Значение эпохи в обучении нейронных сетей
пока я читаю в how to build ANN in pybrain, говорят:
Тренируйте сеть для некоторых эпох. Обычно вы устанавливаете что-то как 5 здесь,
Я знаком с онлайн-обучением, где wights обновляются после каждого образца данных или вектора объектов, мой вопрос заключается в том, как убедиться, что 5 эпох будет достаточно для построения модели и установки весов, вероятно? в чем преимущество такого способа онлайн-обучения? Также термин «эпоха» используется в онлайн-обучении, означает ли это один вектор признаков?
3 ответов
Это не имеет ничего общего с пакетным или онлайн-обучением как таковым. Пакетный означает, что вы обновляете после в конце эпохи (после каждый образец виден, т. е. обновления # epoch) и онлайн, которые вы обновляете после каждого пример (#samples * #epoch updates).
вы не можете быть уверены, достаточно ли 5 эпох или 500 для конвергенции, поскольку она будет варьироваться от данных к данным. Вы можете прекратить обучение, когда ошибка сходится или становится ниже определенного порога. Это также входит в сферу предотвращения переоснащения. Вы можете прочитать на в начале остановки и перекрестная проверка о том, что.
эпоха составляет один раз и один обратный пас of все тренировочные примеры.
Примечание: эпоха и итерации-это два разные вещи.
например, для набора из 1000 изображений и размера пакета 10 каждая итерация будет обрабатывать 10 изображений в общей сложности 100 таких итераций для всего набора. Это называется одной эпохи. Обучение может продолжаться в течение 100 эпох.
извините за повторную активацию этого потока. я новичок в нейронных сетях и исследую влияние «мини-пакетного» обучения.
насколько я понимаю, эпоха (как говорит рундосрун) является сквозным использованием всех в TrainingSet (не DataSet. потому что DataSet = TrainingSet + ValidationSet). в мини-пакетном обучении вы можете разделить TrainingSet на небольшие наборы и обновить веса внутри эпохи. «надеюсь», это заставит сеть «сходиться» быстрее.
некоторые определения нейронных сетей устарели и, я думаю, должны быть переопределены.
В чем разница между партией и эпохой в нейронной сети?
Дата публикации 2018-07-20
В этом посте вы обнаружите разницу между партиями и эпохами в стохастическом градиентном спуске.
Прочитав этот пост, вы узнаете:

обзор
Этот пост разделен на пять частей; они есть:
Стохастический градиентный спуск
Задача алгоритма состоит в том, чтобы найти набор внутренних параметров модели, которые хорошо работают против некоторого показателя производительности, такого как логарифмическая потеря или среднеквадратическая ошибка.
Алгоритм является итеративным. Это означает, что процесс поиска происходит в несколько отдельных этапов, каждый шаг, мы надеемся, немного улучшает параметры модели.
Каждый шаг включает использование модели с текущим набором внутренних параметров для прогнозирования некоторых выборок, сравнение прогнозов с реальными ожидаемыми результатами, вычисление ошибки и использование ошибки для обновления внутренних параметров модели.
Эта процедура обновления отличается для разных алгоритмов, но в случае искусственных нейронных сетейобратное распространениеалгоритм обновления используется.
Прежде чем мы погрузимся в партии и эпохи, давайте взглянем на то, что мы подразумеваем под образцом.
Узнайте больше о градиентном спуске здесь:
Что такое образец?
Образец представляет собой одну строку данных.
Он содержит входные данные, которые вводятся в алгоритм, и выходные данные, которые используются для сравнения с прогнозом и вычисления ошибки.
Обучающий набор данных состоит из множества строк данных, например, много образцов. Образец также может называться экземпляром, наблюдением, входным вектором или вектором признаков.
Теперь, когда мы знаем, что такое образец, давайте определим партию.
Что такое партия?
Думайте о пакете как о цикле for, повторяющем одну или несколько выборок и делающем прогнозы. В конце пакета прогнозы сравниваются с ожидаемыми выходными переменными, и вычисляется ошибка. Исходя из этой ошибки, алгоритм обновления используется для улучшения модели, например, двигаться вниз по градиенту ошибки.
Набор обучающих данных может быть разделен на одну или несколько партий.
Когда все обучающие образцы используются для создания одной партии, алгоритм обучения называется спуском градиента партии. Когда размер пакета составляет одну выборку, алгоритм обучения называется стохастическим градиентным спуском. Когда размер пакета больше, чем одна выборка и меньше, чем размер обучающего набора данных, алгоритм обучения называется спуском градиента мини-пакета.
В случае мини-пакетного градиентного спуска популярные размеры партии включают 32, 64 и 128 образцов. Вы можете увидеть эти значения, используемые в моделях в литературе и учебниках.
Что если набор данных не делится равномерно по размеру пакета?
Это может случаться и часто случается при обучении модели. Это просто означает, что в последней партии меньше образцов, чем в других партиях.
Кроме того, вы можете удалить некоторые выборки из набора данных или изменить размер пакета так, чтобы количество выборок в наборе данных делилось равномерно на размер пакета.
Подробнее о различиях между этими вариациями градиентного спуска читайте в посте:
Пакет включает обновление модели с использованием образцов; Далее, давайте посмотрим на эпоху.
Что такое эпоха?
Одна эпоха означает, что у каждой выборки в наборе обучающих данных была возможность обновить внутренние параметры модели. Эпоха состоит из одной или нескольких партий. Например, как указано выше, эпоха, в которой есть одна партия, называется алгоритмом обучения пакетного градиентного спуска.
Вы можете придумать цикл for для числа эпох, где каждый цикл проходит через набор обучающих данных. В этом цикле for находится еще один вложенный цикл for, который выполняет итерацию для каждой партии выборок, где одна партия имеет указанное количество выборок «размера партии».
Количество эпох традиционно велико, часто сотни или тысячи, что позволяет алгоритму обучения работать до тех пор, пока ошибка модели не будет сведена к минимуму. Вы можете увидеть примеры количества эпох в литературе и в учебных пособиях 10, 100, 500, 1000 и более.
Обычно создаются линейные графики, которые показывают эпохи вдоль оси X как время и ошибку или навык модели на оси Y. Эти графики иногда называют кривыми обучения. Эти графики могут помочь диагностировать, является ли модель переученной, недостаточно изученной или подходит ли она для набора данных обучения.
Подробнее о диагностике с помощью кривых обучения в сетях LSTM см. Пост:
Если это все еще не ясно, давайте посмотрим на различия между партиями и эпохами.
В чем разница между партией и эпохой?
Размер партии должен быть больше или равен одному и меньше или равен количеству выборок в наборе обучающих данных.
Количество эпох может быть установлено в целочисленное значение от одного до бесконечности. Вы можете запускать алгоритм сколько угодно и даже останавливать его, используя другие критерии, помимо фиксированного количества эпох, таких как изменение (или отсутствие изменения) ошибки модели со временем.
Они оба являются целочисленными значениями и являются гиперпараметрами для алгоритма обучения, например параметры для процесса обучения, а не внутренние параметры модели, найденные в процессе обучения.
Вы должны указать размер пакета и количество эпох для алгоритма обучения.
Не существует волшебных правил для настройки этих параметров. Вы должны попробовать разные значения и посмотреть, что лучше всего подходит для вашей проблемы.
Работал Пример
Наконец, давайте сделаем это с небольшим примером.
Предположим, у вас есть набор данных с 200 выборками (строками данных), и вы выбираете размер пакета 5 и 1000 эпох.
Это означает, что набор данных будет разделен на 40 партий, каждая с пятью выборками. Вес модели будет обновляться после каждой партии из пяти образцов.
Это также означает, что одна эпоха будет включать 40 партий или 40 обновлений модели.
При 1000 эпохах модель будет экспонироваться или проходить через весь набор данных 1000 раз. Это всего 40 000 партий за весь учебный процесс.
Дальнейшее чтение
Этот раздел предоставляет больше ресурсов по теме, если вы хотите углубиться.
Резюме
В этом посте вы обнаружили разницу между партиями и эпохами в стохастическом градиентном спуске.
В частности, вы узнали:
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Методы классификации и прогнозирования. Нейронные сети
Обучение нейронных сетей
Перед использованием нейронной сети ее необходимо обучить.
Процесс обучения нейронной сети заключается в подстройке ее внутренних параметров под конкретную задачу.
Алгоритм работы нейронной сети является итеративным, его шаги называют эпохами или циклами.
Процесс обучения осуществляется на обучающей выборке.
Обучающая выборка включает входные значения и соответствующие им выходные значения набора данных. В ходе обучения нейронная сеть находит некие зависимости выходных полей от входных.
Сложность может вызвать вопрос о количестве наблюдений в наборе данных. И хотя существуют некие правила, описывающие связь между необходимым количеством наблюдений и размером сети, их верность не доказана.
С помощью функции ошибок можно оценить качество работы нейронной сети во время обучения. Например, часто используется сумма квадратов ошибок.
От качества обучения нейронной сети зависит ее способность решать поставленные перед ней задачи.
Переобучение нейронной сети
При обучении нейронных сетей часто возникает серьезная трудность, называемая проблемой переобучения (overfitting).
Описанный процесс проиллюстрирован на рис. 11.2.

На первом шаге ошибки прогноза для обучающего и тестового множества одинаковы. На последующих шагах значения обеих ошибок уменьшаются, однако с семидесятого шага ошибка на тестовом множестве начинает возрастать, т.е. начинается процесс переобучения сети.
Прогноз на тестовом множестве является проверкой работоспособности построенной модели. Ошибка на тестовом множестве может являться ошибкой прогноза, если тестовое множество максимально приближено к текущему моменту.
Эпоха, батч, итерация — в чем различия?
Вам должны быть знакомы моменты, когда вы смотрите на код и удивляетесь: “Почему я использую в коде эти три параметра, в чем отличие между ними?”. И это неспроста, так как параметры выглядят очень похожими.
Чтобы выяснить разницу между этими параметрами, требуется понимание простых понятий, таких как градиентный спуск.
Градиентный спуск
Это ни что иное, как алгоритм итеративной оптимизации, используемый в машинном обучении для получения более точного результата (то есть поиск минимума кривой или многомерной поверхности).
Градиент показывает скорость убывания или возрастания функции.
Спуск говорит о том, что мы имеем дело с убыванием.
Алгоритм итеративный, процедура проводится несколько раз, чтобы добиться оптимального результата. При правильной реализации алгоритма, на каждом шаге результат получается лучше. Таким образом, итеративный характер градиентного спуска помогает плохо обученной модели оптимально подстроиться под данные.
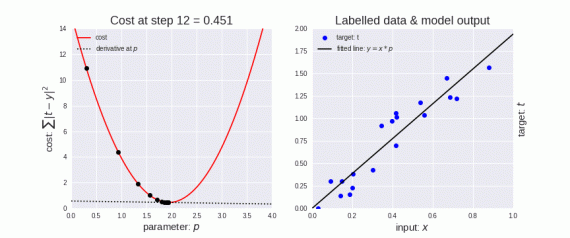
У градиентного спуска есть параметр, называемый скоростью обучения. На левой верхней картинке видно, что в самом начале шаги больше, то есть скорость обучения выше, а по мере приближения точек к краю кривой скорость обучения становится меньше благодаря уменьшению размера шагов. Кроме того, значение функции потерь (Cost function) уменьшается, или просто говорят, что потери уменьшаются. Часто люди называют функцию потерь Loss-функцией или просто «Лосс». Важно, что если Cost/Loss функция уменьшается, то это хорошо.
Как происходит обучение сети
Исследователи работают с гиганскими объемами данных, которые требуют соответствующих затрат ресурсов и времени. Чтобы эффективно работать с большими объемами данных, требуется использовать параметры (epoch, batch size, итерации), так как зачастую нет возможности загрузить сразу все данные в обработку.
Для преодоления этой проблемы, данные делят на части меньшего размера, загружают их по очереди и обновляют веса нейросети в конце каждого шага, подстраивая их под данные.
Epochs
Произошла одна эпоха (epoch) — весь датасет прошел через нейронную сеть в прямом и обратном направлении только один раз.
Так как одна epoch слишком велика для компьютера, датасет делят на маленькие партии (batches).
Почему мы используем более одной эпохи
Вначале не понятно, почему недостаточно одного полного прохода датасета через нейронную сеть, и почему необходимо пускать полный датасет по сети несколько раз.
Нужно помнить, что мы используем ограниченный датасет, чтобы оптимизировать обучение и подстроить кривую под данные. Делается это с помощью градиентного спуска — итеративного процесса. Поэтому обновления весов после одного прохождения недостаточно.
Одна эпоха приводит к недообучению, а избыток эпох — к переобучению:
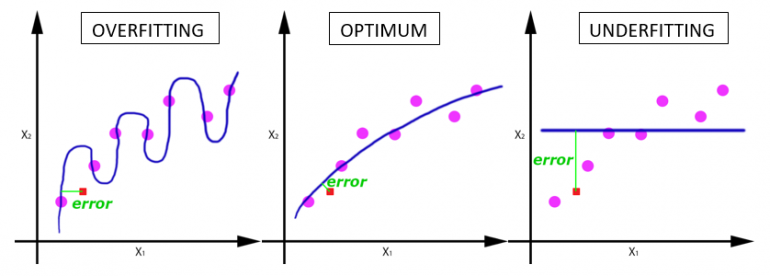
С увеличением числа эпох, веса нейронной сети изменяются все большее количество раз. Кривая с каждый разом лучше подстраивается под данные, переходя последовательно из плохо обученного состояния (последний график) в оптимальное (центральный график). Если вовремя не остановиться, то может произойти переобучение (первый график) — когда кривая очень точно подстроилась под точки, а обобщающая способность исчезла.
Какое количество эпох правильное?
На этот вопрос нет единственного точного ответа. Для различных датасетов оптимальное количество эпох будет отличаться. Но ясно, что количество эпох связано с разнообразием в данных. Например, в вашем датасете присутствуют только черные котики? Или это более разнообразный датасет?
Batch Size
Общее число тренировочных объектов, представленных в одном батче.
Отметим: Размер батча и число батчей — два разных параметра.
Что такое батч?
Нельзя пропустить через нейронную сеть разом весь датасет. Поэтому делим данные на пакеты, сеты или партии, так же, как большая статья делится на много разделов — введение, градиентный спуск, эпохи, Batch size и итерации. Такое разбиение позволяет легче прочитать и понять статью.
Итерации
Итерации — число батчей, необходимых для завершения одной эпохи.
Отметим: Число батчей равно числу итераций для одной эпохи.
Например, собираемся использовать 2000 тренировочных объектов.
Можно разделить полный датасет из 2000 объектов на батчи размером 500 объектов. Таким образом, для завершения одной эпохи потребуется 4 итерации.
Эпоха против итерации при обучении нейронных сетей
В чем разница между эпохой и итерацией при обучении многослойного персептрона?
В терминологии нейронной сети:
Пример: если у вас 1000 обучающих примеров, а размер пакета равен 500, то для завершения 1 эпохи потребуется 2 итерации.
Эпоха и итерация описывают разные вещи.
эпоха
Эпоха описывает количество раз алгоритм видит весь набор данных. Итак, каждый раз, когда алгоритм просматривал все выборки в наборе данных, эпоха завершалась.
итерация
пример
Пример может сделать это более понятным.
Скажем, у вас есть набор данных из 10 примеров (или образцов). У вас есть размер пакета 2, и вы указали, что хотите, чтобы алгоритм работал в течение 3 эпох.
Поэтому в каждой эпохе у вас есть 5 партий (10/2 = 5). Каждая партия проходит через алгоритм, поэтому у вас есть 5 итераций за эпоху. Поскольку вы указали 3 эпохи, у вас есть всего 15 итераций (5 * 3 = 15) для обучения.
Многие алгоритмы обучения нейронной сети предполагают создание нескольких представлений всего набора данных в нейронной сети. Часто одно представление всего набора данных называется «эпохой». Напротив, некоторые алгоритмы представляют данные нейронной сети по одному случаю за раз.
Прежде чем я начну с фактического ответа, я хотел бы создать некоторый фон.
В случае Пакетного градиентного спуска вся партия обрабатывается на каждом тренировочном проходе. Следовательно, оптимизатор градиентного спуска обеспечивает более плавную сходимость, чем мини-пакетный градиентный спуск, но это занимает больше времени. Пакетный градиентный спуск гарантированно найдет оптимальный, если он существует.


У вас есть тренировочные данные, которые вы перемешиваете и выбираете из них мини-партии. Когда вы корректируете свои веса и смещения с помощью одной мини-партии, вы выполняете одну итерацию. Как только вы исчерпали свои мини-партии, вы завершили эпоху. Затем вы снова перетасовываете свои тренировочные данные, снова выбираете свои мини-партии и снова просматриваете их все. Это будет ваша вторая эпоха.
An эпоха соответствует всей подготовки пущен по всей сети один раз. Это может быть полезно для ограничения этого, например, для борьбы с переоснащением.
Эпоха содержит несколько итераций. Вот на самом деле, что это за «эпоха». Давайте определим «эпоху» как количество итераций по набору данных для обучения нейронной сети.
Насколько я понимаю, когда вам нужно обучить NN, вам нужен большой набор данных, включающий много элементов данных. когда NN обучается, элементы данных поступают в NN один за другим, что называется итерацией; Когда весь набор данных проходит, это называется эпохой.
Я полагаю, что итерация эквивалентна единственной партии вперед + backprop в партии SGD. Эпоха проходит через весь набор данных один раз (как кто-то еще упомянул).
Я думаю, в контексте терминологии нейронной сети:
Чтобы определить итерацию (иначе говоря, шаги ), вам сначала нужно знать размер пакета :
Итерация: (так называемые этапы обучения) Вы знаете, что ваша сеть должна пройти все обучающие экземпляры за один проход, чтобы завершить одну эпоху. Но ждать! когда вы разбиваете свои обучающие экземпляры на партии, это означает, что вы можете обрабатывать только одну партию (подмножество обучающих экземпляров) за один прямой проход, так что же делать с другими партиями? Это где термин Итерация вступает в игру:
Например, когда у вас есть 1000 обучающих экземпляров, и вы хотите выполнить дозирование размером 10; Вы должны сделать 10000/10 = 1000 итераций, чтобы завершить одну эпоху.
Надеюсь, что это может ответить на ваш вопрос!
