Текстурные блоки G80
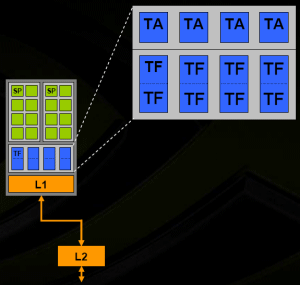
В G80 текстурные блоки всё ещё плотно привязаны к своим кластерам шейдерных процессоров. Это несколько снижает производительность, т.к. процессоры не могут использовать «чужие» текстурники, даже когда те свободны.
Текстурные блоки имеют L1 кеши по 8 КБ каждый. L2 кеш, объём которого равен 128 КБ, текстурные блоки делят с блоками ROP. По всей видимости, текстурные блоки G80 используются для доступа к буферам констант шейдерными процессорами, что может негативно сказаться на производительности DirectX 10 приложений.
Текстурные блоки G80 также управляются арбитрами отдельно от шейдерных процессоров.
В чипах G84 и G92, появившихся после G80, каждый кластер шейдерных процессоров уже включает по 8 блоков адресации текстур.
Заключение
Сравним некоторые пиковые теоретические возможности текстурных блоков R580+, R600 и G80 таблицей.
| Чип | R580+ | R600 | G80 |
| Видеокарта | Radeon X1950 XTX | Radeon HD 2900 XT 1 GB | GeForce 8800 Ultra |
| Частота | 650 МГц | 825 МГц | 612 МГц |
| Текстурных блоков | 16 | 4 | 8 |
| Кеш L1 | 2 КБ * 16 | 32 КБ * 4 + вершинный | 8 КБ * 8 |
| Кеш L2 | ? | 256 КБ | 128 КБ |
| Текстур за проход | 16 | 128 | 128 |
| Блоков адресации | 1 * 16 (16) | 8 * 4 (32) | 4 * 8 (32) |
| Блоков выборки (в единицах AMD) | 4 * 16 (64) | 20 * 4 (80) | 32 * 8 (256) |
| Блоков фильтрации | 1 * 16 (16) | 4 * 4 (16) | 8 * 8 (64) |
| INT8 выборок за такт для билинейной фильтрации | 4 * 16 (64) | 16 * 4 (64) | 32 * 8 (256) |
| FP16 выборок за такт | ½ * 4 * 16 (32) | 1 * 20 * 4 (80) | ½ * 32 * 8 (128) |
| FP32 выборок за такт | ¼ * 4 * 16 (16) | 1 * 20 * 4 (80) | ¼ * 32 * 8 (64) |
| Трилинейных фильтраций INT8 за такт | ½ * 1 * 16 (8) | ½ * 4 * 4 (8) | ½ * 8 * 8 (32) |
| Билинейных фильтраций FP16 за такт | — | 1 * 4 * 4 (16) | ½ * 8 * 8 (32) |
| Билинейных фильтраций FP32 за такт | — | ½ * 4 * 4 (8) | ¼ * 8 * 8 (16) |
| Билинейных фильтраций одноканальных FP32 за такт | — | 1 * 4 * 4 (16) | ¼ * 8 * 8 (16) |
| Трилинейных фильтраций INT8 в секунду | 8 * 650 * 10^6 (5.2 млрд) | 8 * 825 * 10^6 (6.6 млрд) | 32 * 612 * 10^6 (19.6 млрд) |
| Билинейных фильтраций FP16 в секунду | — | 16 * 825 * 10^6 (13.2 млрд) | 32 * 612 * 10^6 (19.6 млрд) |
| Билинейных фильтраций одноканальных FP32 в секунду | — | 16 * 825 * 10^6 (13.2 млрд) | 16 * 612 * 10^6 (9.8 млрд) |
Хотя R600 значительно отстаёт от G80 по мощности текстурных блоков, в его пользу выступают более крупные кеши, повышенная тактовая частота, а также менее жёсткая привязанность текстурных блоков к конкретным шейдерным процессорам.
Но всё же R600 является заметным шагом вперёд по сравнению с R580+.
Судя по предварительным данным, Fetch4 будет включена в состав DirectX 10.1 под названием Gather4. В отличие от PCF, уже включенной в состав DX 10, это позволит напрямую передавать неотфильтрованные тексели одноканальных текстур блокам АЛУ (PCF передаёт блокам АЛУ только отфильтрованный результат). Начиная с RV530, продукты AMD уже поддерживают Fetch4, а компании nVidia придётся изменить их текстурные блоки для поддержки этой технологии.
Краткий глоссарий некоторых терминов, использованных в статье
Блоки текстурирования (TMU)




![]()
![]()
Эти блоки GPU работают совместно с вычислительными процессорами, ими осуществляется выборка и фильтрация текстурных и прочих данных, необходимых для построения сцены и универсальных вычислений. Число текстурных блоков в видеочипе определяет текстурную производительность — то есть скорость выборки текселей из текстур.
Хотя в последнее время больший упор делается на математические расчеты, а часть текстур заменяется процедурными, нагрузка на блоки TMU и сейчас довольно велика, так как кроме основных текстур, выборки необходимо делать и из карт нормалей и смещений, а также внеэкранных буферов рендеринга render target.
С учётом упора многих игр в том числе и в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность также являются одними из важнейших параметров для видеочипов. Особенное влияние этот параметр оказывает на скорость рендеринга картинки при использовании анизотропной фильтрации, требующие дополнительных текстурных выборок, а также при сложных алгоритмах мягких теней и новомодных алгоритмах вроде Screen Space Ambient Occlusion.
Блоки операций растеризации (ROP)
Блоки растеризации осуществляют операции записи рассчитанных видеокартой пикселей в буферы и операции их смешивания (блендинга). Как мы уже отмечали выше, производительность блоков ROP влияет на филлрейт и это — одна из основных характеристик видеокарт всех времён. И хотя в последнее время её значение также несколько снизилось, всё ещё попадаются случаи, когда производительность приложений зависит от скорости и количества блоков ROP. Чаще всего это объясняется активным использованием фильтров постобработки и включенным антиалиасингом при высоких игровых настройках.
Ещё раз отметим, что современные видеочипы нельзя оценивать только числом разнообразных блоков и их частотой. Каждая серия GPU использует новую архитектуру, в которой исполнительные блоки сильно отличаются от старых, да и соотношение количества разных блоков может отличаться. Так, блоки ROP компании AMD в некоторых решениях могут выполнять за такт больше работы, чем блоки в решениях NVIDIA, и наоборот. То же самое касается и способностей текстурных блоков TMU — они разные в разных поколениях GPU разных производителей, и это нужно учитывать при сравнении.
FAQ по видеокартам GeForce: что следует знать о графических картах?
Страница 4: GPU
Что скрывается за потоковым процессором, блоком шейдеров или ядром CUDA?
Потоковый процессор обрабатывает непрерывный поток данных, которых насчитываются многие сотни, причем они выполняются параллельно на множестве потоковых процессоров. Современные GPU оснащаются несколькими тысячами потоковых процессоров, они отлично подходят для задач с высокой степенью параллельности. Это и рендеринг графики, и научные расчеты. Что, кстати, позволило GPU закрепиться в серверном сегменте в качестве вычислительных ускорителей.

Еще одним шагом дальше можно назвать интеграцию ядер Tensor в архитектуру NVIDIA Ampere, которые способны эффективно вычислять менее сложные числа INT8 и INT4, но об этом мы поговорим чуть позже.
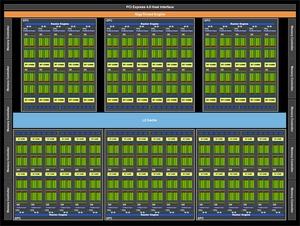
В составе GPU GA102 имеются семь кластеров Graphics Processing Clusters (GPC) с 12 потоковыми мультипроцессорами Streaming Multiprocessors (SM) каждый. Но на видеокартах GeForce RTX 3090 и GeForce RTX 3080 активны не все SM. GA102 GPU теоретически содержит 10.752 блоков FP32 (7 GPC x 12 SM x 128 блоков FP32). Но у GeForce RTX 3090 два SM отключены, поэтому видеокарта предлагает «всего» 10.496 блоков FP32. Такой подход повышает выход годных чипов NVIDIA, поскольку наличие одного-двух дефектных SM не приводит к отбраковке кристалла.
В случае GeForce RTX 3080 один кластер GPC полностью отключен, поэтому на GA102 GPU остаются шесть GPC, но только четыре из них содержат полные 12 SM, два ограничены десятью SM. Что дает в сумме 8.704 блока FP32 в составе 68 SM.
NVIDIA масштабирует архитектуру Ampere с видеокарты GeForce RTX 3060 вплоть до GeForce RTX 3090. Ниже представлен обзор видеокарт GeForce RTX 30:
| GeForce RTX 3090 | GeForce RTX 3080 Ti | GeForce RTX 3080 | GeForce RTX 3070 Ti | |
| GPU | Ampere (GA102) | Ampere (GA102) | Ampere (GA102) | Ampere (GA104) |
| Число транзисторов | 28 млрд. | 28 млрд. | 28 млрд. | 17,4 млрд. |
| Техпроцесс | 8 нм | 8 нм | 8 нм | 8 нм |
| Площадь кристалла | 628,4 мм² | 628,4 мм² | 628,4 мм² | 392,5 мм² |
| Число FP32 ALU | 10.496 | 10.240 | 8.704 | 6.144 |
| Число INT32 ALU | 5.248 | 5.120 | 4.352 | 3.072 |
| Число SM | 82 | 80 | 68 | 48 |
| Ядра Tensor | 328 | 320 | 272 | 192 |
| Ядра RT | 82 | 80 | 68 | 48 |
| Базовая частота | 1.400 МГц | 1.365 МГц | 1.440 МГц | 1.580 МГц |
| Частота Boost | 1.700 МГц | 1.665 МГц | 1.710 МГц | 1.770 МГц |
| Емкость памяти | 24 GB | 12 GB | 10 GB | 8 GB |
| Тип памяти | GDDR6X | GDDR6X | GDDR6X | GDDR6X |
| Частота памяти | 1.219 МГц | 1.188 МГц | 1.188 МГц | 1.188 МГц |
| Ширина шины памяти | 384 бит | 384 бит | 320 бит | 256 бит |
| Пропускная способность памяти | 936 Гбайт/с | 912 Гбайт/с | 760 Гбайт/с | 608 Гбайт/с |
| TDP | 350 Вт | 350 Вт | 320 Вт | 290 Вт |
| GeForce RTX 3070 | GeForce RTX 3060 Ti | GeForce RTX 3060 | |
| GPU | Ampere (GA104) | Ampere (GA104) | Ampere (GA106) |
| Число транзисторов | 17,4 млрд. | 17,4 млрд. | 12 млрд. |
| Техпроцесс | 8 нм | 8 нм | 8 нм |
| Площадь кристалла | 392,5 мм² | 392,5 мм² | 276 мм² |
| Число FP32 ALU | 5.888 | 4.864 | 3.584 |
| Число INT32 ALU | 2.944 | 2.432 | 1.792 |
| Число SM | 46 | 38 | 28 |
| Ядра Tensor | 184 | 152 | 112 |
| Ядра RT | 46 | 38 | 28 |
| Базовая частота | 1.500 МГц | 1.410 МГц | 1.320 МГц |
| Частота Boost | 1.730 МГц | 1.665 МГц | 1.780 МГц |
| Емкость памяти | 8 GB | 8 GB | 12 GB |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти | 1.725 МГц | 1.750 МГц | 1.875 МГц |
| Ширина шины памяти | 256 бит | 256 бит | 192 бит |
| Пропускная способность памяти | 448 Гбайт/с | 448 Гбайт/с | 360 Гбайт/с |
| TDP | 220 Вт | 200 Вт | 170 Вт |
Одновременное выполнение операций с целыми числами и числами с плавающей запятой
Как мы уже упоминали, вычислительные блоки FP32 могут работать в режиме 2x FP16, то же самое касается INT16. Чтобы увеличить вычислительную производительность и сделать ее более гибкой, в архитектуре NVIDIA Turing появилась возможность одновременного расчета чисел с плавающей запятой и целых чисел. Конечно, подобная возможность сохранилась и в архитектуре Ampere. NVIDIA проанализировала данные вычисления в конвейере рендеринга в десятках игр, обнаружив, что на каждые 100 расчетов FP выполняется примерно треть вычислений INT. Впрочем, значение среднее, на практике оно меняется от 20% до 50%. Конечно, если вычисления FP и INT будут выполняться одновременно, то конвейеру придется иногда «подтормаживать» в случае взаимных связей.

Соотношение 1/3 INT32 и 2/3 FP32 отражено в структуре Ampere Streaming Multiprocessor (SM), составляющем элементе архитектуры Ampere. NVIDIA удвоила число вычислительных блоков FP32 на каждый SM. Вместо 64 блоков FP32 на SM, их теперь насчитывается 128. Плюс 64 блока INT32. Теперь на квадрант SM насчитывается два пути данных, некоторые могут работать параллельно. Один из путей данных содержит 16 блоков FP32, то есть может выполнять 16 вычислений FP32 за такт. Второй путь данных содержит по 16 блоков FP32 и INT32. Каждый из квадрантов SM может выполнять либо 32 операции FP32, либо по 16 операций FP32 и INT32 за такт. Если же брать SM целиком, то возможно выполнение 128 операций FP32 или по 64 операции FP32 и INT32 за такт.
Параллельное выполнение продолжается и на других блоках. Например, ядра RT и Tensor могут работать параллельно в конвейере рендеринга, что снижает время, требующееся на рендеринг кадра.
Под термином «потоковые процессоры» сегодня подразумевают количество вычислительных блоков GPU, хотя следует помнить, что сложность вычислений бывает разной. Поэтому термин используется гибко, но обычно все равно описывает вычислительные блоки.
Текстурные блоки
Действительно, для рендеринга объекта простых текстур уже недостаточно, использование нескольких слоев позволяет, например, получить 3D-эффект вместо плоской текстуры. Раньше объекты приходилось рассчитывать на конвейере несколько раз, и каждый проход текстурный блок накладывал текстуру, сегодня достаточно одного процесса рендеринга, текстурный блок может получать данные объекта для многократной обработки из буфера.
Контроллер памяти
Помимо изменений в SM, новая архитектура NVIDIA получила оптимизированную структуру конвейеров растровых операций (ROP), а также соединения ROP и контроллера памяти. До поколения Turing ROP всегда подключались к интерфейсу памяти. И на каждый 32-битный контроллер памяти приходилось восемь ROP. Если число контроллеров памяти и ширина шины менялись, то же самое касалось и ROP. В архитектуре Ampere ROP перенесены в GPC. Используются два раздела ROP на GPC, каждый раздел содержит восемь ROP.
Что дает иную формулу вычисления ROP на GeForce RTX 3080. Шесть GPC с 2x 8 ROP на каждом дают 96 ROP. У GeForce RTX 3090 работают семь GPC с 2x 8 ROP, что дает 112 ROP. NVIDIA намеренно интегрировала ROP глубже, чтобы задняя часть конвейера рендеринга меньше зависела от интерфейса памяти. Например, видеокарта GeForce RTX 3080 использует 320-битный интерфейс памяти, но содержит 96 ROP, а не 80 ROP.
Интерфейс памяти разделен на 32-битные блоки. В зависимости от желаемой ширины интерфейса памяти или емкости, их можно набирать в произвольном количестве.
Ядра Tensor и RT
Ядра Tensor третьего поколения
С архитектурой Turing NVIDIA представила два новых вычислительных блока, ранее на GPU не использовавшихся. Конечно, ядра Tensor знакомы нам по архитектуре Volta, но там они использовались для научных расчетов. В случае GPU Ampere ядра Tensor перешли уже на третье поколение.
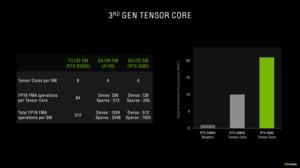
Ядра Tensor ранее использовались только для вычислений INT16 и FP16, но в третьем поколении они могут работать с FP32 и FP64. Что особенно важно для сегмента HPC с высокой точностью. Для игровых GPU GeForce намного важнее меньшая точность.
Ядра Tensor архитектуры Turing могут выполнять 64 операции FP16 Fused Multiply-Add (FMA) каждое. В случае Ampere число операций увеличено до 128 у GA102 GPU и до 256 у GA100 GPU с плотными матрицами. Если же используются разреженные матрицы, число операций FMA FP16 увеличивается до 256 у GA102 GPU и до 512 у GA100 GPU. Ядра Tensor архитектуры Turing разреженные матрицы не поддерживают.
Ядра RT второго поколения
Все они опираются на тот принцип, что удаленные от луча примитивы не могут с ним пересекаться. Следовательно, и смысла их просчитывать нет. Число лучей на сценах растет экспоненциально, поэтому на каждый луч следует обрабатывать как можно меньшее число примитивов, чтобы не увеличивать вычислительную нагрузку.
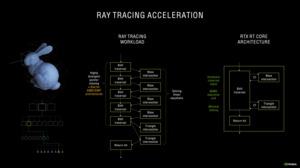
Поскольку NVIDIA не изменила число ядер RT на SM в архитектуре Ampere, количество блоков SM на GPU по-прежнему определяет производительность RT. Но в ядрах RT есть другие оптимизации.
Одна из проблем с расчетом пересечений при трассировке лучей связана с движущимися объектами, особенно если используется эффект размытия движения (motion blur). Для ядер RT в архитектуре Turing такой сценарий является «узким местом». Но второе поколение ядер RT уже лучше справляется с интерполяцией эффекта размытия движения. Пересечения просчитываются с упреждением, в итоге трассировка лучей рассчитываются только для тех областей, где она необходима.
Кэши L1 и L2
Между функциональными блоками (потоковые процессоры, ядра RT и Tensor) и видеопамятью располагаются еще два уровня хранения данных, без которых GPU не смог бы выдавать высокий уровень производительности. Цель этих кэшей заключается в том, чтобы хранить информацию как можно ближе к функциональным блокам. Данные передаются из видеопамяти сначала в кэш L2, а затем и в кэш L1.
NVIDIA с архитектурой Ampere вновь увеличила кэш L1 с 96 до 128 кбайт. Скорость работы L1 была вновь удвоена. NVIDIA реализовала такую же меру ранее при переходе с Pascal на Turing. Число 32-битных регистров не изменилось и осталось на уровне 16.384. То же самое касается числа блоков чтения/записи.
